Kubernetes has become one of the most widely used container orchestration platforms in the world. From startups to global enterprises, organizations rely on Kubernetes to deploy, manage, and scale applications efficiently. However, for beginners entering the world of cloud-native infrastructure, Kubernetes terminology can feel overwhelming. Two of the most commonly misunderstood concepts are pods and containers.
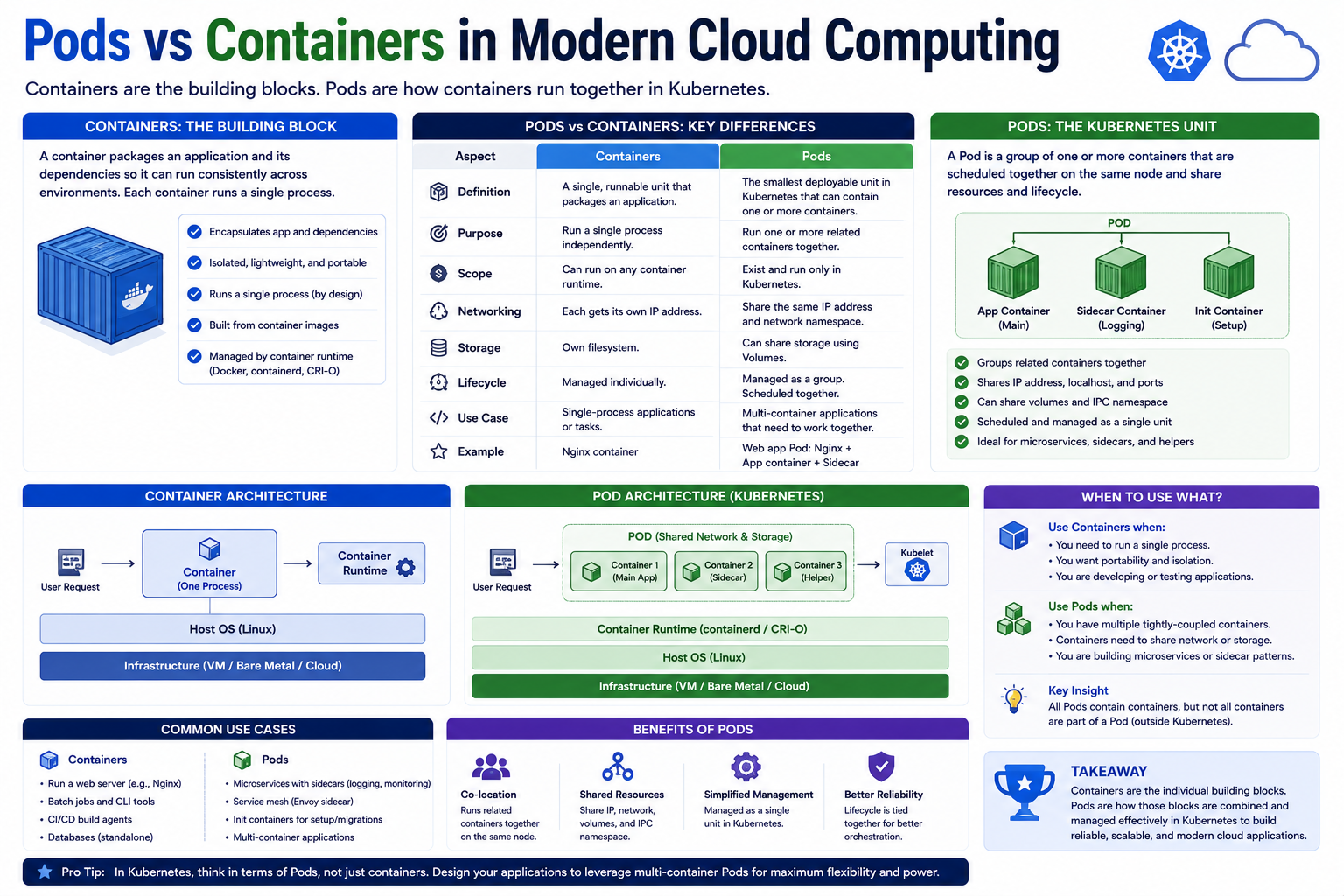
Although the terms are often mentioned together, they are not the same thing. A container is the actual runtime unit that packages and executes an application, while a pod is the Kubernetes object responsible for managing one or more containers. Understanding this relationship is critical because almost every Kubernetes deployment depends on it.
Many people first encounter containers through Docker and later discover Kubernetes when trying to manage applications at scale. At that point, the concept of pods enters the picture. Since Kubernetes rarely runs containers directly without pods, newcomers often struggle to identify the difference between the two technologies and understand why both are necessary.
Learning how pods and containers work together helps build a strong foundation for understanding Kubernetes architecture. Once you understand these building blocks, concepts like deployments, services, scaling, networking, and cluster management become much easier to grasp.
This guide explores the differences between pods and containers, explains why Kubernetes uses pods instead of managing containers directly, and provides a detailed understanding of how these technologies function together inside modern infrastructure environments.
