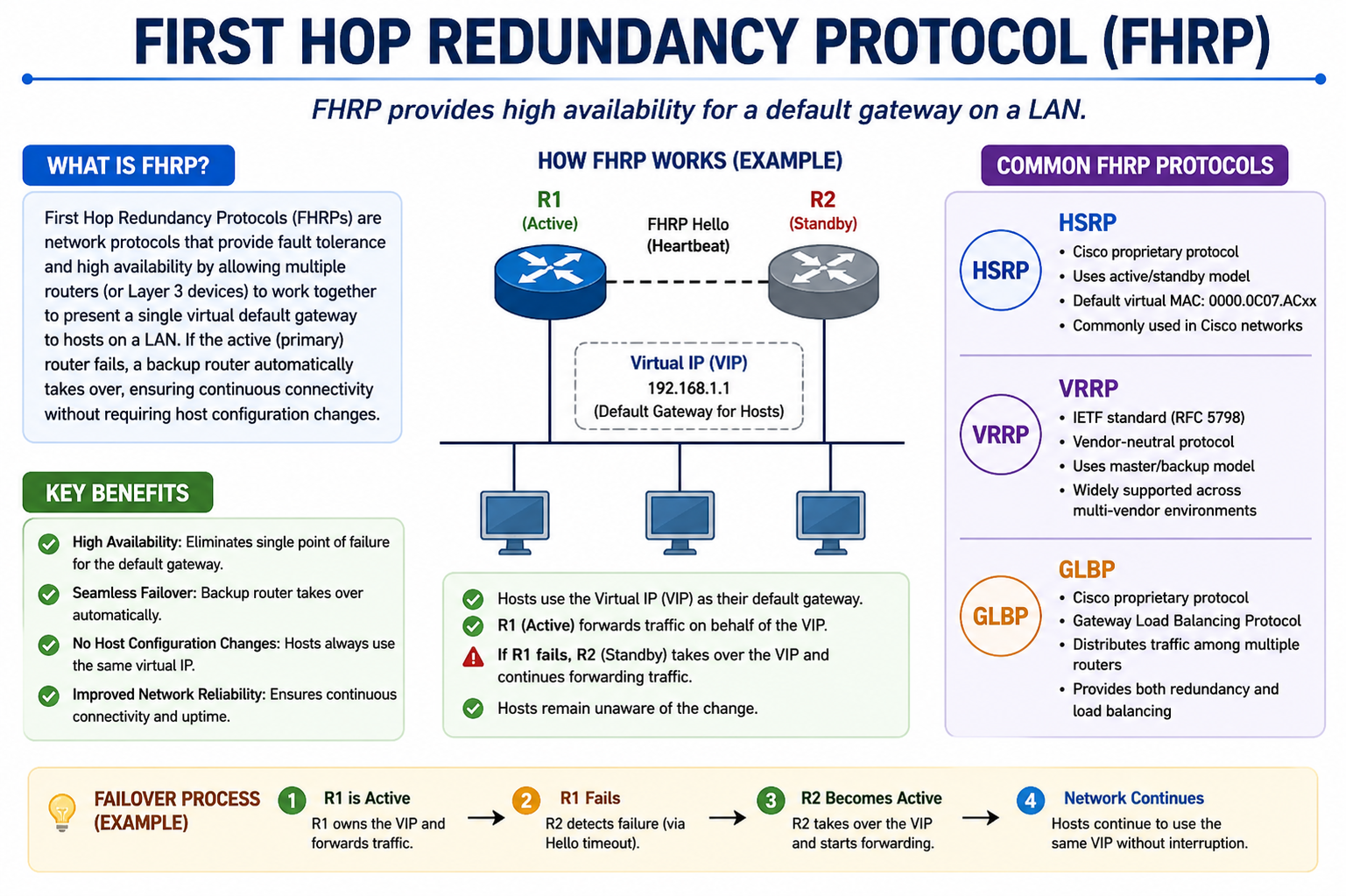
First Hop Redundancy Protocol is a collection of network protocols designed to increase the reliability and availability of the default gateway in an IP network. It is mainly used in local area networks where devices depend on a single gateway router to reach destinations outside their subnet. In traditional network design, this gateway becomes a critical single point of failure. If it goes down, all connected devices lose access to external networks. FHRP solves this issue by introducing redundancy at the gateway level, allowing multiple routers to collaborate and provide a continuous forwarding service even if one device fails.
