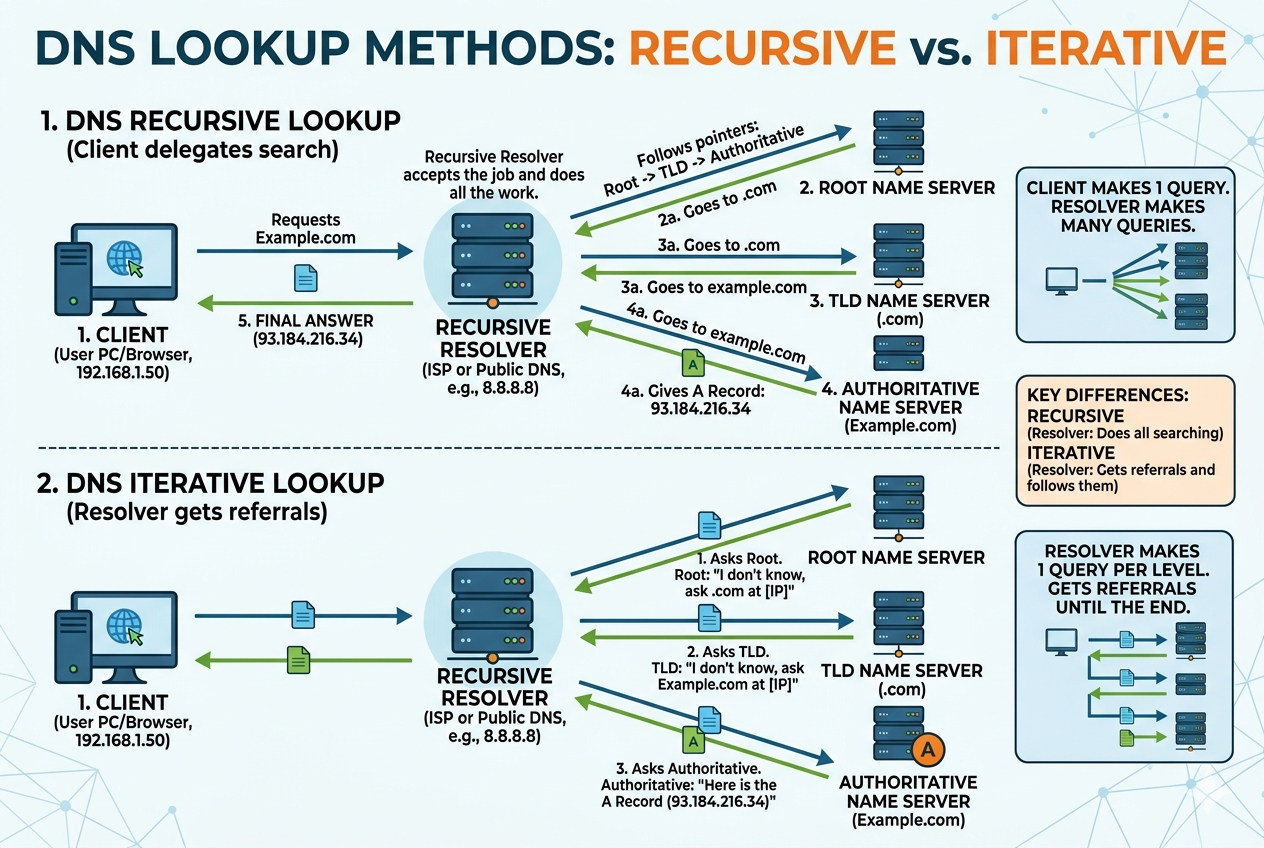
In a recursive lookup process, the resolution of a domain name follows a structured path that is fully managed by a single DNS resolver. When a user device sends a query, it does not directly communicate with multiple DNS servers. Instead, it forwards the request to a recursive resolver, which is responsible for obtaining the final answer.
The resolver begins by checking its own cache to see if it has recently stored the required information. If the answer is not available, it starts the resolution process by contacting higher-level DNS infrastructure. It first reaches a root-level server, which does not provide the final IP address but instead directs the resolver toward a more specific server responsible for the relevant domain category. The resolver then continues the journey by querying the next server in the hierarchy, gradually narrowing down the search until it reaches the authoritative source.
Once the authoritative server responds with the correct IP address, the recursive resolver stores this information temporarily for future use and sends the final answer back to the client. This entire sequence happens without requiring any additional effort from the user device after the initial request.
The key characteristic of this flow is centralization of responsibility. The client simply waits for a completed response while the recursive resolver performs all intermediate steps in the background.
DNS Resolution Flow in Iterative Lookup
In iterative lookup, the process is more distributed and involves multiple back-and-forth interactions. Instead of a single resolver handling everything, each DNS server in the chain plays a limited role by offering the best information it has and pointing the requester to the next step.
