In networking, every resource that exists on the internet or within a distributed system needs a way to be identified so that systems can locate, access, and reference it consistently. This identification mechanism is essential because modern communication systems rely on precise addressing to ensure that data reaches the correct destination. Without a standardized approach, there would be confusion between resources, duplication of identifiers, and failure in communication between systems. To solve this, the concept of a Uniform Resource Identifier was introduced as a foundational structure for naming and locating resources across networks.
A resource can be anything digital that is accessible over a network, such as documents, images, services, or APIs. The challenge is not just finding these resources but also ensuring that they are uniquely identifiable regardless of where they are stored. This is where the distinction between different forms of identifiers becomes important.
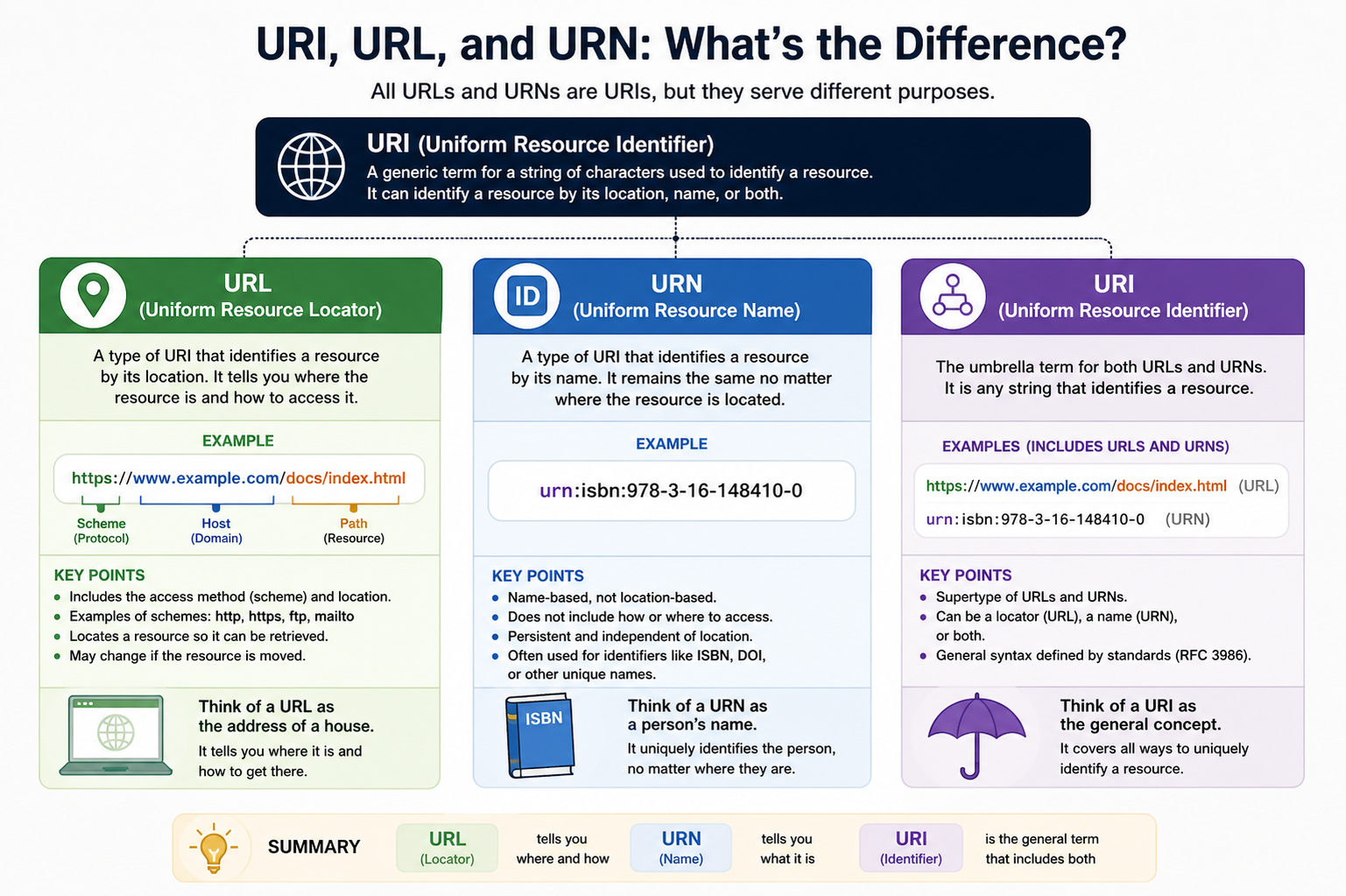
Understanding the Concept of URI in Depth
A Uniform Resource Identifier serves as the most general classification for identifying resources in a structured way. It is designed to provide a standard format that can represent either the name, the location, or both aspects of a resource. This flexibility makes it a universal system used across different networking protocols and systems.