Need for First Hop Redundancy Protocol
In a standard network setup, every host is configured with a default gateway, which is the IP address of a router responsible for forwarding traffic beyond the local subnet. While this design is simple, it introduces a significant risk. If the default gateway router fails due to hardware issues, software errors, power loss, or maintenance, all devices relying on it lose external connectivity immediately. This can cause severe disruption in business operations, communication systems, and critical services. FHRP was developed to eliminate this dependency on a single device by introducing a redundant system where multiple routers share the responsibility of acting as the gateway.
Concept of Redundancy in FHRP
The core idea behind FHRP is redundancy, which means having backup systems ready to take over when the primary system fails. In the context of networking, redundancy ensures that there is no single point of failure at the first hop of packet forwarding. Multiple routers are configured to work together as a group and present themselves as a single virtual gateway to all connected devices. This virtual gateway is what end devices use as their default gateway, even though behind the scenes multiple physical routers are involved in handling the traffic.
Virtual Gateway and IP Addressing
One of the most important components of FHRP is the concept of a virtual IP address. Instead of each host pointing to a physical router’s IP address, they use a shared virtual IP address that represents the entire group of routers. This virtual IP does not belong to any single device permanently. Instead, it is dynamically managed by the routers in the redundancy group. One router actively uses this virtual IP to forward traffic, while others monitor its status and remain ready to take over if needed. This abstraction ensures that end devices remain unaware of any changes in the actual physical gateway.
Active and Standby Roles in FHRP
Within an FHRP group, routers are assigned specific roles to manage traffic efficiently. One router is designated as the active or primary router, which handles all the forwarding tasks for the virtual gateway. The remaining routers are placed in standby or backup roles. These standby routers continuously monitor the active router to ensure it is functioning properly. If the active router fails or becomes unreachable, one of the standby routers automatically transitions into the active role. This process happens quickly and transparently, minimizing network downtime and avoiding manual intervention.
How FHRP Maintains Communication
FHRP relies on periodic communication between routers in the redundancy group. These communications are often in the form of hello messages or keepalive signals. The active router regularly sends these signals to inform the standby routers that it is still operational. If the standby routers stop receiving these signals within a defined interval, they assume that the active router has failed. At this point, an election or failover process is triggered to select a new active router. This mechanism ensures continuous monitoring and rapid response to failures.
Failover Mechanism and Convergence
Failover is a critical process in FHRP where responsibility for the virtual gateway is transferred from one router to another. When the active router fails, the standby router with the highest priority or best eligibility becomes the new active router. The transition is designed to be fast so that end devices do not experience noticeable disruption. Convergence refers to the time taken for the network to fully adapt to this change. A well-designed FHRP implementation ensures very low convergence time, allowing traffic to resume almost immediately through the new active gateway.
Role of ARP in FHRP Operation
Address Resolution Protocol (ARP) plays an important role in how FHRP functions. When a host sends traffic to the virtual gateway, it uses ARP to resolve the virtual IP address into a MAC address. The active router responds to this ARP request with its own MAC address or a virtual MAC address assigned to the group. If a failover occurs and a new router becomes active, it continues to use the same virtual MAC address or sends gratuitous ARP messages to update network devices. This ensures that hosts do not need to update their gateway settings during a transition.
Election Process Among Routers
In many FHRP implementations, routers participate in an election process to determine which device becomes the active gateway. This election is typically based on predefined priorities, router IDs, or other metrics such as uptime. The router with the highest priority is usually selected as the active device. If priorities are equal, additional criteria such as IP addresses may be used to break the tie. This structured selection process ensures predictable behavior and allows network administrators to control which router should normally handle traffic.
