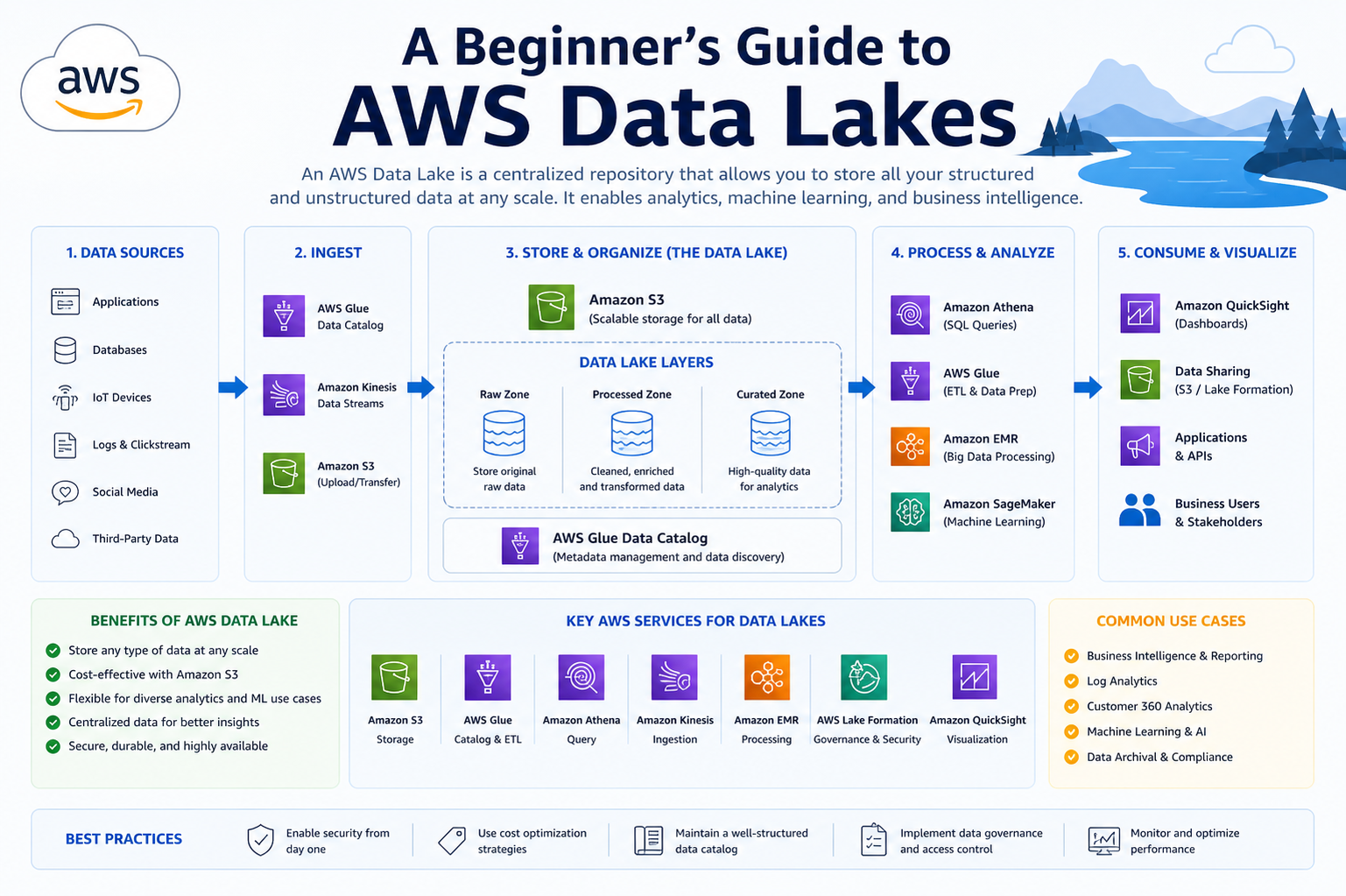
Building on the basics, an AWS data lake becomes more powerful as organizations refine how data is collected, stored, and accessed. A well-architected data lake is not just about dumping large volumes of information into storage; it is about creating a system where data remains discoverable, reliable, and ready for analysis at any time. This requires a thoughtful combination of storage strategies, metadata management, and performance optimization. By designing the foundation carefully, businesses can ensure that their data lake continues to deliver value as it scales.