The URI system works by defining a syntax that allows resources to be represented in a consistent format. This format typically includes components such as a scheme, which indicates the method of identification or access, followed by a hierarchical structure that describes the resource. However, the key idea is not the structure itself but the purpose, which is simply identification.
What makes URI important is its ability to unify different identification methods under a single concept. Instead of treating names and locations separately, URI brings them together as variations of the same idea. This is why both URLs and URNs are considered specialized forms of URI rather than completely separate systems.
In practical networking environments, URIs are used in web browsers, application programming interfaces, file systems, and communication protocols. Whenever a system needs to refer to a resource in a standardized way, it uses a URI structure.
How URL Functions as a Location-Based Identifier
A Uniform Resource Locator is a more specific type of URI that focuses on locating resources. Unlike general identifiers, a URL contains information about where a resource is located and how it can be accessed. This makes it highly practical for real-time communication between clients and servers.
A URL typically includes a scheme that defines the protocol used for access, such as web communication protocols, followed by the location details of the resource. These location details may include server addresses and paths that guide the system to the exact resource. The combination of these elements allows a client system to retrieve the resource directly.
The importance of URLs lies in their ability to provide actionable information. While a general identifier may only name a resource, a URL tells the system how to reach it. This is why URLs are heavily used in web browsing and network communication, where immediate access to resources is required.
However, one limitation of URLs is that they are dependent on location. If a resource moves to a different server or path, the URL may become invalid unless updated. This makes URLs less stable as long-term identifiers compared to other forms.
Understanding URN as a Persistent Identifier
A Uniform Resource Name serves a different purpose compared to a URL. Instead of focusing on location, a URN is designed to provide a persistent identity for a resource. This means that even if the resource changes its location, the URN remains the same.
The key idea behind URN is stability. In systems where resources need to be referenced consistently over long periods of time, location-based identifiers are not reliable. URNs solve this by separating identity from location entirely.
A URN does not provide instructions on how to access a resource. Instead, it acts as a permanent label that can be used to refer to the resource regardless of where it exists. In real-world applications, this is useful in libraries, document archiving systems, and distributed databases where long-term referencing is essential.
Because URNs do not include location details, they require additional resolution systems to map the name to an actual resource location when access is needed. This separation between identity and resolution makes URNs more abstract but also more stable.
Structural Differences Between URI, URL, and URN
Although all three concepts are related, their structures reflect their different purposes. A URI is the broad structure that encompasses both naming and locating systems. A URL extends URI by adding location and access information. A URN extends URI by focusing only on naming without including location details.
This structural relationship can be understood as a hierarchy where URI is the parent concept, and URL and URN are specialized forms. The main difference lies in whether location information is included or excluded.
In networking systems, this distinction is important because it determines how resources are accessed and maintained. Systems that require immediate access rely on URLs, while systems that require persistent referencing rely on URNs. URI acts as the unified framework that supports both approaches.
Role of Schemes in Resource Identification
One of the most important components in resource identification is the scheme. The scheme defines the method used to interpret the identifier. In URLs, the scheme often determines the protocol used for communication, which guides how data is transferred between systems.