Load Sharing Possibilities in FHRP
While the primary purpose of FHRP is redundancy, some implementations also support load sharing. Instead of one router handling all traffic and others remaining idle, multiple routers can actively share forwarding responsibilities for different virtual gateways. This improves overall network efficiency and utilization of resources. However, even in load-sharing scenarios, redundancy is still maintained so that if one router fails, the remaining devices continue to handle traffic without interruption.
Advantages of Using FHRP
FHRP provides several important benefits in network environments. It significantly improves network reliability by eliminating single points of failure at the gateway level. It enhances fault tolerance by allowing automatic failover without manual intervention. It also improves user experience by ensuring continuous connectivity even during hardware or software failures. In enterprise environments, this level of reliability is critical for maintaining business operations and minimizing downtime. Additionally, FHRP simplifies network management by allowing administrators to configure a single virtual gateway instead of managing multiple individual gateway settings on end devices.
Challenges and Considerations in FHRP Deployment
Although FHRP provides strong benefits, it also requires careful planning and configuration. Incorrect setup can lead to suboptimal failover behavior or network loops. Timing parameters such as hello intervals and hold timers must be tuned properly to balance fast failover with network stability. Hardware compatibility between routers is also important to ensure smooth operation. Additionally, network administrators must consider scalability when designing redundancy groups in large networks to avoid unnecessary complexity.
Use Cases of FHRP in Modern Networks
FHRP is widely used in enterprise networks, data centers, and service provider environments where high availability is essential. It is particularly important in environments where even a few minutes of downtime can lead to financial loss or service disruption. Examples include banking systems, online services, corporate networks, and cloud infrastructure. In these scenarios, FHRP ensures that network traffic continues to flow smoothly even in the event of hardware failures or maintenance activities.
FHRP Functionality
First Hop Redundancy Protocol provides a structured and efficient way to ensure gateway availability in IP networks. By combining multiple routers into a single logical gateway, it removes the dependency on a single device and introduces automatic failover capabilities. Through mechanisms such as virtual IP addressing, active and standby roles, periodic communication, and fast convergence, FHRP maintains continuous network connectivity even during failures. It is a fundamental technology in modern networking design, especially in environments where reliability and uptime are critical requirements.
Types of First Hop Redundancy Protocol (FHRP)
First Hop Redundancy Protocol is not a single protocol but a category that includes several implementations designed to achieve the same goal of gateway redundancy. The most commonly used types are Hot Standby Router Protocol, Virtual Router Redundancy Protocol, and Gateway Load Balancing Protocol. Each of these protocols works in a slightly different way, but all of them ensure that a backup router is available in case the primary gateway fails. The choice of protocol depends on network requirements, vendor support, and whether load balancing is needed in addition to redundancy.
Hot Standby Router Protocol (HSRP)
Hot Standby Router Protocol is a Cisco proprietary FHRP implementation. It is widely used in Cisco-based networks to provide high availability for IP networks. In HSRP, routers are grouped together and assigned a virtual IP address that acts as the default gateway for all connected hosts. Within the group, one router is elected as the active router, while another is selected as the standby router. The active router handles all traffic, while the standby router remains in a ready state to take over if the active router fails. HSRP uses hello messages to monitor the status of the active router and triggers failover when necessary.
HSRP also uses a priority system to determine which router becomes active. The router with the highest priority value is selected as the active gateway. If priorities are equal, the router with the highest IP address is chosen. HSRP ensures fast convergence and minimal downtime, making it suitable for enterprise environments where network availability is critical.
Virtual Router Redundancy Protocol (VRRP)
Virtual Router Redundancy Protocol is an open standard FHRP defined by the Internet Engineering Task Force. Unlike HSRP, which is Cisco-specific, VRRP can be used across different vendors, making it more flexible in heterogeneous network environments. VRRP operates similarly by creating a virtual router that represents multiple physical routers.