Data Ingestion Strategies
One of the most critical aspects of a data lake is how data enters the system. Amazon Web Services supports multiple ingestion methods, including batch processing and real-time streaming. Batch ingestion is suitable for large datasets that are transferred at scheduled intervals, such as daily transaction records or historical archives. On the other hand, streaming ingestion allows organizations to capture real-time data from sources like IoT devices, application logs, and user activity feeds. Choosing the right ingestion strategy depends on business requirements, latency tolerance, and the nature of the data sources.
Batch vs Real-Time Processing
Batch processing focuses on handling large volumes of data at once, often using scheduled jobs. This approach is efficient and cost-effective for workloads that do not require immediate results. Real-time processing, however, enables instant analysis and decision-making by continuously processing incoming data streams. AWS data lakes support both approaches, allowing organizations to combine them for hybrid architectures. This flexibility ensures that businesses can meet both operational and analytical needs without compromising performance.
Data Storage Best Practices
Storage plays a central role in the success of a data lake. Using Amazon S3 as the primary storage layer allows organizations to store virtually unlimited data with high durability. However, simply storing data is not enough. Structuring data into logical folders or partitions improves accessibility and query performance. Organizing data by attributes such as date, region, or category helps reduce processing time and cost when running analytics. Additionally, applying consistent naming conventions ensures that datasets remain easy to locate and manage.
Data Formats and Optimization
Choosing the right data format significantly impacts performance and cost efficiency. Formats such as Parquet and ORC are optimized for analytics because they support columnar storage, which reduces the amount of data scanned during queries. Compressing data further improves storage efficiency and speeds up processing. AWS data lakes benefit from these optimizations by enabling faster query execution and reducing overall resource consumption.
Metadata and Data Cataloging
Metadata provides context to the raw data stored in a data lake. Without proper metadata management, finding and understanding datasets becomes challenging. AWS offers cataloging tools that allow users to define schemas, track data lineage, and maintain a searchable inventory of available datasets. A well-maintained data catalog acts as a bridge between raw data and meaningful insights, enabling analysts and data scientists to quickly locate the information they need.
Data Governance and Security
Governance is essential to ensure that data remains accurate, secure, and compliant with regulations. AWS data lakes provide fine-grained access controls, allowing organizations to define who can view, modify, or analyze specific datasets. Encryption protects data both at rest and in transit, safeguarding sensitive information. Implementing governance policies early helps maintain data quality and prevents the environment from becoming disorganized or difficult to manage.
Advanced Data Processing in AWS Data Lakes
As organizations mature in their use of data lakes, the focus shifts from simple storage to advanced data processing capabilities. Processing is what transforms raw data into meaningful insights. In an AWS data lake, this involves cleaning, enriching, and structuring data so it can be used effectively by analysts and applications. Processing workflows can be automated and scaled depending on the volume and complexity of data, ensuring consistent results while reducing manual effort. By implementing strong processing pipelines, organizations can turn their data lake into a powerful analytics engine.
Data Transformation Techniques
Raw data is rarely ready for analysis in its original form. It often contains inconsistencies, missing values, or irrelevant information. Data transformation involves cleaning and reshaping this data to make it usable. Common techniques include filtering unwanted records, standardizing formats, and joining datasets from multiple sources. These transformations can be applied during ingestion or after the data is stored. In AWS data lakes, transformation processes are typically designed to be repeatable and scalable, ensuring that data remains consistent across different use cases.