In URIs in general, the scheme acts as a classification mechanism. It tells the system how to interpret the rest of the identifier. Different schemes may represent different types of resources or access methods.
The scheme is essential because it provides context. Without it, the system would not know how to process the identifier. This makes schemes a foundational part of resource identification in networking.
Importance of Authority and Path in URLs
In URL structures, the authority component plays a crucial role in identifying the location of the resource. This usually includes information about the server or host where the resource is stored. The path component then specifies the exact location of the resource within that system.
Together, these components allow precise navigation to a resource. The authority identifies the destination system, while the path identifies the specific item within that system.
This structured approach is what makes URLs practical for real-time access. It allows systems to quickly resolve the location of a resource and retrieve it without ambiguity.
Resolution Mechanisms in URNs
Since URNs do not include location information, they require a separate resolution mechanism to map names to actual resources. This process involves translating the persistent identifier into a usable location when access is needed.
This separation between naming and resolution provides flexibility. The resource can move across systems without changing its identifier, while the resolution system updates the mapping in the background.
This approach is particularly useful in large-scale distributed systems where resources are frequently relocated or replicated.
Practical Use Cases in Networking Systems
In practical networking environments, all three concepts are used depending on the requirement. URLs are commonly used in web communication where immediate access is required. URNs are used in systems that require stable referencing over time. URIs provide the overarching structure that supports both approaches.
For example, when accessing online content, a URL is typically used because the system needs to know exactly where the content is located. On the other hand, in digital libraries or document indexing systems, URNs are preferred because the identity of the document must remain stable even if its storage location changes.
URIs serve as the general framework that ensures consistency across all these systems, allowing different types of identifiers to coexist in a standardized format.
Relationship Between Identification and Location
One of the most important concepts in networking is the separation between identification and location. Identification refers to naming a resource, while location refers to finding where that resource exists. URLs combine both, URNs focus only on identification, and URIs encompass both concepts.
This separation is important because it allows systems to be flexible. A resource can be identified independently of its location, which means it can move or be replicated without affecting how it is referenced.
At the same time, when immediate access is required, location-based identifiers provide the necessary information to retrieve the resource efficiently.
Foundational Understanding
The distinction between URI, URL, and URN forms a fundamental part of networking concepts. Understanding these differences is essential for grasping how resources are identified, located, and managed across distributed systems. URI acts as the general framework, URL focuses on location-based access, and URN provides persistent naming.
Together, they create a unified system that supports both flexibility and precision in resource identification.
Evolution of Resource Identification Systems
The development of URI, URL, and URN did not happen in isolation. It emerged from the growing complexity of distributed computing systems and the need to manage resources in a standardized way. Early network systems lacked a unified approach to identifying resources, which led to inconsistency and difficulty in sharing information across platforms. As the internet expanded, it became necessary to create a structured model that could handle both identification and access efficiently.
The introduction of URI as a general framework was a major step in solving this problem. It allowed different types of identifiers to coexist under one conceptual model. This meant that instead of creating separate systems for naming and locating resources, a unified approach could be used. Over time, this framework was refined into more specific forms such as URLs and URNs, each serving distinct purposes within the same ecosystem.
Deep Concept of Abstraction in URI Design
One of the key principles behind URI design is abstraction. Abstraction means hiding unnecessary details while still providing enough information for a system to function correctly. In the case of URI, the abstraction allows it to represent both names and locations without forcing a single interpretation.
This is important because different systems have different requirements. Some systems need to know exactly where a resource is located, while others only need a stable reference to it. By abstracting these functions, URI provides a flexible foundation that can support both use cases.
This abstraction also makes URI future-proof. Even if new types of identification systems are introduced, they can still fit within the URI framework as long as they follow the basic principles of structured identification.
Technical Behavior of URL in Network Communication
When a URL is used in a network request, it goes through a process called resolution. The system first interprets the scheme to determine the communication method. Then it identifies the server or host where the resource resides. Finally, it navigates to the specific resource using the path information.