In VRRP, one router is elected as the master router, while others act as backups. The master router is responsible for forwarding packets sent to the virtual IP address. If the master router fails, one of the backup routers automatically takes over as the new master. VRRP also uses priority values to determine the master router, with the highest priority router becoming the active device. One advantage of VRRP is its simplicity and interoperability, which makes it widely adopted in mixed vendor environments.
Gateway Load Balancing Protocol (GLBP)
Gateway Load Balancing Protocol is another Cisco proprietary FHRP that goes beyond simple redundancy and introduces load balancing capabilities. Unlike HSRP and VRRP, where only one router actively handles traffic, GLBP allows multiple routers in the same group to actively forward traffic simultaneously. This improves network efficiency by distributing the load across multiple devices.
In GLBP, one router acts as the active virtual gateway, while others act as active virtual forwarders. The active virtual gateway assigns different virtual MAC addresses to each forwarder and distributes traffic among them. If one forwarder fails, the active virtual gateway reassigns its traffic to remaining forwarders. This combination of redundancy and load balancing makes GLBP more resource-efficient in certain environments, especially where traffic distribution is important.
Comparison of FHRP Protocols
Although HSRP, VRRP, and GLBP serve the same fundamental purpose, they differ in design and functionality. HSRP is widely used in Cisco environments but lacks interoperability with other vendors. VRRP is an open standard and is more flexible in mixed environments. GLBP provides additional load balancing features that the other two protocols do not offer. In terms of failover behavior, all three provide automatic switching, but GLBP adds better resource utilization. The choice between them depends on whether simplicity, interoperability, or load balancing is the primary requirement.
States in FHRP Operation
FHRP protocols use different operational states to manage router roles and transitions. These states define how routers behave at any given time in the redundancy group. In HSRP, for example, common states include initial, listen, speak, standby, and active. The active state represents the router currently forwarding traffic, while standby indicates readiness to take over. VRRP uses master and backup states, which are simpler in structure. These states ensure that routers do not conflict with each other and that only one device forwards traffic for a given virtual IP at a time, except in load balancing scenarios like GLBP.
Timers and Their Importance
Timers play a critical role in FHRP operation. Hello timers determine how frequently routers send status messages to each other. Hold timers define how long a router should wait before declaring the active router as failed if no hello messages are received. Proper tuning of these timers is essential for balancing fast failover with network stability. If timers are set too low, false failovers may occur due to temporary network delays. If they are too high, failover may be slow, causing noticeable downtime. Therefore, careful configuration is required based on network conditions.
Failover Process in Detail
The failover process begins when the standby or backup router detects that the active router is no longer responding to hello messages. Once this condition is confirmed, an election process begins to select a new active router. The selected router then assumes responsibility for the virtual IP address and begins forwarding traffic. It may also send gratuitous ARP messages to update the MAC address table of connected devices. This ensures that traffic is quickly redirected to the new active router without requiring manual configuration changes on end devices.
Security Considerations in FHRP
FHRP protocols can be vulnerable to certain types of attacks if not properly secured. One potential risk is spoofing, where an unauthorized device attempts to impersonate a legitimate router in the redundancy group. To prevent this, authentication mechanisms can be configured between routers. This ensures that only trusted devices can participate in the FHRP group. Another consideration is protecting against misconfiguration, which can lead to routing loops or inconsistent gateway behavior. Proper network design and monitoring are essential to maintain secure FHRP operations.
Best Practices for FHRP Deployment
When deploying FHRP in a network, several best practices should be followed. Routers should be placed in physically separate locations to avoid a single point of failure. Priority values should be carefully configured to ensure that the most capable router becomes the active gateway under normal conditions. Preemption should be enabled when necessary so that a higher-priority router can reclaim its active role after recovery. Timers should be adjusted based on network performance requirements. Regular testing of failover scenarios is also important to ensure that redundancy works as expected.