When a client sends a query to a DNS server, that server first checks if it can answer directly. If it cannot, it responds with a referral, guiding the client to another DNS server that is closer to the final answer. The client then sends a new request to that referred server, continuing the process.
This sequence continues until the client reaches the authoritative server that holds the actual mapping between the domain name and its IP address. Only at this final stage does the client receive the complete answer.
Unlike recursive lookup, no single server completes the entire process. Instead, responsibility is distributed across multiple servers, and the client participates actively in following each referral step.
Role of DNS Hierarchy in Both Methods
Both recursive and iterative lookups rely on the hierarchical structure of the DNS system, but they interact with it differently.
In recursive lookup, the hierarchy is traversed by the resolver on behalf of the client. The resolver acts like a navigator that moves through different layers of the system until it finds the final answer.
In iterative lookup, the hierarchy is exposed to the client or initial resolver. Each server only provides a partial direction, meaning the requester is gradually guided through the hierarchy step by step.
The DNS hierarchy typically consists of multiple layers, starting from root-level servers at the top, followed by more specific domain-level servers, and finally authoritative servers that contain the actual records. The way these layers are accessed defines the difference between recursive and iterative behavior.
Caching Behavior in Recursive Lookup
Caching plays a major role in improving the efficiency of recursive DNS resolution. Once a recursive resolver successfully retrieves an IP address for a domain, it stores that result temporarily.
When another request for the same domain arrives, the resolver can immediately respond using the cached data instead of repeating the entire lookup process. This significantly reduces latency and improves performance for frequently accessed domains.
The duration for which this information is stored depends on a time-based value associated with the DNS record. After this period expires, the cached data is discarded or refreshed through a new lookup.
Caching is one of the main reasons recursive lookup is widely used in practical systems, as it reduces network load and speeds up repeated queries.
Caching in Iterative Lookup
In iterative lookup, caching can still exist but is not centralized in the same way. Since the client or intermediate resolvers handle multiple steps, caching may occur at different points in the process.
However, because each step involves separate interactions, caching does not provide the same level of efficiency improvement as in recursive systems. The client may still need to perform multiple queries even if some intermediate data is cached elsewhere.
This makes iterative lookup more dependent on repeated communication between different DNS servers, especially when no cached information is available at the required stage.
Performance Differences Between Recursive and Iterative Lookup
Performance is one of the most noticeable differences between the two methods. Recursive lookup generally provides faster results for the client after the first request because the resolver handles all complexity internally and returns a complete answer.
Once caching is involved, recursive systems become even faster for repeated queries, as many lookups can be resolved instantly.
Iterative lookup, on the other hand, may take longer for each query because it involves multiple communication steps. Each referral requires a new request, which increases the overall resolution time. However, in environments where distributed control is preferred, this trade-off is acceptable.
Load Distribution in DNS Systems
Recursive lookup centralizes workload on DNS resolvers. These resolvers must handle full query resolution processes, which can make them resource-intensive. To manage this, large-scale systems often deploy multiple recursive resolvers to distribute the load.
Iterative lookup distributes the workload across multiple servers in the DNS hierarchy. Each server only performs a small task by providing referrals instead of full answers. This reduces the burden on any single system but increases overall communication between servers.
Both methods achieve scalability in different ways, one by centralizing intelligence and the other by distributing responsibility.
Security Considerations in Recursive Lookup
Recursive resolvers are often exposed to security risks because they handle full queries and store cached results. If not properly secured, they can be targeted for misuse, such as cache poisoning, where incorrect data is inserted into the resolver’s cache.
To mitigate these risks, modern recursive systems use validation mechanisms and strict response verification. This helps ensure that the data returned to clients is accurate and trustworthy.
Despite these challenges, recursive lookup remains widely used due to its simplicity and efficiency for end users.
Security Aspects of Iterative Lookup
Iterative lookup has a different security profile because it involves direct communication with multiple servers. Since each server only provides partial information, there is less reliance on a single point of data storage.
However, the multiple-step nature of iterative lookup increases exposure to potential interception during each referral step. Each interaction between servers or clients can be a point of vulnerability if not properly protected.
Overall, both systems require secure communication protocols to ensure data integrity, but recursive systems rely more heavily on the security of the resolver, while iterative systems depend on the security of multiple nodes in the chain.
Latency and User Experience Impact
From a user experience perspective, recursive lookup is generally more efficient. Users send a single request and receive a complete response without needing to handle intermediate steps. This reduces perceived delay and simplifies the overall experience.
Iterative lookup can introduce higher latency because multiple requests must be made sequentially. Each step adds a small delay, which accumulates across the full resolution process.
This difference makes recursive lookup more suitable for general internet usage, where speed and simplicity are important, while iterative lookup is more common in underlying DNS infrastructure operations.
Use Cases of Recursive Lookup
Recursive lookup is commonly used in client-facing environments. When users access websites or applications, their devices typically rely on recursive resolvers provided by network services.