This process is essential in web communication because it allows browsers and applications to retrieve resources efficiently. Each component of the URL plays a role in ensuring that the request reaches the correct destination.
URLs are dynamic in nature. This means they depend heavily on the current structure of the network. If the server address changes or the resource is moved, the URL must also be updated. This dynamic nature makes URLs highly useful for real-time access but less suitable for permanent referencing.
Stability and Persistence in URN Systems
URNs are designed with a completely different philosophy. Instead of focusing on access, they focus on permanence. This means that once a URN is assigned to a resource, it should remain unchanged regardless of where the resource moves.
This stability is achieved by separating identification from location. The URN does not contain any information about where the resource is stored. Instead, it acts as a permanent label that can always be used to refer to the same resource.
In practical systems, this persistence is extremely valuable. For example, in academic or legal systems, documents must be referenced consistently over long periods of time. Even if the storage system changes, the reference must remain valid. URNs make this possible by ensuring that identity does not depend on location.
Comparison of Flexibility and Dependability
URLs and URNs represent two different design philosophies in networking. URLs prioritize flexibility in access, while URNs prioritize stability in identification. This creates a balance between usability and consistency.
URLs are flexible because they can directly guide a system to a resource. However, this flexibility comes at the cost of stability. URNs are stable because they do not depend on location, but they require additional systems to resolve the actual resource location when needed.
This trade-off is intentional. Networking systems often need both fast access and long-term reliability, and the combination of URLs and URNs within the URI framework provides both capabilities.
Role of URI in System Interoperability
One of the most important contributions of URI is interoperability. Interoperability means that different systems can work together without conflict. By providing a universal format for resource identification, URI allows different platforms, applications, and protocols to communicate effectively.
This is especially important in modern distributed environments where multiple systems interact constantly. Without a unified identification system, each platform might use its own method, leading to confusion and incompatibility.
URI solves this by acting as a common language for resource identification. Whether a system uses URL-based access or URN-based naming, both can be represented within the same framework.
Hierarchical Nature of URL Structure
URLs are designed with a hierarchical structure that reflects how resources are organized in network systems. This hierarchy begins with the scheme, followed by the authority, and then the path.
The hierarchical design is important because it mirrors how data is stored and accessed in real systems. Servers often organize resources in directories or structured paths, and URLs reflect this organization.
This structure makes it easier for systems to locate resources quickly. Instead of searching randomly, the system follows a structured path that leads directly to the target resource.
Decoupling Identity from Location in URNs
One of the most powerful ideas in URN design is decoupling identity from location. This means that the identity of a resource is completely independent of where it is stored.
This decoupling allows systems to move resources freely without breaking references. It also allows resources to be replicated across multiple locations while still maintaining a single consistent identity.
In distributed systems, this is extremely important because resources are often migrated, replicated, or reorganized. URNs ensure that such changes do not affect how the resource is referenced.
Practical Importance in Modern Networking
In modern networking, URI, URL, and URN are not just theoretical concepts. They are actively used in everyday systems such as web browsing, cloud computing, and data management.
URLs are used whenever immediate access to a resource is required. URNs are used when long-term referencing is important. URIs provide the overall structure that allows both systems to function together.
This combination ensures that modern networks can handle both dynamic and static resource requirements efficiently.
Concept of Resolution Layers in Resource Access
Resource access in networking often involves multiple resolution layers. The first layer interprets the identifier, the second determines the location, and the final layer retrieves the resource.
In URLs, these layers are combined into a single process because location information is already included. In URNs, additional resolution layers are required to translate the identifier into a usable location.
This layered approach allows systems to remain flexible and scalable. It also allows different identification systems to coexist within the same network infrastructure.
Importance of Standardization in URI System
Standardization plays a crucial role in the effectiveness of URI systems. Without standard rules for structure and interpretation, different systems would create incompatible identifiers.
The standardized format ensures that all systems interpret URIs in the same way. This consistency is what makes global communication over networks possible.