Common Issues and Troubleshooting in FHRP
Some common issues in FHRP environments include misconfigured priorities, mismatched timers, and connectivity problems between routers. If routers cannot communicate properly, failover may not occur as expected. Another issue is ARP table inconsistency on end devices, which can cause temporary connectivity loss during failover. Troubleshooting typically involves checking interface status, verifying FHRP configurations, and analyzing hello message exchanges. Network monitoring tools can also help detect anomalies in redundancy behavior.
Role of FHRP in Modern Networking
In modern network design, FHRP is a foundational technology for achieving high availability. It is commonly used in enterprise networks, data centers, and cloud environments where uninterrupted connectivity is essential. As networks become more complex and dependent on continuous uptime, FHRP ensures that gateway failures do not disrupt services. It is often combined with other redundancy technologies at higher layers to create fully resilient network architectures.
FHRP Concepts
First Hop Redundancy Protocol represents a critical component of network reliability and fault tolerance. Through different implementations like HSRP, VRRP, and GLBP, it provides flexible options for achieving gateway redundancy and, in some cases, load balancing. By using virtual IP addressing, role-based router assignments, and fast failover mechanisms, FHRP ensures that network communication remains uninterrupted even during failures. Proper design, configuration, and monitoring are essential to maximize its effectiveness and maintain stable network performance.
FHRP Operation in Real Network Environments
In real-world networking environments, First Hop Redundancy Protocol plays a silent but extremely important role in maintaining continuous connectivity. End devices such as computers, servers, IP phones, and IoT systems are usually unaware that FHRP is operating in the background. They simply send traffic to a default gateway, assuming it is a single router. Behind the scenes, however, multiple routers are working together to ensure that this gateway is always available. This hidden complexity is what makes FHRP powerful, because it improves reliability without changing how end devices are configured or operated.
In enterprise networks, FHRP is typically deployed at the distribution layer or core layer, where redundancy is most critical. These layers handle large volumes of traffic and connect multiple access networks. Any failure at this level can impact an entire organization, which is why redundant gateway design is essential. FHRP ensures that even if one distribution router goes down, another immediately takes over without affecting user sessions or active connections.
FHRP and Network Convergence Behavior
Network convergence refers to the time it takes for all routers and devices in a network to reach a consistent forwarding state after a change occurs, such as a failure. In FHRP, convergence is a key performance factor because users should not experience noticeable delays when a failover happens. The protocol is designed to detect failures quickly and switch roles between routers in a matter of seconds or even milliseconds, depending on configuration.
During convergence, several processes occur almost simultaneously. The standby router detects missing hello messages, triggers an election or priority check, assumes the active role, and begins forwarding traffic. At the same time, it updates network devices using ARP announcements so that traffic is correctly directed. This coordinated process ensures that packet loss is minimized and applications continue functioning smoothly.
FHRP and Layer 2 and Layer 3 Interaction
FHRP operates primarily at Layer 3 of the OSI model, but it also interacts closely with Layer 2 switching mechanisms. When a host sends traffic to a gateway, it uses ARP to resolve the virtual IP into a MAC address. The active FHRP router responds with a virtual or shared MAC address that represents the entire redundancy group.
Switches in the network maintain MAC address tables based on this information. If a failover occurs, the MAC address association may need to be updated quickly. FHRP handles this through gratuitous ARP messages, which inform switches and hosts of the new active router. This tight integration between Layer 2 and Layer 3 ensures smooth traffic redirection during failover events.
Importance of Prioritization in FHRP Design
Prioritization is a fundamental concept in FHRP because it determines which router should take the active role under normal conditions. Each router in the redundancy group is assigned a priority value, and the router with the highest value becomes the preferred active gateway. This allows network administrators to control traffic flow and optimize resource usage.
For example, a more powerful router with higher processing capacity and better connectivity can be given a higher priority so that it handles most of the traffic. Backup routers with lower specifications remain in standby mode unless needed. This structured approach ensures efficient utilization of network resources while maintaining redundancy.