ETL vs ELT Approaches
Two common approaches to data processing are ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform). ETL involves transforming data before loading it into the data lake or warehouse, while ELT loads raw data first and performs transformations later. AWS data lakes often favor the ELT approach because it allows organizations to retain raw data for future use. This flexibility makes it easier to apply different transformations depending on evolving business requirements. Both approaches have their advantages, and the choice depends on performance needs, data complexity, and governance requirements.
Querying Data in AWS Data Lakes
Once data is processed and organized, it becomes ready for querying. AWS provides powerful query engines that allow users to analyze large datasets without moving them from storage. These tools enable users to run SQL queries directly on data stored in the lake. Efficient querying depends on proper data organization, partitioning, and format selection. By optimizing these elements, organizations can significantly reduce query time and cost while improving the overall user experience.
Data Warehousing Integration
Data lakes and data warehouses often work together rather than replacing each other. A data lake stores raw and diverse datasets, while a data warehouse focuses on structured, high-performance analytics. AWS allows seamless integration between these systems, enabling organizations to move processed data into a warehouse for advanced reporting and business intelligence. This hybrid approach combines the flexibility of a data lake with the performance of a data warehouse, offering the best of both worlds.
Machine Learning and AI Capabilities
One of the most powerful uses of AWS data lakes is in machine learning and artificial intelligence. By providing access to large volumes of diverse data, data lakes create the perfect environment for training predictive models. Data scientists can experiment with different algorithms and datasets to build models that identify patterns, forecast trends, and automate decision-making. AWS offers tools that integrate directly with data lakes, making it easier to develop, train, and deploy machine learning models at scale.
Data Visualization and Reporting
Data visualization is essential for making insights understandable and actionable. AWS data lakes support integration with visualization tools that allow users to create dashboards, charts, and reports. These visualizations help stakeholders quickly grasp complex information and make informed decisions. By connecting visualization tools directly to the data lake, organizations can ensure that reports are always based on the most up-to-date data.
Performance Optimization Strategies
As data lakes grow, maintaining performance becomes increasingly important. Optimization strategies include partitioning data, using efficient file formats, and caching frequently accessed datasets. Monitoring query performance and identifying bottlenecks also play a key role in maintaining efficiency. AWS provides tools to track usage and performance metrics, helping organizations continuously improve their data lake environment. Proper optimization not only enhances speed but also reduces operational costs.
Data Lifecycle Management
Managing the lifecycle of data is crucial for controlling costs and maintaining efficiency. Not all data needs to be stored indefinitely in its original form. AWS data lakes allow organizations to define lifecycle policies that automatically move data between storage tiers based on usage patterns. Frequently accessed data can remain in high-performance storage, while older or less critical data can be archived at a lower cost. This approach ensures that resources are used efficiently without sacrificing data availability.
Ensuring Data Quality
Data quality is a critical factor in the success of any data lake. Poor-quality data can lead to inaccurate insights and flawed decision-making. Ensuring data quality involves validating data during ingestion, monitoring for errors, and maintaining consistent standards. Automated validation checks and data profiling techniques help identify issues early, reducing the risk of downstream problems. A strong focus on data quality ensures that the data lake remains a reliable source of information.
Security Best Practices for Advanced Use
As data lakes handle increasingly sensitive and valuable data, security becomes even more important. Advanced security practices include implementing role-based access controls, auditing user activity, and applying encryption across all layers. AWS provides comprehensive security features that help organizations protect their data while maintaining accessibility for authorized users. Regular security reviews and updates ensure that the data lake remains resilient against potential threats.
Scalability and Flexibility
One of the defining characteristics of AWS data lakes is their ability to scale seamlessly. As data volumes grow, organizations can expand their storage and processing capabilities without significant infrastructure changes. This scalability is complemented by flexibility, allowing businesses to adapt their data strategies as requirements evolve. Whether handling small datasets or petabytes of information, AWS data lakes provide the resources needed to support growth and innovation.