The Evolution of Application Deployment
To understand why containers and pods exist, it is helpful to first examine how applications were deployed before containerization became popular.
Traditionally, applications were installed directly onto physical servers. Each server had its own operating system, installed software packages, configuration files, and dependencies. While this worked for smaller environments, it introduced several major problems as systems became larger and more complex.
Applications often depended on very specific versions of software libraries and operating system components. If those dependencies changed, the application might stop working. Developers frequently encountered the infamous problem where software worked correctly in development but failed in production.
This happened because development and production environments were rarely identical. Differences in:
- Operating system versions
- Installed packages
- Environment variables
- Security policies
- Runtime configurations
could all cause unexpected failures.
As infrastructure grew larger, organizations turned to virtual machines to improve isolation and portability.
The Rise of Virtual Machines
Virtual machines solved several infrastructure problems by allowing multiple isolated operating systems to run on a single physical server. Each virtual machine included:
- A complete operating system
- System libraries
- Application dependencies
- Runtime environments
This approach improved flexibility and reduced hardware costs. However, virtual machines introduced new challenges.
Each virtual machine consumed significant system resources because every VM required its own full operating system. Running many VMs on a single server often resulted in high memory and CPU usage.
Virtual machines were also relatively slow to start and maintain. Booting an operating system could take minutes, and managing large VM environments required substantial overhead.
Organizations needed something lighter, faster, and more portable.
The Birth of Containers
Containers emerged as a solution to many limitations associated with virtual machines.
Instead of virtualizing entire operating systems, containers virtualize the application layer while sharing the host operating system kernel. This makes containers significantly more lightweight than traditional VMs.
A container packages together:
- Application code
- Runtime libraries
- Dependencies
- Configuration files
- Supporting tools
Because everything the application needs is included within the container, the application behaves consistently across environments.
This consistency became one of the biggest advantages of containerization.
Developers could package an application once and run it almost anywhere without worrying about environmental inconsistencies.
Containers also start extremely quickly because they do not require a separate operating system boot process.
Understanding What a Container Really Is
A container is essentially an isolated runtime environment for an application.
Containers allow applications to run independently while sharing the host operating system resources. This isolation helps prevent conflicts between applications running on the same infrastructure.
For example, one server may simultaneously run:
- A web application container
- A database container
- A caching service container
- A monitoring container
Each container operates independently while remaining lightweight and efficient.
Containers are designed around the principle of single responsibility. In most cases, a container runs one primary process or service.
Examples include:
- NGINX web servers
- Python APIs
- MySQL databases
- Redis caching services
- Node.js applications
This modular design simplifies deployment, scaling, and troubleshooting.
Docker and the Container Revolution
Although container technology existed before Docker, Docker made containers mainstream by simplifying container creation and management.
Docker introduced easy-to-use tools for:
- Building images
- Running containers
- Sharing container images
- Managing dependencies
Developers quickly adopted Docker because it streamlined application deployment workflows.
Using Docker, a developer can define an application environment in a Dockerfile. The Dockerfile contains instructions for building the container image.
These instructions may include:
- Selecting a base operating system
- Installing packages
- Copying application files
- Configuring startup commands
- Exposing network ports
Once the image is built, it can be deployed consistently across systems.
What Is a Docker Image?
A Docker image acts as a blueprint for creating containers.
An image contains all the instructions needed to generate a running container instance. It includes:
- Operating system layers
- Application dependencies
- Runtime configurations
- Startup instructions
When the image is executed, it becomes a running container.
Images are immutable, meaning they do not change after creation. If modifications are needed, a new image is built instead.
This immutability improves consistency and reliability across deployments.
Why Containers Became So Popular
Containers rapidly gained popularity because they solved many long-standing infrastructure challenges.
Some major benefits include:
Portability
Containers behave consistently across environments.
Lightweight Architecture
Containers consume fewer resources than virtual machines.
Fast Startup Times
Containers launch within seconds instead of minutes.
Scalability
Containers can be replicated easily.
Isolation
Applications remain separated from one another.
Efficient Resource Usage
Many containers can run on a single host.
These advantages made containers ideal for cloud computing and modern distributed systems.
The Problem with Managing Containers Manually
While containers simplified application deployment, managing large numbers of containers manually became increasingly difficult.
Imagine an environment running hundreds or thousands of containers across multiple servers.
Administrators would need to handle:
- Container placement
- Networking
- Scaling
- Health monitoring
- Load balancing
- Failover handling
- Security policies
- Resource allocation
Managing this manually would be extremely complex and error-prone.
Organizations needed automation tools capable of orchestrating containers efficiently.
This need led to the rise of Kubernetes.
What Is Kubernetes?
Kubernetes is a container orchestration platform designed to automate the deployment, scaling, and management of containerized applications.
Originally developed by Google, Kubernetes provides a powerful framework for managing containers across clusters of servers.