Standardization also allows developers to build applications that work across different platforms without needing custom identification systems.
Future Perspective of Resource Identification Systems
As networking systems continue to evolve, the importance of structured resource identification will increase. More complex distributed systems will require even more reliable ways to identify and access resources.
URI-based systems provide a strong foundation for this future because they are flexible and extensible. New types of identifiers can be introduced without breaking existing systems.
This adaptability ensures that URI, URL, and URN will remain relevant in future networking architectures.
Understanding of the Relationship
The relationship between URI, URL, and URN can be understood as a layered model of resource identification. URI is the base layer that defines the general concept. URL is a specialized layer that focuses on location and access. URN is another specialized layer that focuses on permanent naming.
Together, they form a complete system that supports both dynamic access and stable referencing. This balance is what makes modern networking systems efficient, scalable, and reliable.
Role of Syntax Rules in Resource Identifiers
Resource identifiers in networking follow strict syntax rules to ensure that they can be correctly interpreted by different systems. These rules define how different components of a URI, URL, or URN are arranged and separated. The purpose of this structure is to eliminate ambiguity so that every system understands the identifier in the same way.
The syntax typically organizes information in a logical sequence, starting from the most general classification and moving toward more specific details. This structured arrangement is essential because network systems process information step by step. If the format were inconsistent, systems would fail to correctly interpret the resource reference.
In practical terms, syntax rules also ensure compatibility across platforms. Whether a resource is accessed through a browser, an application, or a backend service, the identifier must follow the same structural logic. This consistency is what allows global systems to communicate without confusion.
Importance of Scheme Interpretation in Networking Systems
The scheme is one of the most critical components in resource identifiers because it defines how the rest of the identifier should be interpreted. In networking, different schemes represent different methods of access or classification. The system first reads the scheme to understand the context before processing the remaining parts of the identifier.
This interpretation step is essential because the same resource structure can behave differently depending on the scheme used. For example, a resource accessed through one scheme might require a secure communication method, while another scheme might follow a different protocol entirely.
Without scheme interpretation, systems would not know how to handle the resource correctly. This makes the scheme a foundational element in ensuring proper communication between systems.
Behavior of Resource Access in Distributed Systems
In distributed environments, resources are not stored in a single location. Instead, they are spread across multiple servers and systems. This makes resource identification even more important because the system must be able to locate the correct resource among many possible locations.
URLs play a significant role in distributed systems because they provide direct paths to resources. However, URNs are equally important because they allow resources to be referenced consistently even when their physical location changes.
The combination of both approaches ensures that distributed systems can remain both flexible and reliable. Resources can be moved or replicated without breaking the logical structure of identification.
Concept of Resource Resolution Chains
Resource resolution in networking often involves multiple steps, known as a resolution chain. This process begins with interpreting the identifier and continues until the actual resource is retrieved.
In the case of URLs, the resolution chain is relatively direct because the location is already embedded within the identifier. The system simply follows the provided path to reach the resource.
In URNs, however, the resolution chain is more complex. The system first identifies the URN, then consults a mapping service or directory system to determine the current location of the resource. Only after this mapping is complete can the resource be accessed.
This layered resolution approach allows flexibility in how resources are managed and accessed.
Differences in Lifecycle Management of Identifiers
Identifiers in networking systems have different lifecycles depending on whether they are URLs or URNs. A URL may change over time if the location of the resource changes. This means its lifecycle is tied to the physical or logical structure of the system where the resource resides.
In contrast, a URN has a much longer lifecycle because it is not affected by changes in location. Once assigned, it remains valid for as long as the resource exists, regardless of where it is stored.
This difference in lifecycle management is important for system design because it determines how resources are tracked and referenced over time.
Role of Persistence in Data Systems
Persistence refers to the ability of a system to maintain consistent references over long periods. In networking, persistence is especially important in systems that deal with large volumes of data or long-term records.
URNs provide this persistence by ensuring that the identity of a resource remains unchanged. This is particularly useful in environments where data integrity and historical consistency are important.