Cost Management Strategies
While AWS data lakes are cost-effective, managing expenses is still important. Costs can be controlled by optimizing storage usage, selecting appropriate data formats, and minimizing unnecessary data movement. Monitoring tools provide insights into usage patterns, helping organizations identify areas where costs can be reduced. By implementing cost management strategies, businesses can maximize the value of their data lake while staying within budget.
Collaboration and Data Sharing
Data lakes enable collaboration across teams by providing a centralized platform for data access. Analysts, engineers, and business users can all work with the same datasets, reducing duplication and inconsistencies. AWS supports secure data sharing, allowing organizations to collaborate internally and externally while maintaining control over access permissions. This collaborative environment fosters innovation and accelerates the development of data-driven solutions.
Future Trends in AWS Data Lakes
The evolution of data lakes continues as new technologies and practices emerge. Trends such as serverless computing, real-time analytics, and automated data management are shaping the future of AWS data lakes. These advancements aim to simplify operations, reduce costs, and improve performance. As organizations continue to rely on data for decision-making, AWS data lakes will play an increasingly important role in enabling innovation and competitive advantage.
Building a Mature AWS Data Lake Ecosystem
As organizations progress beyond initial implementation and advanced processing, the next stage is developing a mature and fully integrated data lake ecosystem. This stage focuses on aligning data strategy with business goals, ensuring that every component of the data lake contributes to measurable outcomes. A mature AWS data lake is not just a technical solution; it becomes a strategic asset that supports innovation, forecasting, and long-term decision-making. By continuously refining architecture, governance, and usage patterns, organizations can maximize the value of their data investments.
Data Architecture Evolution
Over time, the architecture of a data lake evolves to support more complex workloads and diverse user groups. Early-stage architectures may focus on centralized storage, but mature systems often adopt layered designs. These layers typically include raw, processed, and curated data zones. Each layer serves a specific purpose, from storing untouched data to providing clean, analytics-ready datasets. This structured approach improves clarity, reduces redundancy, and ensures that users can access the right version of data for their needs without confusion.
Data Mesh and Decentralization Concepts
As data volumes and organizational complexity grow, centralized data management can become a bottleneck. This is where the concept of data mesh comes into play. A data mesh approach distributes ownership of data across different teams or domains, allowing them to manage and share their own datasets. In an AWS environment, this can be achieved by combining centralized governance with decentralized data ownership. This balance enables scalability while maintaining consistency and control across the data lake.
Automation and Orchestration
Automation is a key factor in managing large-scale data lakes efficiently. Manual processes are not sustainable when dealing with massive and continuously growing datasets. AWS data lakes benefit from automated workflows that handle ingestion, transformation, validation, and movement of data. Orchestration ensures that these processes run in the correct sequence and respond to changes in real time. By automating repetitive tasks, organizations can reduce errors, save time, and focus on higher-value activities such as analysis and innovation.
Monitoring and Observability
A mature data lake requires strong monitoring and observability practices to maintain reliability and performance. Monitoring involves tracking system metrics such as storage usage, query performance, and processing times. Observability goes a step further by providing insights into how data flows through the system and where potential issues may arise. AWS provides tools that help organizations detect anomalies, troubleshoot problems, and optimize performance. Continuous monitoring ensures that the data lake remains stable and responsive under varying workloads.
Data Lineage and Traceability
Understanding where data comes from and how it has been transformed is essential in a complex data environment. Data lineage provides a clear record of data origins, transformations, and usage. This transparency is crucial for debugging issues, ensuring compliance, and building trust in data. In AWS data lakes, lineage tracking helps users trace the journey of data from ingestion to final analysis, making it easier to validate results and maintain accountability.
