Recovery Time Objective (RTO) and Recovery Point Objective (RPO) are two essential concepts used in designing resilient IT systems and business continuity strategies. They help organizations prepare for unexpected disruptions such as system failures, cyberattacks, hardware crashes, or natural disasters. Instead of focusing only on preventing failures, these concepts focus on how an organization responds when failure occurs and how quickly it can return to normal operations.
RTO and RPO are not just technical terms; they represent business expectations. Every organization, regardless of size or industry, depends on data and systems to function. When those systems go down, even for a short period, operations can slow down or stop completely. These two objectives help define acceptable limits for downtime and data loss, allowing businesses to plan recovery strategies that align with operational priorities and customer expectations.
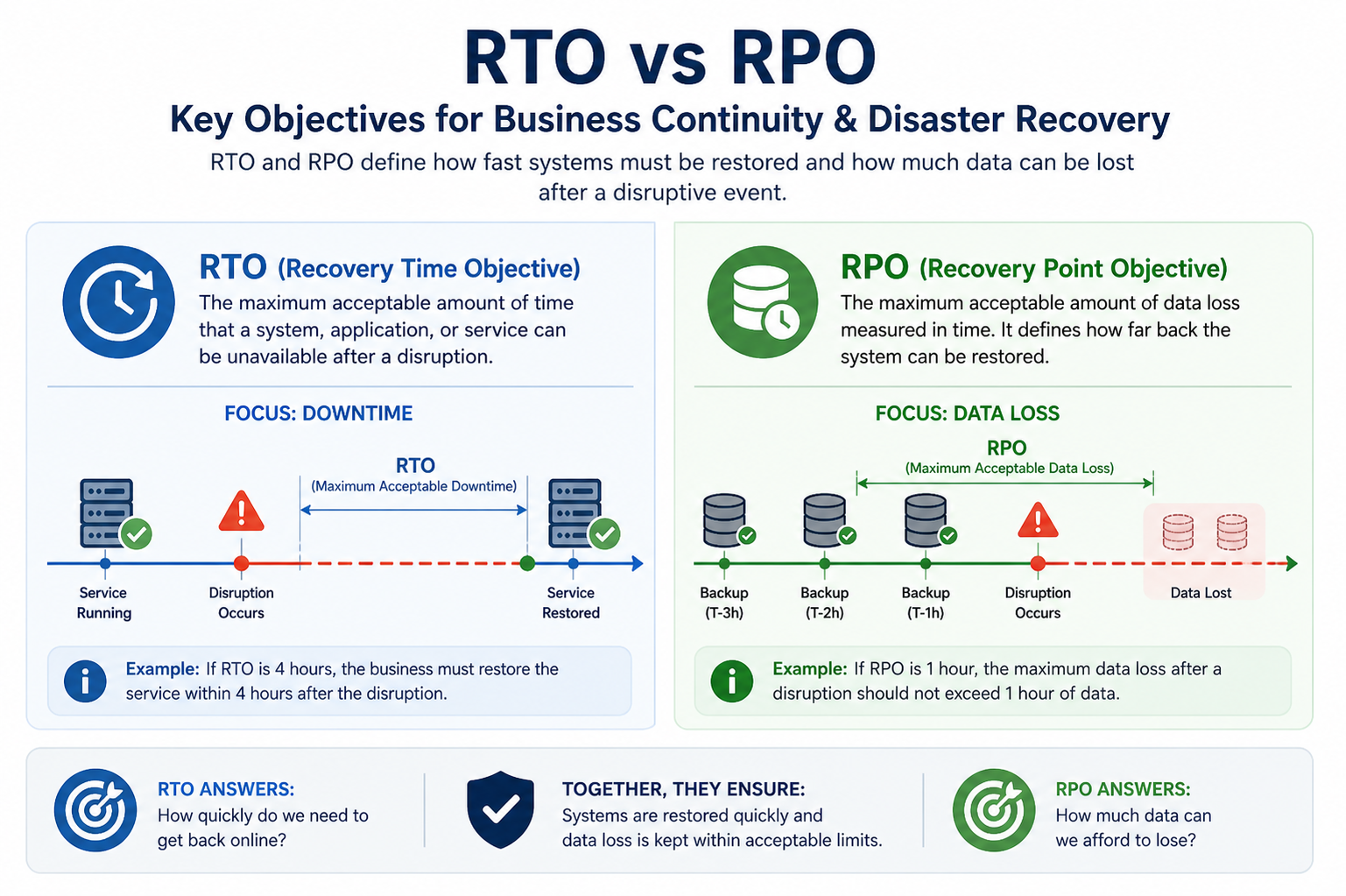
Meaning and Purpose of Recovery Time Objective (RTO)
Recovery Time Objective represents the maximum acceptable time allowed to restore a system or service after a disruption. It is essentially the target duration within which the affected service must be brought back online to avoid significant business impact. If the recovery takes longer than the defined RTO, the organization may experience financial loss, reputational damage, or operational disruption.