This model is ideal for everyday internet browsing, where users expect fast and seamless access without needing to understand the underlying DNS structure.
It is also widely used in enterprise and service provider environments where large numbers of queries must be resolved efficiently with minimal delay.
Use Cases of Iterative Lookup
Iterative lookup is primarily used within the DNS infrastructure itself. Authoritative servers and intermediate DNS servers often rely on iterative responses to guide queries along the correct path.
It is especially useful in distributed systems where each server is responsible for only a portion of the DNS hierarchy. By providing referrals instead of full answers, servers maintain scalability and reduce unnecessary processing load.
This method ensures that the DNS system remains decentralized and resilient.
Scalability Differences
Recursive lookup scales by increasing the number of resolvers and improving caching efficiency. As more users rely on cached results, the system becomes faster over time.
Iterative lookup scales naturally through its distributed structure. Since each server only handles a small part of the process, the system can grow without requiring individual nodes to become significantly more powerful.
Both approaches contribute to the overall scalability of the DNS ecosystem, but they do so in fundamentally different ways.
Reliability and Fault Tolerance
Recursive systems provide strong reliability for end users because the resolver manages all fallback mechanisms internally. If one path fails, it can try alternative routes until a valid response is found.
Iterative systems rely on the availability of multiple servers. If a server fails, the referral process may need to be redirected through another path. This can increase complexity but also prevents overdependence on a single system.
Together, both methods ensure that DNS resolution remains robust even in cases of partial network failure.
Overall Structural Difference
The fundamental distinction between recursive and iterative lookup lies in where the intelligence of the resolution process resides.
Recursive lookup places intelligence in the resolver, which handles everything from start to finish. Iterative lookup distributes intelligence across multiple servers, each contributing a small piece of the resolution process.
This difference shapes how DNS operates at both user and infrastructure levels, balancing simplicity for clients with distributed efficiency for the global system.
Error Handling in Recursive DNS Lookup
In recursive DNS lookup, error handling is largely managed by the recursive resolver itself. When a resolver is unable to find a valid response, it does not immediately fail the request. Instead, it attempts multiple strategies to complete the resolution process. This may include querying alternative authoritative servers, retrying requests, or using cached fallback data if available.
If the resolver ultimately cannot find a valid record, it returns an error response to the client. From the client’s perspective, the entire process appears as a single interaction, even though multiple internal attempts may have occurred.
This centralized error handling makes recursive lookup more user-friendly because clients do not need to manage failures or retries on their own. The complexity is hidden within the resolver, ensuring a smoother experience.
Error Handling in Iterative DNS Lookup
In iterative lookup, error handling is more distributed and visible to the requester. Since each DNS server only provides partial information, any failure at a given step must be handled by the client or the querying resolver.
If a referred server does not respond or is unreachable, the client must attempt another path or retry the query with a different server. This makes the process more complex and dependent on multiple successful interactions.
Unlike recursive lookup, there is no single system responsible for completing the entire resolution. As a result, error recovery requires more coordination and can take longer when issues occur at any stage of the chain.
Control and Responsibility Distribution
Recursive lookup centralizes control within the DNS resolver. The resolver acts as the decision-maker, determining which servers to contact and in what order. The client remains passive throughout the process, waiting for the final result.
Iterative lookup distributes control across multiple servers and the client. Each server only provides guidance rather than making decisions on behalf of the requester. The client must actively follow referrals and manage the resolution path.
This difference in control significantly affects how DNS queries are processed and how much responsibility is placed on each component in the system.
Impact on Network Traffic
Recursive lookup can reduce visible network traffic for the client because only one request and one response are exchanged. However, behind the scenes, the recursive resolver may generate multiple queries to different DNS servers.
This internal processing is hidden from the user, but it still contributes to overall network activity at the resolver level.
Iterative lookup generates more direct network traffic from the client’s perspective because each referral requires a new request. This increases the number of interactions across the network, making the process more transparent but also more communication-intensive.
DNS Resolver Behavior in Recursive Mode
When operating in recursive mode, a DNS resolver behaves like a complete query processing engine. It maintains a structured workflow that includes caching, querying root servers, following referrals, and validating responses.
It also prioritizes efficiency by reusing previously cached results whenever possible. This reduces redundant queries and improves response times for frequently requested domains.
Additionally, recursive resolvers often implement load balancing and optimization techniques to distribute queries across multiple upstream servers, ensuring consistent performance.
DNS Server Behavior in Iterative Mode
In iterative mode, DNS servers behave more like reference providers than full resolution engines. They do not attempt to resolve the entire query. Instead, they respond with the best available information, usually in the form of a referral.
Each server in the chain focuses only on its specific role within the DNS hierarchy. Root servers point to top-level domain servers, which in turn point to authoritative servers.