Without persistent identifiers, systems would struggle to maintain accurate references over time, especially when resources are moved or reorganized.
Impact of Resource Identifiers on System Design
The choice between using URL-like or URN-like identifiers has a direct impact on system design. Systems that prioritize fast access and dynamic content management often rely heavily on URLs. These systems are designed for frequent updates and real-time interaction.
On the other hand, systems that require long-term stability and consistent referencing tend to rely more on URNs. These systems are designed for archival, documentation, and structured data storage.
The URI framework allows both design approaches to coexist, giving developers the flexibility to choose the most appropriate method for their system requirements.
Interplay Between Naming and Addressing Concepts
In networking, naming and addressing are two closely related but distinct concepts. Naming refers to identifying a resource in a stable way, while addressing refers to locating that resource in a network.
URNs focus purely on naming, providing a stable identity that does not change over time. URLs focus on addressing, providing the exact location where the resource can be accessed.
URI combines both concepts, allowing systems to handle naming and addressing in a unified structure. This interplay is what makes modern resource identification systems highly flexible.
Scalability of URI-Based Systems
Scalability refers to the ability of a system to handle growth without losing performance or consistency. URI-based systems are highly scalable because they allow different types of identifiers to coexist.
As networks grow, new resources are constantly added, moved, or updated. URI systems accommodate this growth by allowing both location-based and name-based identification methods.
This scalability ensures that even large and complex systems can maintain consistent resource identification.
Error Handling in Resource Identification
In networking systems, errors can occur when identifiers are invalid, outdated, or incorrectly formatted. Proper error handling is essential to ensure system reliability.
When a URL becomes outdated due to a change in resource location, systems typically return an error indicating that the resource cannot be found. This is because URLs depend on current location information.
In contrast, URNs do not directly cause location-based errors because they are not tied to physical addresses. However, they may still fail if the resolution system cannot map the name to a valid resource.
Effective error handling mechanisms ensure that systems can gracefully manage these situations without disrupting overall communication.
Security Considerations in Resource Identification
Security plays an important role in how resource identifiers are used. Since URLs often contain location and access information, they can be used in security mechanisms to control access to resources.
Protocols associated with URLs may include encryption or authentication methods to ensure that only authorized users can access certain resources.
URNs, on the other hand, focus more on identification than access control. However, the resolution systems used to map URNs to locations must still be secured to prevent unauthorized access or manipulation.
This makes security an important consideration in both identification and resolution processes.
Understanding of URI, URL, and URN
The complete relationship between URI, URL, and URN forms a structured system for managing resources in networking. URI acts as the overarching framework that defines how resources are identified. URL provides a method for locating and accessing those resources. URN provides a method for naming them in a persistent and stable way.
Together, they create a balanced system that supports both dynamic access and long-term consistency. This balance is essential for modern distributed systems, where resources must be both accessible and reliably referenced over time.
Practical Applications in Modern Internet Systems
In real-world networking environments, URI, URL, and URN are deeply embedded in almost every system that involves data exchange. Web browsers, mobile applications, cloud services, and APIs all rely on these identification mechanisms to function correctly. Each time a user accesses a resource, a structured identifier is used behind the scenes to locate or reference that resource.
URLs are the most visible form in everyday use because they directly allow access to resources. When a user opens a webpage, downloads a file, or accesses an online service, a URL is being used to guide the system to the correct destination. This makes URLs essential for real-time interaction between users and systems.
URNs, although less visible to end users, are equally important in backend systems. They are widely used in environments where resources must be tracked consistently over long periods. Digital libraries, document management systems, and large-scale databases often rely on URNs to maintain stable references even when resources are moved or reorganized.
URIs act as the underlying structure that supports both of these applications. They provide a universal format that allows different systems to interpret resource identifiers consistently, regardless of whether they are used for access or naming.
Role in Web Architecture and Data Flow
In web architecture, resource identifiers play a central role in controlling data flow between clients and servers. When a request is made, the system interprets the identifier and determines how to process it based on its structure.