RTO is determined by analyzing how critical a system is to business operations. For example, a banking transaction system may have an extremely low RTO because even a few minutes of downtime can affect thousands of customers. On the other hand, an internal reporting system may tolerate longer downtime because it does not directly impact real-time operations.
RTO is not just about speed; it is about prioritization. It forces organizations to identify which systems are mission-critical and require immediate attention during recovery and which systems can be restored later. This prioritization helps in allocating resources effectively during emergencies.
Understanding Recovery Point Objective (RPO)
Recovery Point Objective defines the maximum amount of data loss that is acceptable during a disruption. It is measured in time and represents how far back data can be restored from backups. In simple terms, RPO answers the question of how much recent data an organization is willing to lose if a failure occurs.
If the RPO is set to one hour, it means that data backups must be frequent enough so that, in the worst-case scenario, no more than one hour of data is lost. If a system fails at 3:00 PM, the recovery process will restore data from the last backup, even if it was taken at 2:00 PM.
RPO is directly linked to backup frequency and data replication strategies. A smaller RPO requires more frequent backups and advanced replication methods, while a larger RPO allows for less frequent backups but increases potential data loss risk.
Difference Between RTO and RPO in Practical Terms
Although RTO and RPO are closely related, they serve different purposes. RTO focuses on system downtime, while RPO focuses on data loss. One deals with time to restore operations, and the other deals with how much data can be recovered.
For example, if a company has an RTO of four hours, it means all critical systems must be restored within four hours after a failure. If the RPO is fifteen minutes, it means that data backups must ensure that no more than fifteen minutes of data is lost.
Together, these two objectives define the overall recovery strategy. A system with a low RTO and low RPO requires highly advanced infrastructure, real-time replication, and automated failover mechanisms. In contrast, systems with higher tolerances can rely on simpler backup methods.
Importance of RTO in Business Operations
RTO plays a vital role in ensuring business continuity. Every minute of downtime can result in lost revenue, decreased productivity, and customer dissatisfaction. By defining RTO, organizations set clear expectations for recovery speed and allocate resources accordingly.
It also helps in risk assessment and planning. Systems that support critical operations, such as payment processing, healthcare services, or emergency communication, require extremely low RTO values. This ensures that even in worst-case scenarios, services can resume quickly without major disruption.
RTO also influences infrastructure decisions. Organizations with strict RTO requirements often invest in redundant systems, cloud-based failover solutions, and disaster recovery sites that can take over instantly when the primary system fails.
Importance of RPO in Data Protection Strategy
RPO is crucial for determining how much data loss is acceptable in a disaster scenario. Data is one of the most valuable assets for any organization, and losing it can have long-term consequences. RPO ensures that backup strategies are designed to minimize this loss.
For industries like finance, healthcare, and e-commerce, even small amounts of data loss can be critical. Transactions, patient records, and customer orders must be preserved with minimal delay. Therefore, such organizations adopt very low RPO values, often measured in seconds or minutes.
RPO also helps in designing backup frequency. A lower RPO requires continuous data replication or frequent snapshots, while a higher RPO may allow daily or hourly backups.
How RTO and RPO Influence Disaster Recovery Planning
Disaster recovery planning relies heavily on RTO and RPO to define recovery strategies. These objectives determine the type of backup systems, storage solutions, and recovery processes an organization must implement.