This limited responsibility allows each server to remain lightweight and highly scalable, even when handling large volumes of queries.
Time Efficiency Comparison
Recursive lookup is generally more time-efficient from the user’s perspective because it reduces the number of visible interactions. Once a request is sent, the user waits for a single response.
Even though the resolver performs multiple internal steps, these are optimized and often cached, which reduces overall resolution time.
Iterative lookup tends to take longer because each step requires a separate request and response cycle. Network latency accumulates across these steps, especially when multiple servers must be contacted sequentially.
Scalability in Large Networks
In large-scale networks, recursive lookup scales by increasing the number of resolvers and improving caching strategies. Service providers often deploy distributed resolver systems to handle high query volumes efficiently.
Iterative lookup scales naturally across the DNS hierarchy because no single server is responsible for full resolution. Each server handles only a small portion of the workload, which keeps the system distributed and resilient.
Both approaches contribute to global DNS scalability, but they operate at different layers of the infrastructure.
Caching Efficiency Differences
Caching is significantly more effective in recursive systems because the resolver stores complete query results. This allows future requests for the same domain to be answered instantly without additional lookups.
The effectiveness of caching increases as more users query similar domains, reducing overall load on external DNS servers.
In iterative systems, caching exists but is less impactful because each step in the chain may involve different servers and partial information. As a result, repeated queries may still require multiple interactions.
System Design Philosophy
Recursive DNS lookup is designed with simplicity in mind for end users. The goal is to hide complexity and provide fast, reliable answers through a single point of contact.
Iterative lookup is designed with decentralization in mind. It ensures that no single server holds excessive responsibility and that the DNS system remains distributed across many independent nodes.
These two design philosophies work together to create a balanced DNS ecosystem that supports both performance and resilience.
Fault Isolation in Iterative Systems
One advantage of iterative lookup is better fault isolation. If one DNS server fails, it does not necessarily affect the entire system. The client can often follow alternative referral paths to reach the correct authoritative server.
This distributed structure reduces the risk of complete system failure due to a single point of breakdown.
However, it also increases complexity for the client, which must handle these failures manually or through additional logic.
Fault Management in Recursive Systems
Recursive lookup simplifies fault management by centralizing it within the resolver. If one path fails, the resolver automatically tries alternative routes without exposing this process to the client.
This makes the system more robust from the user’s perspective but increases the responsibility placed on the resolver infrastructure.
To maintain reliability, recursive resolvers are typically designed with redundancy and multiple upstream connections.
Security Risks in Recursive Environments
Recursive resolvers are common targets for attacks such as cache poisoning and spoofing because they store and reuse DNS records. If malicious data is inserted into the cache, it can affect multiple users.
To counter this, modern recursive systems use validation mechanisms to verify the authenticity of DNS responses before caching them.
Despite these protections, the centralized nature of recursive lookup makes security a critical concern.
Security Distribution in Iterative Systems
Iterative lookup reduces reliance on centralized storage, which can lower the impact of certain types of attacks. Since no single server maintains complete resolution data, compromising one node does not necessarily affect the entire system.
However, the multiple-step communication process introduces more points where data can potentially be intercepted or manipulated.
This distributed security model requires strong safeguards at every stage of the DNS hierarchy.
Latency Sources in DNS Resolution
In recursive lookup, latency primarily comes from the resolver’s internal processing and upstream queries. However, caching and optimized routing help reduce this delay significantly.
In iterative lookup, latency comes from multiple round trips between the client and different DNS servers. Each referral adds a small delay, which accumulates across the full resolution path.
This makes recursive lookup generally faster for end users, especially in high-traffic environments.
Practical Usage in Internet Systems
Most real-world internet systems rely heavily on recursive DNS lookup for end-user queries. Devices such as computers, smartphones, and routers typically send requests to recursive resolvers provided by network services.
Iterative lookup is primarily used within the DNS infrastructure itself, especially between authoritative servers and intermediate DNS nodes.
Together, these two methods form a layered system where recursive lookup handles user interaction and iterative lookup manages internal DNS navigation.
Overall Functional Relationship
Recursive and iterative lookup are not competing systems but complementary processes within DNS. Recursive lookup provides a simplified interface for users, while iterative lookup ensures efficient communication between DNS servers.
The combination of both methods allows DNS to remain fast, scalable, and reliable across the global internet infrastructure.
Each method plays a specific role in maintaining the balance between usability and distributed system design, ensuring that domain name resolution works seamlessly at all levels.
Hybrid Nature of DNS Resolution
DNS resolution in real-world systems is not purely recursive or purely iterative. Instead, it operates as a hybrid model where both methods work together at different stages of the query process. From the user’s point of view, the interaction appears recursive because a single response is received after sending one request. However, behind the scenes, the resolution often follows iterative behavior across multiple DNS servers.