Compliance and Regulatory Considerations
As data regulations become more stringent worldwide, compliance is a critical aspect of data lake management. Organizations must ensure that their data practices align with legal and industry requirements. This includes managing sensitive information, enforcing data retention policies, and maintaining audit trails. AWS provides features that support compliance efforts, but organizations must implement policies and processes that align with their specific regulatory environment. Proactive compliance management reduces risk and protects both the organization and its customers.
Enhancing Data Accessibility
Accessibility is a key goal of any data lake. A mature AWS data lake ensures that users can easily discover, access, and use data without unnecessary barriers. This involves creating user-friendly interfaces, maintaining clear documentation, and providing training for different user groups. By improving accessibility, organizations empower more employees to leverage data in their daily work, fostering a culture of data-driven decision-making.
Integration with Business Applications
To fully realize the value of a data lake, it must integrate seamlessly with business applications and workflows. This includes connecting data to reporting tools, customer relationship management systems, and operational platforms. AWS data lakes support these integrations, enabling real-time or near-real-time data flow between systems. This connectivity ensures that insights generated from the data lake can directly influence business processes and outcomes.
Handling Big Data Challenges
As data lakes grow, they face challenges related to volume, velocity, and variety. Managing these factors requires scalable infrastructure, efficient processing, and robust governance. AWS provides the tools needed to handle big data, but organizations must design their systems carefully to avoid performance bottlenecks and inefficiencies. Addressing these challenges proactively ensures that the data lake remains effective even as demands increase.
Innovation Through Data Lakes
A mature AWS data lake becomes a platform for innovation. By providing access to diverse and high-quality data, it enables experimentation and the development of new products and services. Teams can test hypotheses, build predictive models, and explore new opportunities without being limited by data availability. This innovation-driven approach helps organizations stay competitive and adapt to changing market conditions.
User Roles and Responsibilities
Managing a data lake involves multiple roles, each with specific responsibilities. Data engineers focus on building and maintaining pipelines, while data analysts and scientists use the data for insights and modeling. Governance teams ensure compliance and security, and business users apply insights to decision-making. Clearly defining these roles helps maintain order and efficiency within the data lake environment, ensuring that each stakeholder contributes effectively.
Continuous Improvement and Optimization
A data lake is not a one-time project; it requires ongoing improvement and optimization. Organizations must regularly review their architecture, processes, and performance to identify areas for enhancement. This includes updating technologies, refining workflows, and adapting to new business requirements. Continuous improvement ensures that the data lake remains relevant and valuable over time.
Balancing Flexibility and Control
One of the key challenges in managing a data lake is balancing flexibility with control. While it is important to allow users to explore and experiment with data, there must also be safeguards to prevent misuse and maintain quality. AWS data lakes achieve this balance through a combination of governance policies, access controls, and monitoring tools. This approach ensures that users can innovate while maintaining the integrity and security of the data.
Preparing for the Future of Data
The future of data lakes is shaped by emerging technologies and evolving business needs. Concepts such as real-time analytics, artificial intelligence, and decentralized data management will continue to influence how data lakes are designed and used. AWS remains at the forefront of these developments, providing tools and services that support the next generation of data solutions. Organizations that invest in building and maintaining a strong data lake foundation will be well-positioned to take advantage of future opportunities.
Scaling AWS Data Lakes for Enterprise Growth
As organizations move deeper into data-driven operations, the focus shifts toward scaling the data lake to support enterprise-level demands. At this stage, the data lake must handle massive data volumes, high-velocity streaming inputs, and a growing number of concurrent users without performance degradation. A well-scaled AWS data lake is designed with distributed processing, elastic storage, and optimized query engines that can expand dynamically based on workload requirements. This ensures that as the organization grows, the data infrastructure grows seamlessly alongside it.