Instead of manually managing individual containers, administrators define the desired application state, and Kubernetes works continuously to maintain that state.
Kubernetes automates tasks such as:
- Scheduling containers
- Replacing failed workloads
- Scaling applications
- Managing networking
- Handling updates
- Allocating resources
This automation allows organizations to run highly scalable and resilient infrastructure environments.
Why Kubernetes Uses Pods
One of the first surprises many newcomers encounter is that Kubernetes does not manage containers directly. Instead, Kubernetes manages pods.
A pod is the smallest deployable unit within Kubernetes.
Pods act as wrappers around containers and provide additional functionality that containers alone do not offer.
This design may initially seem unnecessary, but it solves several important architectural challenges.
Pods provide:
- Shared networking
- Shared storage
- Coordinated lifecycle management
- Resource allocation
- Scheduling boundaries
Without pods, Kubernetes would struggle to efficiently manage groups of related containers.
What Exactly Is a Pod?
A pod is a Kubernetes object that contains one or more containers.
These containers share certain resources and operate together as a single unit.
A pod can include:
- One application container
- Multiple supporting containers
- Shared storage volumes
- Shared networking resources
Pods are designed to support tightly coupled application components.
In most deployments, a pod contains only one container. However, Kubernetes allows multiple containers inside the same pod when necessary.
Containers Inside a Pod
Containers inside the same pod share important resources.
These shared resources include:
Network Namespace
All containers within a pod share the same IP address and network stack.
Storage Volumes
Containers may access shared storage mounted inside the pod.
Inter-Container Communication
Containers can communicate through localhost.
This close integration enables containers to cooperate efficiently.
For example, one container may run the primary application while another container handles log collection.
Why Pods Exist Instead of Running Containers Directly
Pods provide several essential management capabilities that individual containers lack.
Shared Environment
Pods create a shared execution environment for related containers.
Simplified Networking
Containers inside the pod communicate easily using localhost.
Unified Lifecycle
Containers inside a pod start, stop, and restart together.
Scheduling Unit
Kubernetes schedules pods rather than individual containers.
Resource Management
Pods allow centralized control over CPU and memory allocation.
These capabilities simplify orchestration and infrastructure management.
Single-Container Pods
Most Kubernetes workloads use single-container pods.
In this model:
- The pod provides management functionality
- The container runs the application
This design aligns well with container best practices, where each container performs a single responsibility.
Single-container pods remain simple, scalable, and easy to manage.
Multi-Container Pods
Some workloads benefit from multiple containers operating together inside the same pod.
These containers form a tightly integrated application unit.
Common multi-container patterns include:
Sidecar Pattern
A supporting container extends the functionality of the main application.
Examples include:
- Logging agents
- Monitoring tools
- Security proxies
Ambassador Pattern
A helper container manages external communications.
Adapter Pattern
A supporting container transforms application output into standardized formats.
Multi-container pods provide flexibility while maintaining tight coordination between related services.
Pod Networking Explained
Networking is one of the most important features provided by pods.
Each pod receives its own IP address within the Kubernetes cluster.
Containers inside the pod share that network identity.
Because containers share the same network namespace, they can communicate through localhost without requiring complex routing.
Pods communicate with other pods across the Kubernetes cluster using cluster networking systems.
This networking model simplifies distributed application communication.
Pod Lifecycle Basics
Pods follow a lifecycle managed by Kubernetes.
Common pod states include:
- Pending
- Running
- Succeeded
- Failed
- Unknown
Kubernetes continuously monitors pod health and takes corrective actions when necessary.
If a pod fails, Kubernetes may automatically:
- Restart it
- Replace it
- Reschedule it to another node
This self-healing capability improves application reliability.
Ephemeral Nature of Pods
Pods are considered ephemeral resources.
This means they are temporary and replaceable rather than permanent infrastructure components.
If configuration changes are needed, Kubernetes often destroys the old pod and creates a new one.
This immutable infrastructure model improves consistency and predictability.
Applications should avoid storing critical data directly inside pods because pods may disappear at any time.
Persistent storage systems are used for long-term data retention instead.
The Relationship Between Pods and Nodes
Pods run on Kubernetes nodes.
A node is a worker machine within the Kubernetes cluster.
Nodes may be:
- Physical servers
- Virtual machines
- Cloud instances
Kubernetes schedules pods onto nodes based on available resources and scheduling rules.
Each node runs software components responsible for:
- Managing containers
- Communicating with the control plane
- Monitoring workloads
This architecture enables Kubernetes to distribute workloads efficiently across infrastructure resources.
Resource Allocation in Pods
Pods allow administrators to control how much CPU and memory containers can consume.
This helps prevent resource exhaustion and improves cluster stability.
Resource settings include:
Requests
The minimum guaranteed resources.
Limits
The maximum allowable resources.
Kubernetes uses these settings to optimize scheduling and resource utilization.
Proper resource management is essential for maintaining reliable application performance.
Why Understanding Pods and Containers Matters
Understanding the difference between pods and containers is one of the most important foundational concepts in Kubernetes.