For example, a system with a low RTO may require a hot standby environment where a fully functional duplicate system is always running. This allows immediate switching during failure. A system with a higher RTO may rely on cold backups that take time to restore.
Similarly, RPO influences how data is stored and synchronized. Real-time replication systems are used for low RPO requirements, while periodic backups may be sufficient for higher RPO values.
Together, these objectives shape the architecture of disaster recovery environments and ensure that recovery plans are aligned with business priorities.
Factors That Affect RTO and RPO Decisions
Several factors influence how organizations define RTO and RPO. One of the most important factors is the criticality of the system. Systems that directly impact revenue or customer experience require stricter objectives.
Another factor is cost. Achieving low RTO and RPO values requires investment in advanced infrastructure, redundant systems, and continuous monitoring. Organizations must balance the cost of implementation with the potential cost of downtime or data loss.
Regulatory requirements also play a role. Certain industries are required to maintain strict data protection and recovery standards. These regulations often influence how RTO and RPO are defined.
Finally, technological capabilities affect these objectives. Modern cloud platforms and virtualization technologies make it easier to achieve lower RTO and RPO values compared to traditional systems.
Relationship Between RTO and RPO in Real Scenarios
RTO and RPO are interconnected but not dependent on each other. A system can have a very low RTO but a higher RPO, or vice versa, depending on business needs. However, in most critical systems, both values are kept low to ensure maximum resilience.
In real-world scenarios, achieving low RTO and RPO requires a combination of strategies such as automated failover, continuous data replication, and distributed system architecture. These technologies ensure that both system availability and data integrity are maintained even during unexpected failures.
Challenges in Defining RTO and RPO
One of the main challenges in defining RTO and RPO is accurately assessing business impact. Organizations often underestimate the consequences of downtime or data loss, leading to unrealistic objectives.
Another challenge is maintaining cost efficiency. Lowering RTO and RPO significantly increases infrastructure costs, and not all systems justify such investments.
Technical limitations can also create challenges. Legacy systems may not support real-time replication or rapid recovery, making it difficult to achieve strict objectives.
RTO and RPO are fundamental to building resilient and reliable IT systems. They help organizations prepare for disruptions by clearly defining acceptable limits for downtime and data loss. By understanding and implementing these objectives effectively, businesses can ensure continuity, protect critical data, and maintain customer trust even in adverse situations.
How Organizations Define Recovery Objectives
In real-world environments, defining Recovery Time Objective (RTO) and Recovery Point Objective (RPO) is a structured process that begins with business impact analysis. Organizations first evaluate which systems are most critical to their operations and what the consequences of downtime or data loss would be. This evaluation is not purely technical; it involves input from business leaders, IT teams, and risk management departments.
Once systems are categorized by importance, recovery objectives are assigned accordingly. Mission-critical systems are given very strict RTO and RPO values, while less important systems are given more flexible targets. This classification helps ensure that resources are allocated efficiently and that the most important services are restored first during disruptions.
The process also includes understanding dependencies between systems. Many applications rely on shared databases or infrastructure components, meaning that the recovery of one system may depend on the recovery of another. These dependencies must be carefully mapped to ensure realistic recovery objectives.
Role of Backup Strategies in Achieving RPO
Backup strategies play a central role in meeting Recovery Point Objectives. Since RPO is directly related to how much data can be lost, organizations must design backup systems that align with their tolerance levels. Different backup methods are used depending on how strict the RPO requirements are.
For systems with strict RPO values, continuous data replication is often used. This ensures that every change in the system is immediately copied to a secondary location. In such cases, data loss is minimal or nearly zero. For systems with more relaxed RPO requirements, periodic backups such as hourly or daily snapshots may be sufficient.
The choice of backup storage also influences RPO effectiveness. High-speed storage systems and geographically distributed data centers help reduce the risk of data loss. Additionally, modern cloud-based backup solutions provide automated replication features that support tighter RPO targets without requiring manual intervention.
Role of System Redundancy in Meeting RTO
System redundancy is one of the key techniques used to achieve Recovery Time Objectives. Redundancy involves creating duplicate systems or components that can take over immediately in case of failure. This reduces downtime and ensures that services can continue with minimal interruption.