This combination allows the system to remain efficient for users while still maintaining the distributed structure of the DNS hierarchy. Recursive resolvers handle user queries in a simplified way, while iterative communication takes place between DNS servers to locate the correct records.
How Recursive Resolvers Use Iterative Processes Internally
A key concept in DNS architecture is that recursive resolvers actually rely on iterative queries internally. When a recursive resolver receives a request, it does not instantly know the final answer. Instead, it begins an iterative journey across DNS layers.
It first contacts a root server, which responds with a referral. Then it queries a top-level domain server, which again responds with another referral. Finally, it reaches the authoritative server that contains the actual DNS record.
Although the resolver performs these iterative steps, the client only sees the final result. This separation of internal iterative processing and external recursive response is what makes DNS both efficient and user-friendly.
Difference in Query Initiation
In recursive lookup, the query is initiated by the client and handed over completely to the recursive resolver. The client does not participate further in the resolution process after sending the initial request.
In iterative lookup, the query is continuously initiated at each step. The client or resolver must actively send new requests based on referrals received from previous servers. This creates a chain of interactions rather than a single delegated process.
This difference in initiation significantly affects how much control the client has over the resolution process.
Role of DNS Caching Layers
Caching exists at multiple layers in DNS systems, and its behavior differs depending on whether recursive or iterative lookup is used.
In recursive systems, caching is centralized within the resolver. Once a domain is resolved, the full result is stored and reused for future queries. This reduces the need for repeated external lookups.
In iterative systems, caching may occur at individual servers along the resolution path. However, these caches are limited to their own scope and do not store complete resolution paths in a unified way.
As a result, recursive caching tends to deliver higher performance improvements compared to iterative caching.
Impact on End-User Experience
From the perspective of an end user, recursive lookup provides a smoother and more seamless experience. The user sends a request and receives a complete response without seeing the intermediate steps.
Iterative lookup, while more transparent, is not typically exposed to end users directly. If it were, users would need to handle multiple referrals and manage additional queries, which would make the experience more complex.
This difference is one of the main reasons recursive resolvers are widely deployed at the network edge.
DNS Query Time Breakdown
In recursive lookup, query time is influenced by the resolver’s efficiency, cache availability, and network conditions between the resolver and authoritative servers. Most of the complexity is hidden from the client.
In iterative lookup, query time increases with each additional step in the resolution chain. Every referral introduces a new round-trip delay, which accumulates across the entire process.
This makes recursive lookup more predictable in terms of response time, while iterative lookup can vary depending on network conditions and server availability.
Dependency Relationships in DNS Lookup
Recursive lookup creates a dependency relationship between the client and the recursive resolver. The client depends entirely on the resolver to obtain accurate results.
Iterative lookup creates a distributed dependency chain. Each DNS server depends only on the next server in the hierarchy to continue the resolution process.
This distributed dependency model ensures that no single server is responsible for the entire process, improving resilience at the cost of increased complexity.
Scalability Through Recursive Deployment
Recursive resolvers scale horizontally by increasing the number of resolver instances. Large networks often deploy multiple recursive resolvers to distribute query loads efficiently.
As demand increases, additional resolvers can be added without changing the underlying DNS hierarchy. This makes recursive systems highly adaptable to growing internet traffic.
Caching further improves scalability by reducing redundant external queries.
Scalability Through Iterative Distribution
Iterative lookup scales through the inherent structure of the DNS hierarchy. Each server only handles a specific portion of the domain space, which prevents overload on any single node.
Root servers, top-level domain servers, and authoritative servers each handle different responsibilities, ensuring that no single layer becomes a bottleneck.
This distributed structure is one of the foundational strengths of DNS as a global system.
Failure Recovery Mechanisms
Recursive resolvers include built-in recovery mechanisms to handle failures. If a DNS server does not respond, the resolver automatically retries using alternative servers or cached data.
This automatic recovery reduces the likelihood of query failure being exposed to the client.
In iterative lookup, failure recovery is less automated. Each step depends on successful responses from previous servers, and additional logic is required to handle missing or unreachable nodes.
Propagation of DNS Information
DNS information propagates differently in recursive and iterative systems. In recursive lookup, information spreads through resolver caching, meaning frequently accessed records become widely available at resolver level.
In iterative lookup, information remains localized within each server’s scope. There is no unified propagation mechanism beyond the hierarchical structure of DNS itself.
This difference affects how quickly DNS changes become visible across the internet.
Security Architecture Differences
Recursive lookup relies heavily on the security of the resolver. If the resolver is compromised, cached results can be manipulated, affecting many users at once.
To mitigate this risk, security extensions and validation techniques are used to ensure authenticity of DNS responses.
Iterative lookup distributes security across multiple servers. While this reduces dependency on a single point, it increases the number of communication points that must be protected individually.
Traffic Visibility and Monitoring
Recursive lookup reduces traffic visibility at the client level because all communication beyond the initial request is hidden inside the resolver.