Some implementations also support preemption, which allows a higher-priority router to reclaim the active role after it recovers from a failure. This ensures that the network always operates in its optimal configuration rather than remaining on a less preferred backup device.
Load Distribution in Advanced FHRP Configurations
While basic FHRP focuses on redundancy, advanced configurations can also improve load distribution across multiple routers. This is especially relevant in environments with high traffic volumes, such as data centers or large enterprise networks. Instead of keeping backup routers idle, traffic can be distributed across multiple active devices.
In such setups, different virtual gateways may be created for different network segments, allowing each router to actively participate in forwarding traffic. This reduces congestion and improves overall network performance. Load distribution also ensures that no single router becomes a bottleneck, which is important for scalability.
FHRP in High Availability Network Design
High availability is a key goal in modern network design, and FHRP is one of the foundational technologies that enable it. High availability means that a system remains operational even in the presence of failures. FHRP contributes to this by ensuring that gateway services are always accessible.
In combination with other technologies such as link aggregation, dynamic routing protocols, and redundant physical links, FHRP helps build a fully resilient network infrastructure. It is often used alongside routing protocols like OSPF or EIGRP, which handle path selection beyond the local gateway. Together, these technologies create multiple layers of redundancy that protect against both local and wide-area failures.
FHRP Behavior During Maintenance and Upgrades
One of the practical advantages of FHRP is its ability to support planned maintenance without causing downtime. Network administrators can manually switch the active role from one router to another before performing maintenance tasks. This controlled failover ensures that users do not experience interruptions.
Once maintenance is complete, the original router can be restored and either reassume the active role automatically or remain in standby mode, depending on configuration. This flexibility makes FHRP highly valuable in environments where continuous operation is required, such as financial systems, healthcare networks, and cloud services.
Scalability Considerations in FHRP Deployment
As networks grow, FHRP configurations must also scale accordingly. Large networks may require multiple redundancy groups to handle different segments or departments. Each group operates independently, but they must be carefully designed to avoid unnecessary complexity or overlapping configurations.
Scalability also involves ensuring that timers, priorities, and failover policies remain consistent across the network. Poorly designed FHRP deployments can lead to instability or unpredictable failover behavior. Therefore, careful planning is required when expanding redundancy across multiple sites or large enterprise environments.
FHRP and Network Monitoring Systems
Monitoring is an important aspect of maintaining FHRP performance. Network monitoring tools can track the status of active and standby routers, detect failover events, and alert administrators to potential issues. These systems help ensure that redundancy is functioning correctly and provide visibility into network health.
Monitoring also helps identify recurring failures or instability in specific routers, allowing proactive maintenance before major outages occur. In modern networks, automated monitoring systems are often integrated with alerting and logging mechanisms to provide real-time insights into FHRP behavior.
Future Role of FHRP in Networking
As networks continue to evolve with cloud computing, virtualization, and software-defined networking, the role of FHRP remains important but is also adapting. Virtualized environments often require flexible redundancy mechanisms that can operate across physical and virtual infrastructure. FHRP concepts are being integrated into these environments to maintain gateway availability even in dynamic, software-driven networks.
In some modern architectures, redundancy is managed at a higher abstraction level, but the fundamental principle of first-hop redundancy remains essential. The idea of eliminating single points of failure at the gateway continues to be a core requirement in all types of network design.
Overview of FHRP Concepts
First Hop Redundancy Protocol is a foundational networking concept that ensures continuous availability of the default gateway in IP networks. It works by grouping multiple routers into a single logical gateway and managing their roles through active and standby states. Through mechanisms such as priority selection, failover detection, virtual IP addressing, and rapid convergence, it prevents service disruption caused by router failures.
Across different implementations such as HSRP, VRRP, and GLBP, the core objective remains the same: maintaining uninterrupted network access for end users. Whether used for simple redundancy or advanced load balancing, FHRP plays a crucial role in building stable, resilient, and high-performing network infrastructures.