Containers focus on running applications.
Pods focus on managing those containers within the Kubernetes ecosystem.
Without understanding this relationship, many Kubernetes features can appear confusing or unnecessarily complicated.
Once the distinction becomes clear, concepts like deployments, scaling, networking, and orchestration become much easier to understand.
Pods and containers work together to create the flexible, scalable, and resilient environments that power modern cloud-native applications across the world today.
Understanding How Pods Manage Containers
After understanding the fundamental differences between pods and containers, the next step is learning how Kubernetes uses pods to control, organize, and maintain containerized applications. While containers handle application execution, pods provide the operational environment that allows Kubernetes to automate management tasks efficiently.
A container by itself is relatively simple. It runs an application process in an isolated environment. However, modern applications require much more than simply running a process. Applications need networking, storage, security, scaling, monitoring, and resource control. Kubernetes addresses these operational requirements through pods.
Pods act as intelligent management layers that wrap around containers and provide the infrastructure necessary for large-scale orchestration. This design enables Kubernetes to automate many tasks that administrators once had to manage manually.
Understanding pod management capabilities is essential because these capabilities form the backbone of Kubernetes operations.
The Architecture of a Kubernetes Pod
A Kubernetes pod is more than just a collection of containers. It is a complete runtime environment designed to support application workloads.
Each pod contains several important components:
- One or more containers
- Shared networking resources
- Shared storage volumes
- Metadata definitions
- Resource policies
- Security configurations
These components work together to provide a stable and manageable environment for applications.
When Kubernetes creates a pod, it allocates the necessary infrastructure resources and ensures the pod operates according to its declared configuration.
Pods are treated as atomic units within Kubernetes. This means the entire pod is scheduled, managed, and monitored as a single entity.
The Role of YAML Configuration Files
Kubernetes resources are commonly defined using YAML configuration files.
These files allow administrators and developers to describe the desired state of the infrastructure declaratively.
A typical pod configuration file contains several important sections:
API Version
The API version tells Kubernetes which version of the Kubernetes API should process the resource definition.
Kind
The kind field specifies the resource type, such as:
- Pod
- Deployment
- Service
- ConfigMap
Metadata
Metadata includes identifying information such as:
- Pod name
- Labels
- Annotations
Spec
The specification section defines the desired pod behavior.
This may include:
- Container images
- Resource limits
- Storage volumes
- Environment variables
- Security settings
YAML files are extremely important because they allow infrastructure to be treated as code.
Declarative Infrastructure Management
One of Kubernetes’ most powerful features is declarative management.
Instead of manually configuring infrastructure step by step, administrators simply describe the desired final state.
Kubernetes continuously compares the current cluster state with the desired state and makes adjustments automatically.
For example, if a deployment requires:
- Three replicas
- Specific memory limits
- Defined networking rules
Kubernetes continuously works to maintain those conditions.
This approach improves:
- Automation
- Reliability
- Consistency
- Scalability
Declarative infrastructure also integrates well with version control systems and CI/CD pipelines.
Imperative Commands vs Declarative Configurations
Kubernetes supports both imperative and declarative approaches.
Imperative Management
Imperative commands directly instruct Kubernetes to perform actions immediately.
Examples include:
- Creating a pod
- Deleting a deployment
- Scaling replicas manually
Imperative commands are useful for:
- Learning Kubernetes
- Quick testing
- Troubleshooting
However, they become difficult to manage at scale.
Declarative Management
Declarative management uses configuration files to define desired system behavior.
This approach is preferred for production environments because it supports:
- Repeatability
- Infrastructure versioning
- Collaboration
- Automation
Most professional Kubernetes environments rely heavily on declarative configurations.
Pod Scheduling and Cluster Placement
One of the core responsibilities of Kubernetes is determining where pods should run within the cluster.
This process is known as scheduling.
The Kubernetes scheduler evaluates cluster resources and decides which node is best suited to host each pod.
Scheduling decisions consider factors such as:
- Available CPU
- Available memory
- Node health
- Affinity rules
- Taints and tolerations
- Geographic placement
The scheduler attempts to distribute workloads efficiently across the cluster.
This automated placement system reduces manual administrative work and improves infrastructure utilization.
Kubernetes Nodes and Pods
Pods do not run independently. They operate on worker machines called nodes.
A Kubernetes node may be:
- A physical server
- A virtual machine
- A cloud instance
Each node contains software components responsible for managing pods and containers.
Important node components include:
Kubelet
The kubelet communicates with the Kubernetes control plane and ensures pods run correctly on the node.
Container Runtime
The container runtime is responsible for running containers.
Examples include:
- containerd
- CRI-O
- Docker Engine
Kube Proxy
Kube Proxy manages network communication and routing for pods.
Together, these components allow Kubernetes to coordinate workloads across distributed infrastructure.
Pod Networking Fundamentals
Networking is one of the most important functions provided by pods.
Every pod receives:
- Its own IP address
- Shared network namespace
Containers inside the same pod share networking resources, allowing them to communicate through localhost.