There are different types of redundancy used in IT systems. Active-active redundancy involves running multiple systems simultaneously, where all systems share the load and can take over instantly if one fails. Active-passive redundancy involves a backup system that remains idle until the primary system fails.
The level of redundancy directly affects RTO. Higher redundancy typically results in lower recovery time because systems are already prepared to take over. However, this also increases infrastructure cost and complexity, which organizations must consider when designing their architecture.
Disaster Recovery Sites and Their Importance
Disaster recovery sites are specialized facilities designed to restore IT operations after a major failure. These sites are an essential part of achieving both RTO and RPO objectives. There are generally three types of disaster recovery sites: hot sites, warm sites, and cold sites.
A hot site is fully operational and continuously synchronized with the primary system. It allows near-instant recovery and is used for systems with very strict RTO and RPO requirements. A warm site has partial infrastructure and requires some setup before becoming fully operational. A cold site has minimal infrastructure and takes the longest time to become operational.
The choice of disaster recovery site depends on the organization’s recovery objectives. While hot sites provide the fastest recovery, they are also the most expensive. Cold sites are more cost-effective but result in longer downtime and higher data recovery delays.
Cloud Computing and Its Impact on RTO and RPO
Cloud computing has significantly transformed how organizations manage RTO and RPO. Traditional recovery methods often required physical infrastructure and manual processes, which increased recovery time and complexity. Cloud-based systems, on the other hand, offer scalability, automation, and geographic distribution.
With cloud infrastructure, organizations can deploy backup systems in multiple regions, ensuring faster recovery in case of regional failures. Automated backup and replication services also help maintain low RPO values without requiring extensive manual configuration.
Cloud environments also support rapid provisioning of resources, which directly reduces RTO. In many cases, virtual machines and applications can be restored within minutes, significantly improving recovery capabilities compared to traditional systems.
Balancing Cost with Recovery Objectives
One of the most important challenges in implementing RTO and RPO is balancing cost with recovery needs. Achieving very low RTO and RPO values requires significant investment in infrastructure, redundancy, and monitoring systems. Not all organizations can afford or justify these costs for every system.
As a result, businesses often adopt a tiered approach. Critical systems receive the highest level of protection with strict recovery objectives, while less important systems are assigned more flexible targets. This allows organizations to optimize costs while still maintaining overall resilience.
Cost considerations also influence technology choices. For example, continuous replication systems are more expensive than periodic backups, and hot disaster recovery sites cost significantly more than cold sites. Organizations must carefully evaluate these trade-offs when designing their recovery strategy.
Testing and Validation of RTO and RPO Plans
Defining RTO and RPO is not enough; organizations must regularly test and validate their recovery plans. Testing ensures that systems can actually be restored within the defined objectives during a real disaster scenario.
Disaster recovery drills are commonly used to simulate system failures and evaluate recovery performance. These tests help identify weaknesses in backup systems, uncover configuration issues, and ensure that teams are prepared for real incidents.
Validation also involves measuring actual recovery times and comparing them with defined RTO and RPO targets. If recovery takes longer than expected or data loss exceeds acceptable limits, adjustments are made to improve the system.
Human Factors in Recovery Planning
While technology plays a major role in achieving RTO and RPO, human factors are equally important. Well-trained IT teams are essential for executing recovery procedures effectively. Even the best systems can fail to meet recovery objectives if personnel are not properly trained or prepared.
Clear documentation, defined responsibilities, and communication plans are critical components of recovery readiness. During a disaster, confusion or delays in decision-making can increase downtime and data loss, making it essential to have structured response procedures in place.
Common Mistakes in Defining RTO and RPO
Many organizations make mistakes when defining recovery objectives. One common mistake is setting unrealistic targets without considering technical or financial limitations. This can lead to recovery plans that are impossible to execute effectively.
Another mistake is failing to regularly update recovery objectives. As systems evolve and business needs change, RTO and RPO values must also be reviewed and adjusted. Outdated recovery plans may no longer align with current operational requirements.
Ignoring system dependencies is another critical issue. If interconnected systems are not properly analyzed, recovery efforts may fail even if individual systems meet their objectives.