FHRP in Data Center Environments
In modern data centers, First Hop Redundancy Protocol plays a critical role in ensuring uninterrupted connectivity between servers, storage systems, and external networks. Data centers operate with extremely high traffic loads and require near-zero downtime, which makes gateway redundancy essential. FHRP is typically deployed at the leaf or aggregation layer in data center architectures, where multiple redundant routers or switches provide default gateway services to large numbers of connected devices.
In these environments, even a brief interruption in gateway availability can cause application failures, transaction errors, or service outages. FHRP prevents such scenarios by ensuring that if one gateway device fails, another immediately takes over without requiring any manual intervention or reconfiguration of hosts. This seamless transition is essential for maintaining service-level agreements in enterprise and cloud environments.
FHRP in Virtualized and Cloud Networks
With the rise of virtualization and cloud computing, network infrastructure has become more dynamic and software-driven. Virtual machines and containers often move between physical hosts, which requires consistent and highly available gateway services. FHRP adapts to these environments by providing a stable virtual gateway that remains consistent even as underlying infrastructure changes.
In cloud and virtual networks, FHRP concepts are often implemented within virtual switches and software-defined networking platforms. The same principles of active and standby roles, virtual IP addressing, and failover detection are applied, but in a more automated and programmable way. This allows cloud providers and enterprises to maintain high availability across distributed and scalable infrastructures.
Interaction Between FHRP and Routing Protocols
FHRP works alongside dynamic routing protocols such as OSPF, EIGRP, and BGP to provide a complete network redundancy solution. While routing protocols determine the best path between networks, FHRP ensures that the first hop out of the local subnet is always available.
For example, even if multiple upstream paths exist, end devices still rely on a single default gateway. FHRP ensures that this gateway is always reachable. If the active router fails, routing protocols may take time to reconverge across the network, but FHRP provides an immediate local failover solution. This combination significantly improves overall network resilience.
Stability and Reliability in FHRP Design
Stability is one of the most important design goals in FHRP deployments. A well-configured redundancy system should remain stable under normal conditions and only trigger failover when a real failure occurs. Poor configuration can lead to unnecessary failovers, known as flapping, where routers continuously switch between active and standby states.
To maintain stability, network engineers carefully tune parameters such as hello intervals, hold timers, and priority values. These settings ensure that temporary network delays or minor glitches do not cause false failover events. Stability is essential for maintaining predictable network behavior, especially in mission-critical environments.
Impact of FHRP on Network Performance
FHRP generally has a minimal impact on network performance because it operates primarily through lightweight control messages between routers. However, its presence indirectly improves overall network performance by preventing downtime and reducing service interruptions.
In advanced implementations like load-balancing FHRP, traffic distribution across multiple routers can also improve throughput and reduce congestion. This ensures that network resources are used more efficiently, especially in high-traffic environments. By balancing both reliability and performance, FHRP contributes to a more optimized network infrastructure.
FHRP in Enterprise Network Architecture
In enterprise networks, FHRP is considered a standard best practice for designing resilient infrastructures. It is commonly deployed at the distribution layer, where it connects access switches to core routers. This layer is responsible for aggregating traffic from multiple departments or network segments, making redundancy essential.
Enterprise architectures often include multiple FHRP groups to support different VLANs or subnets. Each group may have its own active and standby routers depending on design requirements. This segmentation allows for better control, scalability, and fault isolation within large organizations.
Common Misconfigurations in FHRP Deployments
Despite its reliability, FHRP can suffer from misconfigurations that affect network performance. One common issue is inconsistent priority settings, which can cause unexpected active router selection. Another issue is mismatched timer values between devices, which can delay failover detection or cause instability.
Incorrect VLAN or interface configurations can also prevent FHRP messages from being exchanged properly. In such cases, routers may fail to form a redundancy group, leading to loss of gateway redundancy. Proper planning, documentation, and testing are essential to avoid these issues.