This simplifies communication between tightly coupled application components.
For example:
- A web application container
- A logging sidecar container
can communicate directly without external networking configuration.
Pods also communicate with other pods across the Kubernetes cluster using cluster networking systems.
Cluster Networking and Service Discovery
As applications scale, managing communication between pods becomes increasingly complex.
Kubernetes simplifies this through built-in networking and service discovery features.
Pods can locate and communicate with each other using:
- Cluster DNS
- Services
- Labels and selectors
Kubernetes services provide stable network endpoints even when pods are replaced or rescheduled.
This abstraction improves reliability and scalability.
Applications do not need to track individual pod IP addresses manually.
Shared Storage Inside Pods
Pods may also provide shared storage volumes accessible by all containers within the pod.
This shared storage enables containers to exchange data efficiently.
Common use cases include:
- Shared configuration files
- Log file access
- Temporary caching
- Inter-container communication
Volumes may be:
- Temporary
- Persistent
- Network-based
- Cloud-managed
Storage flexibility is essential for modern distributed applications.
Understanding Pod Lifecycles
Pods follow defined lifecycle stages managed by Kubernetes.
Typical pod phases include:
Pending
The pod has been accepted but is not yet running.
Running
The pod is actively executing containers.
Succeeded
The pod completed successfully.
Failed
One or more containers terminated unexpectedly.
Unknown
Kubernetes cannot determine pod status.
Kubernetes constantly monitors pod health and responds automatically to failures.
Self-Healing Capabilities
One of Kubernetes’ most valuable features is self-healing infrastructure.
If a pod crashes or becomes unhealthy, Kubernetes can:
- Restart the container
- Replace the pod
- Move the workload to another node
This automation significantly improves application reliability.
Traditional infrastructure often required administrators to manually detect and resolve failures.
Kubernetes automates much of this process.
Health Checks and Probes
Kubernetes uses health checks called probes to monitor application status.
Common probe types include:
Liveness Probes
Determine whether a container is still functioning properly.
Readiness Probes
Determine whether a container is ready to receive traffic.
Startup Probes
Help slow-starting applications initialize properly.
These probes allow Kubernetes to make intelligent decisions about workload management.
For example, Kubernetes can stop routing traffic to unhealthy pods automatically.
Resource Requests and Limits
Resource management is another major responsibility of pods.
Applications can consume large amounts of CPU and memory if left unrestricted.
Kubernetes allows administrators to define:
Resource Requests
Guaranteed minimum resources allocated to the container.
Resource Limits
Maximum allowable resource usage.
These settings improve cluster stability and prevent resource exhaustion.
Without resource limits, a single malfunctioning application could consume excessive system resources and impact other workloads.
CPU and Memory Management
Pods allow precise control over CPU and memory allocation.
For example:
- CPU requests ensure baseline performance
- CPU limits prevent overconsumption
- Memory requests reserve required RAM
- Memory limits prevent crashes from memory leaks
Kubernetes uses these values when making scheduling decisions.
Proper resource allocation improves:
- Performance stability
- Infrastructure efficiency
- Cost management
Security Contexts in Pods
Security is a critical aspect of Kubernetes infrastructure.
Pods can enforce security policies through security contexts.
Security contexts allow administrators to define:
- User IDs
- Group IDs
- Privilege restrictions
- Filesystem permissions
- Linux capabilities
For example, administrators can prevent containers from:
- Running as root users
- Escalating privileges
- Accessing sensitive host resources
These protections reduce the risk of container-based attacks.
Isolation and Security Boundaries
Although containers share the host operating system kernel, Kubernetes still provides important isolation mechanisms.
Pods help establish boundaries between workloads.
This isolation improves:
- Multi-tenant security
- Resource separation
- Application stability
Namespaces further enhance isolation by separating workloads into logical environments.
Organizations often use namespaces to isolate:
- Development environments
- Testing systems
- Production applications
Multi-Container Pod Communication
Containers inside the same pod communicate very efficiently because they share networking resources.
This design supports specialized application architectures.
Examples include:
Logging Sidecars
A secondary container collects and forwards application logs.
Monitoring Containers
A helper container gathers metrics and telemetry data.
Proxy Containers
A supporting container manages secure network traffic.
These supporting containers enhance application functionality without modifying the main application code.
Sidecar Container Pattern
The sidecar pattern is one of the most common multi-container pod architectures.
In this pattern:
- One container runs the primary application
- Another container provides supporting services
Examples include:
- Log aggregation
- Data synchronization
- Service mesh proxies
- Monitoring agents
Sidecars allow developers to separate concerns cleanly.
This improves modularity and maintainability.
Pod Scaling and Replication
Kubernetes allows pods to scale horizontally by creating multiple replicas.
As application demand increases, Kubernetes can automatically deploy additional pod instances.
This process improves:
- Availability
- Performance
- Fault tolerance
Scaling may occur based on:
- CPU utilization
- Memory usage
- Request rates
- Custom application metrics
Automatic scaling is one of Kubernetes’ most powerful capabilities.