Evolving Trends in Recovery Planning
Modern IT environments continue to evolve, leading to new approaches in RTO and RPO management. Automation, artificial intelligence, and predictive analytics are increasingly being used to improve recovery strategies.
Automated failover systems can detect failures and switch to backup systems without human intervention, significantly reducing RTO. Predictive systems can identify potential failures before they occur, allowing preventive action that minimizes downtime.
As digital transformation continues, recovery planning is becoming more dynamic, adaptive, and integrated into overall system design rather than being treated as a separate process.
Implementation and Real-World Importance
The implementation of Recovery Time Objective and Recovery Point Objective is a critical part of modern IT and business continuity planning. These concepts guide how systems are designed, how data is protected, and how organizations respond to disruptions. By carefully balancing technology, cost, and operational needs, businesses can create resilient systems that ensure continuity even in the face of unexpected failures.
Integration of RTO and RPO into Business Continuity Frameworks
In large-scale enterprise environments, Recovery Time Objective and Recovery Point Objective are not standalone concepts but are deeply integrated into broader business continuity and risk management frameworks. These frameworks ensure that recovery planning is aligned with organizational goals, regulatory requirements, and operational dependencies across departments.
Business continuity planning uses RTO and RPO as measurable benchmarks to define how quickly critical services must resume and how much data loss is tolerable under different disruption scenarios. This alignment ensures that IT recovery strategies directly support business priorities rather than functioning in isolation. For example, customer-facing systems are typically assigned stricter recovery objectives compared to internal reporting systems, reflecting their higher business impact.
This integration also ensures coordination between technical teams and business stakeholders. Instead of IT teams independently deciding recovery targets, business units provide input based on operational importance, revenue impact, and customer expectations.
Tiered System Classification Based on Recovery Needs
Organizations often classify systems into tiers to simplify recovery planning. Each tier represents a level of criticality and is associated with specific RTO and RPO values. This structured classification allows efficient allocation of resources and ensures consistency in recovery strategies.
Tier 1 systems are mission-critical and require the strictest recovery objectives. These systems typically support real-time operations such as transaction processing, authentication services, or core business applications. Even a few minutes of downtime or data loss can have significant consequences.
Tier 2 systems are important but not immediately critical. They may support essential operations but can tolerate short delays in recovery. Tier 3 systems are non-critical and may include archival or reporting systems that can be restored over longer periods without major impact.
This tiered approach simplifies decision-making and helps organizations prioritize recovery efforts during emergencies.
Automation in Modern Recovery Architectures
Automation plays a major role in improving both RTO and RPO in modern IT environments. Automated recovery systems reduce dependency on manual intervention, which is often slow and prone to error during high-pressure situations.
Automated failover mechanisms can detect system failures in real time and instantly switch operations to backup systems. This significantly reduces downtime and helps achieve very low RTO values. Similarly, automated data replication ensures that changes are continuously synchronized across multiple environments, minimizing data loss and improving RPO compliance.
Automation also extends to monitoring and alerting systems. These tools continuously analyze system health and trigger recovery actions when anomalies are detected. As a result, organizations can respond to failures more quickly and efficiently than traditional manual processes allow.
Role of Virtualization and Containerization in Recovery Optimization
Virtualization and containerization technologies have significantly enhanced the ability to achieve strict RTO and RPO targets. Virtual machines allow entire system environments to be replicated and restored quickly, reducing recovery complexity. Instead of rebuilding systems from scratch, organizations can spin up pre-configured virtual environments within minutes.
Containerization further improves recovery efficiency by packaging applications and their dependencies into lightweight units. These containers can be deployed rapidly across different environments, ensuring consistent performance and faster recovery times.
These technologies also improve portability, allowing systems to be moved between on-premises infrastructure and cloud environments with minimal disruption. This flexibility strengthens disaster recovery strategies and reduces overall recovery time.
Geographic Redundancy and Data Distribution Strategies
Geographic redundancy is a critical component of modern recovery planning. By distributing data and systems across multiple physical locations, organizations can protect themselves against regional failures such as power outages, natural disasters, or network disruptions.
Data replication across geographically separated data centers ensures that even if one location becomes unavailable, another can take over with minimal delay. This approach directly supports both RTO and RPO objectives by reducing recovery time and minimizing data loss.