This makes monitoring easier from a user perspective but concentrates visibility at resolver infrastructure.
Iterative lookup provides full visibility of each step in the resolution process. Every referral is observable, which can be useful for debugging and network analysis.
However, this also increases the amount of traffic that must be managed and analyzed.
DNS System Efficiency Balance
The combination of recursive and iterative lookup creates a balance between efficiency and decentralization. Recursive lookup optimizes user experience by simplifying interactions, while iterative lookup maintains the distributed nature of DNS infrastructure.
Without recursive resolvers, users would face complex multi-step queries. Without iterative mechanisms, DNS servers would become overloaded with full resolution responsibilities.
Together, they ensure that DNS remains both scalable and practical.
Long-Term Stability of DNS Architecture
The DNS system has remained stable for decades largely because of the separation between recursive and iterative processes. This separation allows continuous scaling of the internet without redesigning the entire naming system.
Recursive resolvers can evolve independently to improve performance and security, while iterative DNS hierarchy remains stable and standardized.
This modular design is one of the key reasons DNS continues to function reliably at global scale.
Functional Interaction
Recursive and iterative lookup are deeply interconnected processes that operate at different layers of DNS resolution. Recursive lookup simplifies the user experience by handling full resolution externally, while iterative lookup ensures structured navigation within the DNS hierarchy.
Their interaction forms a complete system where user simplicity and infrastructure efficiency coexist. Recursive lookup handles the interface layer, and iterative lookup manages the structural backbone of DNS communication.
This layered cooperation is what allows domain name resolution to function quickly, reliably, and consistently across the entire internet.
Advanced DNS Resolver Optimization Techniques
Modern recursive DNS resolvers are not just simple query handlers; they are highly optimized systems designed to reduce latency and improve reliability. One major optimization technique is prefetching, where frequently accessed domain records are refreshed before they expire. This ensures that popular domains remain available in cache without interruption.
Another optimization is load balancing across multiple upstream DNS servers. Instead of relying on a single authoritative path, recursive resolvers distribute queries intelligently to avoid congestion and improve response times. These enhancements make recursive lookup even faster in real-world environments.
Iterative lookup does not include such centralized optimizations because each server only handles a small portion of the query. Any optimization is local to that server and does not extend across the full resolution path.
DNS Forwarding and Its Relationship to Recursive Lookup
DNS forwarding is a mechanism closely related to recursive lookup. In this setup, a DNS server forwards queries it cannot resolve to another recursive resolver instead of handling full recursion itself. This creates a layered system where multiple recursive resolvers may exist in sequence.
This forwarding chain still behaves recursively from the user’s perspective, but internally it may involve multiple delegated resolvers working together. The goal is to reduce workload on local servers while still ensuring complete resolution.
Iterative lookup, in contrast, does not involve forwarding in the same way. Each server directly responds with referrals rather than passing responsibility forward.
Time-to-Live and Its Impact on DNS Behavior
Time-to-Live (TTL) is a critical factor that influences both recursive and iterative DNS systems. TTL defines how long a DNS record can be stored in cache before it must be refreshed.
In recursive lookup, TTL directly affects caching efficiency. A higher TTL means fewer external queries and faster response times for repeated requests. Once the TTL expires, the resolver must perform a fresh lookup.
In iterative lookup, TTL influences how long individual servers can reuse stored data, but because each step is independent, the overall impact is less centralized.
Consistency of DNS Data Across Systems
Consistency in DNS refers to how uniformly domain information is updated across the internet. Recursive resolvers may temporarily serve outdated data if their cache has not expired, leading to slight inconsistencies during updates.
Iterative lookup reduces this risk because each query directly references authoritative sources during the resolution process. However, it also increases lookup time since caching benefits are reduced in some cases.
This trade-off between speed and real-time accuracy is an important aspect of DNS design.
Role of Root Servers in Iterative Resolution
Root servers play a foundational role in iterative DNS lookup. They do not store actual domain-to-IP mappings but instead provide directional guidance to top-level domain servers.
When a query reaches a root server, it responds with a referral pointing to the appropriate next-level server. This ensures that the resolution process stays organized and follows a structured hierarchy.
Recursive resolvers interact with root servers as part of their internal iterative process, but end users never directly see this interaction.
Top-Level Domain Servers and Their Function
Top-level domain servers handle specific domain categories and act as intermediaries between root servers and authoritative servers. They provide further referrals that narrow down the search for the final DNS record.
In iterative lookup, these servers are essential because they guide the query step-by-step toward the final destination.
In recursive lookup, they are part of the internal resolution chain managed entirely by the resolver.
Authoritative DNS Servers and Final Resolution
Authoritative DNS servers are the final source of truth in the DNS hierarchy. They store actual mappings between domain names and IP addresses.