ReplicaSets and Deployments
Pods themselves are rarely managed directly in production environments.
Instead, Kubernetes typically uses higher-level controllers such as:
- ReplicaSets
- Deployments
- StatefulSets
These controllers manage pod lifecycles automatically.
For example, a deployment may ensure:
- A specific number of pod replicas
- Rolling updates
- Automatic recovery
Controllers simplify large-scale application management significantly.
Rolling Updates and Pod Replacement
Kubernetes supports rolling updates for application deployments.
Instead of shutting down entire applications during updates, Kubernetes gradually replaces old pods with new ones.
This minimizes downtime and improves user experience.
Rolling updates allow organizations to:
- Deploy new versions safely
- Monitor stability during rollout
- Roll back failed updates
Pods make this process possible because they are designed to be disposable and replaceable.
Immutable Infrastructure Philosophy
Kubernetes embraces the concept of immutable infrastructure.
Rather than modifying running systems directly, new versions replace old versions entirely.
Pods are central to this philosophy.
If changes are needed:
- New pods are created
- Old pods are terminated
This approach reduces configuration drift and improves consistency across environments.
Immutable infrastructure also simplifies troubleshooting because deployments become highly predictable.
Monitoring and Observability
Modern applications require extensive monitoring and observability capabilities.
Pods integrate with monitoring systems to provide visibility into:
- CPU usage
- Memory consumption
- Network traffic
- Application logs
- Error rates
Observability tools help administrators detect problems quickly and optimize application performance.
Common monitoring platforms include:
- Prometheus
- Grafana
- Elasticsearch
- Fluentd
Kubernetes environments often rely heavily on these tools.
Why Pods Are Essential in Kubernetes
Pods exist because Kubernetes needs a flexible way to manage containers as coordinated workloads.
Containers alone cannot provide:
- Shared networking
- Shared storage
- Scheduling boundaries
- Resource management
- Lifecycle coordination
Pods solve these challenges elegantly.
By grouping containers into manageable units, Kubernetes creates a scalable and highly automated infrastructure platform.
Understanding how pods manage containers is essential for anyone working with Kubernetes because nearly every orchestration feature depends on this relationship.
Understanding the Bigger Picture of Kubernetes
As organizations continue adopting cloud-native technologies, Kubernetes has become a foundational platform for managing modern applications. While understanding the basic difference between pods and containers is important, gaining deeper knowledge about how Kubernetes uses these components in real-world environments is what truly helps professionals become comfortable with the platform.
Containers are responsible for running applications, but Kubernetes adds layers of automation, orchestration, scalability, resilience, and operational control through pods and other higher-level resources. Pods are not merely wrappers around containers. They are central building blocks that help Kubernetes create highly reliable and scalable environments.
Modern infrastructure requires applications to remain available even during failures, traffic spikes, updates, or hardware problems. Kubernetes achieves this by treating pods as manageable, replaceable units that can be monitored and controlled continuously.
To fully appreciate the role of pods and containers, it is important to understand how they interact with Kubernetes services, deployments, scaling mechanisms, storage systems, and security models.
Pods as Temporary Infrastructure Components
One of the most important Kubernetes principles is that pods are temporary rather than permanent.
Traditional infrastructure often treated servers as long-lasting systems that administrators manually maintained over time. Kubernetes takes a different approach. Pods are designed to be disposable and replaceable.
If a pod becomes unhealthy, Kubernetes simply replaces it with a new one.
This philosophy creates several major advantages:
- Improved reliability
- Faster recovery from failures
- Easier upgrades
- Better scalability
- More predictable infrastructure
Because pods are temporary, Kubernetes environments become highly dynamic.
Applications are expected to tolerate pod replacement without interruption.
This approach encourages developers to design applications that are resilient and distributed rather than dependent on individual machines.
Why Containers Alone Are Not Enough
Containers are extremely useful for packaging and running applications, but they are limited in terms of orchestration and operational management.
A standalone container does not automatically provide:
- High availability
- Auto-scaling
- Service discovery
- Health monitoring
- Failover recovery
- Resource balancing
- Rolling updates
Kubernetes pods help bridge this gap by integrating containers into a larger orchestration ecosystem.
Pods provide the management layer that allows Kubernetes to automate operational tasks efficiently.
Without pods, Kubernetes would have difficulty coordinating groups of related containers and maintaining application consistency across clusters.
Deployments and Pod Management
In production Kubernetes environments, administrators rarely create individual pods manually.
Instead, pods are usually managed through higher-level resources called deployments.
A deployment is a Kubernetes object responsible for:
- Creating pods
- Maintaining replica counts
- Performing updates
- Replacing failed pods
- Managing rollout strategies
Deployments continuously monitor the desired number of pod replicas and ensure the cluster maintains that state.
For example, if a deployment requires five application replicas and one pod crashes, Kubernetes automatically creates a replacement pod.