High-Performance Data Processing Frameworks
To manage large-scale analytics workloads, organizations rely on distributed processing frameworks integrated with AWS data lakes. These frameworks break large datasets into smaller chunks and process them in parallel across multiple computing resources. This approach significantly reduces processing time and allows complex analytical queries to run efficiently. By leveraging distributed computing, businesses can analyze terabytes or even petabytes of data without bottlenecks, ensuring timely insights for decision-making.
Real-Time Analytics at Scale
Real-time analytics becomes increasingly important as businesses aim to respond instantly to user behavior, market trends, and operational events. AWS data lakes support streaming architectures that process data as it arrives, enabling near-instant insights. This capability is essential for applications such as fraud detection, recommendation systems, and operational monitoring. By combining streaming ingestion with fast processing layers, organizations can achieve continuous intelligence across their systems.
Advanced Data Partitioning Strategies
As datasets grow, efficient data partitioning becomes critical for maintaining query performance. Partitioning involves dividing data into logical segments based on attributes such as time, geography, or category. This reduces the amount of data scanned during queries, improving speed and lowering costs. In large-scale AWS data lakes, well-designed partitioning strategies can significantly enhance performance, especially for frequently accessed datasets. Proper partition design is a key factor in maintaining scalability and efficiency.
Query Optimization Techniques
Query performance plays a major role in user experience and system efficiency. Optimization techniques include minimizing data scans, using indexed metadata, and selecting efficient file formats. Query engines in AWS data lakes are designed to push down filters, meaning they only process relevant portions of data. This reduces resource usage and accelerates response times. Continuous tuning of queries and data structures ensures that performance remains consistent even as data volumes increase.
Multi-Region and Global Data Lakes
For global enterprises, data lakes often span multiple geographic regions. Multi-region architectures improve data availability, reduce latency, and support disaster recovery strategies. By replicating data across regions, organizations ensure that users can access information quickly regardless of location. This global approach also enhances resilience, as data remains accessible even if one region experiences downtime. AWS provides tools that support secure and efficient cross-region data replication.
Disaster Recovery and Business Continuity
A mature data lake must include strong disaster recovery mechanisms to protect against data loss or system failures. This involves regular backups, redundant storage, and automated recovery processes. Business continuity planning ensures that critical data remains accessible even during unexpected disruptions. By implementing robust recovery strategies, organizations can minimize downtime and maintain trust in their data systems.
Cost Optimization at Scale
As data lakes expand, cost management becomes increasingly important. Large-scale storage and processing can lead to significant expenses if not carefully controlled. Cost optimization strategies include tiered storage, lifecycle policies, and selective data retention. Frequently accessed data is kept in high-performance storage, while older or less frequently used data is moved to lower-cost storage tiers. This approach ensures that resources are used efficiently without compromising accessibility.
Data Democratization Across the Organization
A mature AWS data lake enables data democratization, allowing users across different departments to access and analyze data without heavy technical barriers. Self-service analytics tools empower business users to generate insights independently. This reduces reliance on specialized teams and accelerates decision-making across the organization. By democratizing data access, companies foster a culture where insights are available to everyone who needs them.
Advanced Security Architectures
Security becomes more complex as data lakes scale. Advanced security architectures include layered defenses such as encryption, identity management, network isolation, and continuous threat monitoring. Fine-grained access controls ensure that users only access data relevant to their roles. Security policies must evolve alongside the data lake to address new risks and compliance requirements. A strong security foundation protects both data integrity and organizational reputation.
AI-Driven Data Management
Artificial intelligence is increasingly used to enhance data lake management. AI systems can automatically detect anomalies, optimize storage, and suggest performance improvements. They can also assist in data classification and tagging, making it easier to organize large datasets. By integrating AI into data lake operations, organizations reduce manual effort and improve overall system intelligence.
Event-Driven Architectures
Event-driven design plays a key role in modern AWS data lakes. In this model, actions are triggered by specific events such as data uploads, system changes, or user interactions. This allows systems to respond dynamically and efficiently to changing conditions. Event-driven architectures improve responsiveness and enable real-time automation across the data ecosystem.