When a query reaches an authoritative server, it receives a direct and final response. This marks the completion of both recursive and iterative lookup processes.
In recursive systems, this response is returned to the resolver and then passed to the client. In iterative systems, it is returned directly to the requester.
Latency Variation in Real-World Networks
In real-world conditions, DNS latency can vary significantly depending on network distance, server load, and caching status. Recursive lookup reduces perceived latency by minimizing visible interactions.
However, internal resolver delays may still exist depending on upstream server responsiveness.
Iterative lookup experiences more noticeable latency variation because each step depends on successful communication with different servers, often located in different geographic regions.
Geographical Distribution of DNS Servers
DNS infrastructure is globally distributed to improve performance and reliability. Recursive resolvers are often placed close to end users to reduce query travel distance.
Iterative servers such as root, top-level, and authoritative servers are distributed across multiple regions to ensure redundancy and global accessibility.
This geographic distribution ensures that both recursive and iterative processes can function efficiently regardless of user location.
DNS Security Extensions and Their Role
Security extensions such as validation mechanisms are used to protect DNS data integrity. These systems help ensure that responses received during recursive lookup are authentic and have not been tampered with.
In recursive systems, these security checks are crucial because the resolver stores and redistributes cached data.
In iterative systems, security is enforced at each step of the communication chain to ensure that referrals are trustworthy.
Query Path Transparency
Iterative lookup provides full transparency of the query path because each referral is visible to the requester. This can be useful for debugging, network analysis, and understanding DNS structure.
Recursive lookup hides this path from the client, providing only the final result. While this improves simplicity, it reduces visibility into the resolution process.
This difference reflects the trade-off between usability and transparency in DNS design.
Resource Utilization in DNS Systems
Recursive resolvers require more computational resources because they perform full resolution tasks, maintain caches, and manage multiple connections simultaneously.
Iterative servers use fewer resources per query because they only respond with referrals and do not perform full resolution.
This makes iterative servers lightweight and highly scalable, while recursive resolvers are more resource-intensive but user-friendly.
Impact of Network Congestion
Network congestion affects both recursive and iterative lookup but in different ways. Recursive lookup may experience delays at the resolver level, but the client only sees a single delay.
Iterative lookup is more sensitive to congestion because each step depends on successful communication between different servers. Congestion at any point in the chain can slow down the entire process.
DNS Load Distribution Strategies
To manage global DNS traffic, recursive resolvers use strategies such as query distribution, caching optimization, and server redundancy. These techniques help maintain consistent performance even under heavy load.
Iterative DNS systems naturally distribute load across hierarchical levels, ensuring no single server is overwhelmed by full query processing responsibilities.
Together, these strategies maintain DNS stability across the internet.
Protocol Efficiency in DNS Communication
DNS communication relies on lightweight query-response protocols designed for speed and efficiency. Recursive lookup reduces the number of visible protocol exchanges by consolidating them within the resolver.
Iterative lookup involves multiple protocol exchanges across different servers, increasing communication overhead but maintaining structural clarity.
Both approaches are optimized for different layers of the system.
Long-Term Evolution of DNS Lookup Methods
Over time, DNS has evolved to prioritize user experience while maintaining distributed architecture. Recursive lookup became dominant at the user level due to its simplicity and speed.
Iterative lookup remains essential for maintaining the structural integrity of DNS and ensuring that no single system controls the entire namespace.
This evolution reflects a balance between centralized convenience and decentralized design.
Structural Understanding
Recursive and iterative DNS lookup together form a unified system that enables global domain resolution. Recursive lookup simplifies interaction for users by handling complete resolution externally, while iterative lookup ensures structured navigation within the DNS hierarchy.
This layered interaction allows DNS to scale globally, remain resilient under load, and provide fast responses to billions of daily queries. The combination of both methods ensures that domain name resolution remains one of the most stable and efficient systems on the internet.
DNS Caching Invalidation and Freshness Control
One of the most important challenges in DNS systems is ensuring that cached data does not become outdated for too long. In recursive lookup, caching improves performance significantly, but it also introduces the risk of stale information being served if updates occur on authoritative servers. To manage this, DNS relies heavily on controlled expiration mechanisms that force resolvers to refresh data after a defined period.
When a cached record expires, the recursive resolver must repeat the resolution process to obtain updated information. This ensures that users eventually receive accurate results even after changes to domain records. However, there is always a trade-off between performance and freshness, since longer caching improves speed but delays updates.
In iterative lookup, freshness is naturally higher because each query tends to move closer to authoritative sources. However, since caching is less centralized, repeated queries may still re-trigger the full resolution process more often than in recursive systems.
DNS Query Aggregation Behavior
Recursive resolvers often aggregate similar queries to reduce redundant processing. When multiple users request the same domain within a short time frame, the resolver can reuse ongoing resolution efforts or cached results instead of initiating separate upstream queries.