Security Enhancements in FHRP
Security is an important aspect of FHRP deployment, especially in large enterprise networks. Without proper protection, unauthorized devices could potentially participate in the redundancy group or send spoofed messages. To prevent this, authentication mechanisms are used between routers.
Authentication ensures that only trusted devices can exchange FHRP messages and participate in failover decisions. This protects the network from malicious attacks and misconfigurations. In addition, network segmentation and access control policies are often implemented to further secure FHRP operations.
Troubleshooting FHRP Failures
When FHRP issues occur, troubleshooting typically begins by verifying basic connectivity between routers. If hello messages are not being exchanged, the redundancy group cannot function properly. Engineers also check interface status, VLAN configuration, and IP addressing to ensure proper setup.
Log analysis is another important step in diagnosing FHRP problems. Logs can reveal failover events, timer mismatches, or authentication failures. In some cases, packet capture tools are used to analyze control traffic between routers and identify the root cause of the issue.
Importance of Testing FHRP Configurations
Testing is a crucial step in any FHRP deployment. Simulated failover scenarios help verify that redundancy mechanisms are working as expected. During testing, administrators manually shut down interfaces or simulate router failures to observe how quickly the network responds.
These tests help ensure that failover occurs smoothly and that end devices experience minimal disruption. Regular testing also helps identify configuration weaknesses and ensures that the network remains reliable under real failure conditions.
Role of FHRP in Business Continuity
Business continuity depends heavily on network availability, and FHRP plays a key role in supporting it. Many business applications rely on constant network access, including email systems, databases, and cloud services. Any disruption at the gateway level can have serious operational and financial consequences.
By ensuring that gateway services remain available even during hardware failures, FHRP helps organizations maintain continuous operations. This makes it a critical component of disaster recovery and high availability strategies.
Future Evolution of FHRP Technologies
As networking continues to evolve, FHRP is also adapting to new technologies such as automation, artificial intelligence, and intent-based networking. Future implementations are expected to become more intelligent, with automatic tuning of parameters and predictive failure detection.
Software-defined networking is also changing how redundancy is implemented, allowing more flexible and programmable control over gateway behavior. However, the core principle of first-hop redundancy remains essential, even as the underlying technologies evolve.
FHRP Concepts
First Hop Redundancy Protocol is a fundamental networking mechanism that ensures continuous availability of the default gateway. Across its different implementations, it provides redundancy, failover capabilities, and in some cases load balancing, all of which contribute to highly reliable network infrastructures.
By combining virtual gateways, active and standby roles, rapid failure detection, and seamless failover processes, FHRP eliminates single points of failure at the network edge. It is widely used in enterprise networks, data centers, and cloud environments where uptime is critical.
Overall, FHRP remains a core building block of modern network design, ensuring that connectivity is maintained even in the presence of hardware or software failures.
Conclusion
First Hop Redundancy Protocol (FHRP) is a crucial networking mechanism designed to eliminate the single point of failure at the default gateway level. It ensures that end devices always have access to a working gateway by allowing multiple routers to operate as a single virtual gateway. Through this approach, network reliability and availability are significantly improved without requiring changes on client devices.
Across its different implementations such as HSRP, VRRP, and GLBP, FHRP provides flexible options for redundancy and, in some cases, load balancing. These protocols use active and standby roles, virtual IP addressing, and fast failover mechanisms to maintain continuous network connectivity even during router failures. This makes FHRP an essential component of high availability network design.
In modern enterprise, data center, and cloud environments, FHRP plays a key role in maintaining business continuity. It ensures that critical services remain accessible even during hardware failures, maintenance activities, or unexpected network issues. When properly configured and monitored, it delivers seamless failover with minimal or no disruption to users.
Overall, FHRP is a foundational technology in networking that strengthens resilience, improves uptime, and supports scalable and reliable infrastructure. It remains an important part of network architecture wherever continuous connectivity and fault tolerance are required.