This automation improves application uptime and reduces manual intervention.
ReplicaSets and High Availability
Deployments rely on ReplicaSets to maintain pod availability.
A ReplicaSet ensures that a specific number of pod instances remain operational at all times.
For example:
- If traffic increases, administrators can increase replicas
- If a pod fails, ReplicaSets create replacements
- If nodes become unavailable, workloads can move elsewhere
This architecture enables highly available applications.
Containers alone cannot provide these capabilities because they lack orchestration awareness.
Pods combined with ReplicaSets create resilient distributed systems.
Horizontal Scaling in Kubernetes
Modern applications often experience fluctuating workloads.
Traffic may increase dramatically during:
- Business hours
- Product launches
- Seasonal events
- Marketing campaigns
Kubernetes handles this through horizontal scaling.
Horizontal scaling means increasing the number of pod replicas rather than increasing hardware resources for a single instance.
Pods are ideal for scaling because they are lightweight and replaceable.
Kubernetes can quickly launch additional pod replicas to handle increased demand.
When demand decreases, Kubernetes can reduce replica counts to conserve resources.
This flexibility allows organizations to optimize infrastructure costs and performance.
Horizontal Pod Autoscaling
Kubernetes includes a feature called Horizontal Pod Autoscaler.
This system automatically adjusts pod replica counts based on performance metrics such as:
- CPU utilization
- Memory usage
- Request rates
- Custom application metrics
For example:
- High CPU usage may trigger additional pod creation
- Low resource usage may reduce replicas
Autoscaling improves efficiency because applications receive resources dynamically based on real-time demand.
This capability is especially valuable in cloud environments where resource usage directly impacts operating costs.
Stateful Applications and Pods
Not all applications are stateless.
Some workloads require persistent identities and stable storage.
Examples include:
- Databases
- Message brokers
- Distributed storage systems
Kubernetes handles these workloads using StatefulSets.
StatefulSets manage pods that require:
- Stable network identities
- Persistent storage
- Ordered deployment behavior
Even in stateful environments, pods remain replaceable. However, Kubernetes preserves important application data through persistent storage mechanisms.
This demonstrates the flexibility of the pod-based architecture.
Persistent Storage in Kubernetes
Because pods are ephemeral, data stored directly inside a pod may disappear if the pod is replaced.
To solve this problem, Kubernetes provides persistent storage systems.
Persistent volumes allow applications to store data independently from pod lifecycles.
Storage solutions may include:
- Local disks
- Network file systems
- Cloud storage services
- Distributed storage clusters
Pods can mount these storage resources and continue accessing data even after replacement.
This separation between compute and storage improves resilience and scalability.
Kubernetes Services and Pod Networking
Pods are dynamic and temporary. Their IP addresses may change whenever they are recreated.
To provide stable communication, Kubernetes uses services.
A service acts as a consistent network endpoint that routes traffic to pods.
Services enable applications to communicate reliably without needing to track individual pod IP addresses.
Kubernetes services support:
- Internal cluster communication
- External traffic exposure
- Load balancing
- Service discovery
This abstraction greatly simplifies distributed application networking.
Load Balancing Across Pods
When multiple pod replicas exist, Kubernetes services distribute traffic across them automatically.
This process is called load balancing.
Load balancing improves:
- Application performance
- Fault tolerance
- Resource utilization
For example, instead of sending all traffic to one pod, Kubernetes distributes requests evenly across available replicas.
If one pod fails, traffic automatically shifts to healthy pods.
This dynamic routing is essential for maintaining highly available applications.
Rolling Updates and Zero Downtime Deployments
One of Kubernetes’ most powerful capabilities is rolling updates.
Traditional deployments often required taking applications offline during updates. Kubernetes eliminates much of this downtime by gradually replacing old pods with new versions.
During a rolling update:
- New pods launch gradually
- Old pods terminate slowly
- Traffic shifts incrementally
- Health checks verify stability
If problems occur, Kubernetes can pause or roll back the deployment.
Pods make rolling updates possible because they are designed to be disposable.
This approach significantly improves deployment reliability.
Kubernetes and Microservices
Kubernetes works particularly well with microservices architectures.
In a microservices environment:
- Applications are divided into smaller services
- Each service performs a focused task
- Services communicate through APIs
Containers package each microservice independently.
Pods then manage those containers within the Kubernetes cluster.
This architecture offers several advantages:
- Independent scaling
- Faster deployments
- Improved fault isolation
- Easier maintenance
Kubernetes pods help coordinate these distributed services efficiently.
Sidecar Containers in Real-World Environments
Multi-container pods become especially useful in advanced production environments.
The sidecar pattern is one of the most widely used approaches.
In this architecture:
- The main container runs the application
- Supporting containers provide auxiliary functionality
Examples include:
Logging Sidecars
Collect and forward application logs.
Monitoring Sidecars
Gather metrics and telemetry information.
Proxy Sidecars
Manage secure communication and traffic routing.
Service mesh technologies such as Istio heavily rely on sidecar containers.