Cross-Platform Data Integration
Enterprise environments often include multiple data platforms and tools. AWS data lakes must integrate seamlessly with these systems to ensure consistent data flow. Cross-platform integration enables organizations to combine data from different sources, creating a unified view of business operations. This integration improves analytics accuracy and reduces data fragmentation across systems.
Governance at Enterprise Scale
At large scale, governance becomes more complex but also more critical. Enterprise governance involves defining global policies for data usage, access, retention, and compliance. Automated enforcement of these policies ensures consistency across all datasets. Governance frameworks must be flexible enough to support different business units while maintaining overall control and oversight.
Sustainability and Efficient Computing
Sustainability is becoming an important consideration in large-scale data systems. Efficient computing practices reduce energy consumption and environmental impact. Optimizing storage, minimizing unnecessary processing, and using serverless technologies contribute to greener data operations. AWS data lakes support scalable architectures that can be fine-tuned for energy efficiency without sacrificing performance.
Future Evolution of Enterprise Data Lakes
The future of enterprise data lakes is moving toward greater automation, intelligence, and decentralization. Systems will become more self-managing, with AI handling optimization, security, and governance tasks. Real-time analytics will become the default standard, and integration between systems will become even more seamless. AWS data lakes will continue evolving to support these advancements, enabling organizations to unlock deeper insights and faster innovation at scale.
Operational Excellence in AWS Data Lakes
As AWS data lakes mature, organizations shift their focus from simply running workloads to achieving operational excellence. This stage is about ensuring that the entire system runs reliably, predictably, and efficiently under all conditions. Operational excellence involves continuous monitoring, automation of routine tasks, and proactive identification of issues before they impact users. In a well-managed environment, teams do not just react to problems—they prevent them through structured processes and intelligent system design.
Observability as a Core Capability
Observability goes beyond basic monitoring by providing deep visibility into how data moves and behaves across the entire system. In a large-scale AWS data lake, observability includes tracking data pipelines, transformation steps, query execution paths, and resource usage patterns. This level of insight allows engineers to understand not only when something fails but why it fails. With strong observability practices, organizations can diagnose performance issues quickly and optimize workflows continuously, ensuring consistent system health.
DataOps and Continuous Improvement
DataOps introduces a disciplined approach to managing data workflows, similar to DevOps in software engineering. It focuses on collaboration between data engineers, analysts, and business users while automating deployment and validation of data pipelines. In AWS data lakes, DataOps practices help ensure that changes to data structures, pipelines, or transformations are tested and deployed safely. This reduces errors, improves reliability, and accelerates the delivery of new data capabilities. Continuous improvement becomes a core principle rather than a reactive effort.
Data as a Product Philosophy
Modern data lake strategies increasingly treat datasets as “data products” rather than raw assets. Each dataset is designed with clear ownership, documentation, quality standards, and usage guidelines. This approach ensures that data consumers can easily understand and trust the information they are using. In an AWS-based environment, this means structuring datasets so they are reusable, discoverable, and reliable across multiple teams and applications. Treating data as a product improves accountability and encourages higher quality standards across the organization.
Evolving Toward the Lakehouse Model
As data architectures evolve, many organizations adopt a lakehouse approach, which combines the flexibility of data lakes with the structure and performance of data warehouses. In this model, raw and structured data coexist in a unified system, enabling both exploratory analysis and high-performance reporting. AWS data lakes can support this evolution by integrating storage, processing, and analytics layers into a more cohesive architecture. This reduces duplication, simplifies management, and improves overall efficiency.
Metadata-Driven Intelligence
Metadata becomes increasingly important as systems scale and complexity grows. In advanced AWS data lake environments, metadata is not just descriptive—it becomes operational. Metadata can drive automation, optimize query execution, and even influence data lifecycle decisions. By analyzing metadata patterns, organizations can understand how data is being used, which datasets are most valuable, and where inefficiencies exist. This transforms metadata into a strategic asset rather than a passive record.