If the identifier is a URL, the system follows a direct path to retrieve the resource. This process is fast and efficient, making it suitable for interactive applications. If the identifier is a URN, the system first resolves it into a usable location before accessing the resource.
This separation of concerns allows web systems to handle both immediate requests and long-term references efficiently. It also ensures that data flow remains organized and predictable even in large-scale distributed environments.
Consistency Across Distributed Platforms
One of the major challenges in distributed systems is maintaining consistency across multiple platforms. Different systems may store resources in different locations, use different protocols, or follow different internal structures. Without a unified identification system, managing these resources would become extremely complex.
URI solves this problem by providing a standardized format that all systems can understand. Whether a resource is accessed locally or across a global network, the same identification principles apply.
This consistency ensures that systems can communicate effectively, share resources, and maintain reliable references even in highly complex architectures.
Importance in API Communication
Application programming interfaces rely heavily on resource identifiers to exchange data between systems. APIs use URLs to define endpoints that allow access to specific functions or data sets.
Each API request typically includes a URL that specifies the location of the resource and the method of access. This allows different applications to interact with each other in a structured and predictable way.
While URLs dominate API communication, the underlying concept of URI ensures that these identifiers remain standardized and compatible across different platforms and technologies.
Data Integrity and Resource Tracking
Maintaining data integrity is a critical requirement in modern systems. Resource identifiers help ensure that data remains consistent and traceable over time.
URNs are particularly useful in this context because they provide stable references that do not change even if the underlying data moves. This allows systems to track resources accurately without losing historical references.
URLs, while more dynamic, still contribute to data integrity by ensuring that resources can be accessed correctly at any given time. Together, these systems help maintain a balance between stability and accessibility.
System Efficiency and Optimization
Efficient resource identification contributes directly to system performance. When identifiers are structured properly, systems can quickly interpret and process requests without unnecessary delays.
URLs enable fast access because they provide direct location information. URNs improve long-term efficiency by reducing the need to constantly update references when resources change location.
URI provides the overall framework that allows both efficiency models to coexist. This ensures that systems can optimize performance based on specific requirements.
Future Development of Identification Systems
As technology continues to evolve, resource identification systems are expected to become even more sophisticated. Emerging technologies such as distributed cloud systems, decentralized networks, and large-scale data ecosystems require highly flexible and reliable identification methods.
URI-based systems are well-suited for this future because they are extensible and adaptable. New identification schemes can be introduced without disrupting existing systems.
This adaptability ensures that URI, URL, and URN will continue to play a central role in future networking architectures.
Security and Access Control Integration
Modern systems integrate resource identifiers with security mechanisms to control access to data. URLs often work alongside authentication systems to ensure that only authorized users can access specific resources.
Secure communication protocols are commonly used to protect data during transmission. This ensures that even though URLs provide direct access paths, the data remains protected from unauthorized access.
URNs contribute indirectly to security by providing stable references that can be managed through controlled resolution systems. These systems ensure that only valid and authorized mappings are used to access resources.
Conclusion
The concepts of URI, URL, and URN form a complete and interconnected system for resource identification in networking. Each plays a distinct role while remaining part of a unified framework.
URI serves as the foundational structure that defines how resources are identified in general. It provides a standardized format that supports both naming and locating systems. URL is a specialized form of URI that focuses on locating and accessing resources directly. It is widely used in real-time communication systems where immediate access is required. URN is another specialized form of URI that focuses on providing persistent and stable names for resources without depending on their location.
Together, these systems create a balanced approach to resource management. URLs ensure accessibility, URNs ensure stability, and URIs ensure standardization. This combination allows modern networking systems to function efficiently, scale effectively, and maintain consistency across complex distributed environments.
In essence, understanding URI, URL, and URN is fundamental to understanding how the internet organizes and manages resources. They form the backbone of resource identification and play a crucial role in ensuring that communication between systems remains structured, reliable, and scalable.