This behavior significantly reduces network load and improves efficiency in high-traffic environments. It also helps prevent unnecessary repeated communication with authoritative servers.
Iterative lookup does not support this kind of aggregation in a centralized way because each request is handled independently through referral-based steps. As a result, identical queries may still follow similar resolution paths without shared optimization.
Impact of DNS Architecture on Application Performance
Applications rely heavily on DNS resolution speed to load resources efficiently. In recursive systems, faster resolution leads directly to improved application responsiveness. Since the recursive resolver returns a complete answer in a single response, applications can quickly proceed with establishing connections.
In iterative systems, delays accumulate due to multiple referral steps, which can affect application performance if DNS resolution is exposed directly. However, most modern applications rely on recursive resolvers, ensuring minimal impact on user experience.
This separation allows applications to remain simple while DNS infrastructure handles complexity in the background.
Load Distribution Across DNS Ecosystem
The DNS ecosystem is designed to distribute workload across different layers. Recursive resolvers handle user-facing queries, while authoritative and hierarchical servers handle structured data distribution.
This division ensures that no single part of the system becomes overwhelmed. Recursive systems absorb user demand, while iterative systems ensure orderly navigation through DNS layers.
The balance between these two approaches allows DNS to support global-scale traffic without collapsing under load.
Redundancy and Failover Mechanisms
Redundancy is a key principle in DNS design. Recursive resolvers often maintain multiple upstream connections so that if one server fails, another can take over without disrupting the query process.
This failover capability ensures high reliability and continuous service availability. From the user’s perspective, the process remains seamless even if internal failures occur.
In iterative lookup, redundancy exists at each hierarchical level. Multiple root, top-level, and authoritative servers ensure that no single failure point disrupts the entire system.
DNS Resolution Time Variability Factors
Several factors influence how long DNS resolution takes. These include network distance, server load, caching status, and availability of DNS records.
In recursive lookup, most of this variability is hidden from the user due to caching and optimized resolver behavior. The response time tends to be more consistent.
In iterative lookup, variability is more noticeable because each step depends on real-time communication with different servers. Any delay at one stage directly affects the total resolution time.
Interaction Between DNS Layers
DNS layers interact in a structured hierarchy. Root servers provide directional guidance, top-level servers refine the query path, and authoritative servers deliver final answers.
Recursive resolvers interact with all these layers internally, while iterative lookup exposes this interaction step-by-step to the requester.
This layered interaction ensures that DNS remains both scalable and organized across the global internet infrastructure.
Protocol Efficiency and Message Overhead
Recursive lookup reduces message overhead at the client level by consolidating multiple interactions into a single response. This improves efficiency from the user’s perspective.
Iterative lookup increases message overhead because each referral requires a separate request-response cycle. While this adds complexity, it ensures clarity in how DNS resolution progresses.
Both methods are optimized for different goals within the system architecture.
DNS Security Validation in Modern Systems
Modern DNS systems incorporate validation mechanisms to ensure data integrity. Recursive resolvers often verify responses before caching them, preventing malicious or incorrect data from being stored.
Iterative systems apply validation at each step of the query chain, ensuring that referrals are accurate and trustworthy before proceeding further.
This layered security approach strengthens the overall resilience of DNS against manipulation and attack.
Global Distribution of DNS Infrastructure
DNS infrastructure is distributed across the globe to ensure fast and reliable access for users everywhere. Recursive resolvers are typically placed closer to users to reduce latency.
Hierarchical DNS servers, including root and authoritative servers, are distributed across multiple geographic regions to ensure redundancy and availability.
This global distribution supports both recursive efficiency and iterative structural integrity.
Evolution of DNS Resolution Design
DNS resolution design has evolved to prioritize user simplicity without sacrificing system scalability. Recursive lookup became the dominant model at the user level because it hides complexity and improves performance.
Iterative lookup remains essential for maintaining the underlying structure of DNS, ensuring that no single entity controls the entire resolution process.
This evolution reflects a balance between usability and decentralized architecture.
Final Conclusion
DNS recursive and iterative lookup are two interconnected methods that together form the foundation of domain name resolution on the internet. Recursive lookup focuses on simplifying the user experience by handling complete query resolution through a single resolver, returning final results without exposing intermediate steps. It emphasizes speed, caching efficiency, and ease of use.
Iterative lookup, on the other hand, is responsible for the structured navigation of DNS hierarchy. It distributes responsibility across multiple servers, each providing partial information that guides the query toward its destination. This approach ensures decentralization, scalability, and transparency within the DNS system.
While recursive lookup optimizes performance for end users, iterative lookup maintains the structural integrity of the global DNS infrastructure. Together, they create a balanced system where simplicity and complexity coexist efficiently. This dual mechanism ensures that DNS remains fast, reliable, and scalable, supporting billions of queries every day across the global internet without breaking its foundational design.