Adaptive Data Governance Models
Traditional governance models often struggle to keep up with rapidly evolving data ecosystems. Adaptive governance introduces flexibility by allowing policies to evolve based on usage patterns, risk levels, and business priorities. In AWS data lakes, this means applying different governance rules to different types of data depending on sensitivity and importance. Critical datasets may require strict controls, while exploratory data can have more flexible access. This balance ensures security without limiting innovation.
Intelligent Data Lifecycle Automation
As data volumes continue to grow, manual lifecycle management becomes impractical. Intelligent automation systems can analyze data usage patterns and automatically decide when to archive, compress, or delete data. This ensures that storage resources are used efficiently without requiring constant human intervention. In an AWS data lake environment, lifecycle automation helps maintain performance while significantly reducing operational overhead and storage costs.
Scalable Collaboration Across Teams
Large organizations often have multiple teams working on shared data systems. Effective collaboration requires standardized processes, shared tools, and clearly defined responsibilities. AWS data lakes support this by enabling centralized access with controlled permissions. Teams can work independently while still contributing to a unified data ecosystem. This reduces duplication of effort and ensures consistency across analytics, reporting, and machine learning initiatives.
Real-Time Decision Intelligence
The ultimate goal of a mature data lake is to enable real-time decision intelligence. This means that data is not only collected and analyzed but also acted upon immediately. Businesses can respond to customer behavior, operational changes, and market trends in real time. In an AWS environment, this is achieved by combining streaming data ingestion, fast processing layers, and automated decision systems. The result is a highly responsive organization that can adapt instantly to changing conditions.
Resilience Through Architectural Redundancy
Resilience is a key requirement for enterprise-grade data systems. AWS data lakes achieve resilience through redundancy at multiple levels, including storage replication, multi-zone deployment, and failover mechanisms. This ensures that even if one component fails, the system continues operating without disruption. Architectural redundancy is essential for maintaining uptime and protecting against data loss in mission-critical environments.
Data Culture and Organizational Transformation
Technology alone is not enough to fully realize the value of a data lake. Organizations must also develop a strong data culture where decisions are driven by evidence rather than intuition. This involves training teams, encouraging data literacy, and integrating data into everyday workflows. Over time, this cultural shift leads to more consistent, informed, and effective decision-making across all levels of the organization.
Future-Ready Data Lake Architectures
Looking ahead, AWS data lakes will continue to evolve toward more autonomous, intelligent, and interconnected systems. Future architectures will likely rely heavily on automation, artificial intelligence, and decentralized data ownership. Systems will become more self-healing, self-optimizing, and context-aware. As these advancements unfold, organizations that have built strong foundational data lake systems will be best positioned to take advantage of new innovations without major restructuring.
Conclusion
AWS data lakes provide a powerful and flexible foundation for managing modern data at scale. By allowing organizations to store structured and unstructured data in a single centralized environment, they eliminate traditional data silos and enable more complete and accurate analysis. Over time, these systems evolve from simple storage repositories into advanced ecosystems that support real-time analytics, machine learning, and intelligent decision-making.
As explored across the series, the true strength of an AWS data lake lies not only in its storage capability but in its ability to process, govern, and activate data efficiently. From ingestion and transformation to governance and optimization, each layer plays a crucial role in ensuring that data remains reliable, accessible, and valuable. When properly designed, a data lake becomes more than a technical solution—it becomes a strategic asset that drives innovation and business growth.
In the long term, organizations that invest in building well-structured and well-governed data lakes are better positioned to adapt to changing data demands. They gain the ability to respond quickly to market shifts, uncover deeper insights, and build intelligent systems that improve operational efficiency. As data continues to grow in volume and complexity, AWS data lakes will remain a critical foundation for future-ready, data-driven enterprises.