This pattern demonstrates how pods enable modular yet tightly integrated application designs.
Security Challenges in Kubernetes
As Kubernetes environments grow, security becomes increasingly important.
Containers share the host operating system kernel, which creates potential security risks if not managed carefully.
Pods help Kubernetes enforce security policies consistently.
Administrators can configure pods to:
- Restrict root access
- Prevent privilege escalation
- Limit filesystem access
- Control Linux capabilities
- Define network policies
These protections help secure containerized workloads in multi-tenant environments.
Namespaces and Workload Isolation
Namespaces provide logical separation between Kubernetes workloads.
Organizations often use namespaces to isolate:
- Development environments
- Testing systems
- Production applications
- Different teams or departments
Pods operate within namespaces, helping maintain organizational boundaries inside the cluster.
Namespaces improve:
- Security
- Resource organization
- Administrative control
This layered isolation model is critical for large enterprise environments.
Resource Efficiency and Infrastructure Optimization
Containers and pods improve infrastructure efficiency significantly compared to traditional virtual machines.
Because containers share the host operating system kernel, organizations can run far more workloads on the same hardware.
Pods further optimize infrastructure usage by allowing Kubernetes to schedule workloads intelligently.
Kubernetes evaluates factors such as:
- CPU availability
- Memory capacity
- Storage resources
- Network utilization
This optimization improves:
- Performance
- Cost efficiency
- Scalability
Cloud providers especially benefit from Kubernetes resource efficiency.
Monitoring Kubernetes Pods
Modern production systems require detailed monitoring and observability.
Kubernetes integrates with monitoring tools that track:
- Pod health
- Resource usage
- Application performance
- Network activity
- Error rates
Popular monitoring platforms include:
- Prometheus
- Grafana
- Fluentd
- Elasticsearch
These tools provide visibility into cluster behavior and help administrators identify issues quickly.
Monitoring becomes especially important in large environments containing hundreds or thousands of pods.
Logging in Kubernetes Environments
Logging is another critical operational concern.
Because pods are temporary, logs stored locally inside containers may disappear during pod replacement.
To solve this problem, Kubernetes environments often centralize logging using external systems.
Common logging workflows include:
- Sidecar log collectors
- Centralized logging platforms
- Cloud-based monitoring services
This ensures logs remain available even after pods terminate.
Effective logging improves troubleshooting, auditing, and performance analysis.
Challenges Beginners Face with Pods and Containers
New Kubernetes users often struggle with several common concepts.
Assuming Pods and Containers Are the Same
Many beginners mistakenly believe pods are simply another name for containers.
Forgetting Pod Ephemerality
Some users attempt to store important data directly inside pods.
Overcomplicating Multi-Container Pods
Not every workload requires multiple containers in a single pod.
Ignoring Resource Limits
Failing to define resource constraints can destabilize clusters.
Learning Kubernetes takes time, but understanding pods and containers provides a strong foundation for mastering more advanced topics.
The Future of Kubernetes and Cloud-Native Infrastructure
Kubernetes continues evolving rapidly.
Organizations increasingly use Kubernetes for:
- Hybrid cloud deployments
- Edge computing
- AI workloads
- Large-scale microservices
- Serverless architectures
Pods and containers remain central to these innovations.
As cloud-native infrastructure grows, professionals with Kubernetes expertise will continue to be in high demand.
Understanding the relationship between pods and containers is no longer optional for many IT roles. It has become foundational knowledge for developers, DevOps engineers, cloud architects, and system administrators.
Final Comparison Between Pods and Containers
Although pods and containers are closely connected, they serve very different purposes.
Containers focus on:
- Running applications
- Packaging dependencies
- Providing isolated runtime environments
Pods focus on:
- Managing containers
- Coordinating resources
- Providing shared networking
- Enabling orchestration
- Supporting scaling and recovery
A container is the application runtime unit.
A pod is the Kubernetes management unit.
Understanding this distinction is essential for working effectively with Kubernetes.
Conclusion
Kubernetes transformed the way organizations deploy and manage applications by introducing powerful orchestration capabilities for containerized workloads. At the center of this system are pods and containers, two concepts that are deeply related yet fundamentally different.
Containers provide lightweight, portable environments for running applications consistently across infrastructure platforms. They package code, dependencies, and runtime components into isolated units that can be deployed quickly and efficiently.
Pods, on the other hand, provide the operational layer that Kubernetes uses to manage those containers. Pods enable shared networking, resource allocation, lifecycle coordination, scaling, monitoring, and recovery. Kubernetes depends on pods because they create manageable units that can be orchestrated reliably across large distributed environments.
The relationship between pods and containers represents one of the most important concepts in Kubernetes. Containers execute applications, while pods organize and control them within the cluster.
As cloud-native infrastructure continues expanding, understanding pods and containers becomes increasingly valuable for anyone working in modern IT environments. Whether managing microservices, deploying scalable applications, or building resilient cloud platforms, these concepts form the foundation of Kubernetes expertise.