However, geographic distribution introduces challenges such as latency, synchronization delays, and increased infrastructure costs. Organizations must carefully balance these factors when designing multi-region architectures.
Regulatory Compliance and Recovery Objectives
In many industries, RTO and RPO are influenced by regulatory and compliance requirements. Governments and regulatory bodies often impose strict guidelines on data protection, availability, and disaster recovery preparedness.
Industries such as healthcare, finance, and telecommunications are particularly affected by these regulations. Compliance requirements may dictate maximum allowable downtime or mandatory data retention policies, which directly shape recovery objectives.
Failure to meet these requirements can result in legal penalties, financial losses, and reputational damage. As a result, organizations must ensure that their recovery strategies not only meet business needs but also comply with external regulatory standards.
Risk Assessment and Impact Analysis in Defining Recovery Objectives
Risk assessment is a foundational step in determining appropriate RTO and RPO values. Organizations must identify potential threats such as cyberattacks, hardware failures, human errors, and natural disasters. Each risk is evaluated based on its likelihood and potential impact on operations.
Impact analysis helps determine how different systems contribute to overall business functionality. Systems with high dependency on revenue generation or customer interaction are assigned stricter recovery objectives due to their critical importance.
This structured approach ensures that recovery planning is based on data-driven analysis rather than assumptions. It also helps organizations allocate resources effectively by focusing on the most significant risks.
Performance Trade-offs in Recovery System Design
Designing systems that meet strict RTO and RPO requirements often involves performance trade-offs. For example, continuous data replication improves recovery point objectives but may introduce network overhead and system latency.
Similarly, maintaining active-active redundancy improves recovery time but increases infrastructure complexity and operational cost. Organizations must evaluate these trade-offs carefully to ensure that recovery goals do not negatively impact system performance or user experience during normal operations.
In some cases, optimizing for recovery may require compromising on other factors such as cost efficiency or system simplicity. The key is to find a balanced approach that aligns with business priorities.
Incident Response and Coordination During Recovery Events
Effective incident response is essential for achieving defined RTO and RPO targets. During a disruption, coordinated action between technical teams, management, and communication teams is critical.
Incident response plans define clear roles and responsibilities to ensure that recovery actions are executed efficiently. This includes identifying the source of failure, initiating recovery procedures, and communicating status updates to stakeholders.
Poor coordination during recovery events can significantly increase downtime and data loss, even if technical systems are capable of meeting recovery objectives. Therefore, strong communication and structured response procedures are essential components of recovery planning.
Continuous Improvement in Recovery Strategies
Recovery planning is not a one-time activity but an ongoing process. Organizations must continuously review and improve their RTO and RPO strategies based on system changes, technological advancements, and past incident experiences.
Post-incident analysis plays a key role in this process. After every disruption, organizations evaluate what went wrong, how effectively recovery objectives were met, and what improvements can be made. This feedback loop ensures that recovery strategies remain effective and aligned with evolving business needs.
Regular testing, audits, and updates help maintain readiness and ensure that systems can consistently meet defined recovery targets.
Future Direction of RTO and RPO in Digital Systems
As technology continues to evolve, recovery planning is becoming increasingly intelligent and automated. Artificial intelligence and machine learning are being used to predict system failures before they occur, allowing proactive mitigation rather than reactive recovery.
Edge computing and distributed architectures are also changing how recovery systems are designed. With data processing occurring closer to end users, recovery strategies must adapt to more decentralized environments.
In the future, RTO and RPO are expected to become even more dynamic, adjusting in real time based on system conditions, workload demands, and risk levels.
Enterprise Recovery Design
RTO and RPO remain fundamental pillars of modern IT resilience. They provide a structured way to measure and manage downtime and data loss while ensuring alignment between technical systems and business goals. Through careful planning, automation, and continuous improvement, organizations can build highly resilient infrastructures capable of withstanding disruptions while maintaining operational stability.
Complexity in Large-Scale Distributed Systems
In modern large-scale environments, achieving defined Recovery Time Objective and Recovery Point Objective values becomes increasingly complex due to distributed architectures. Applications are no longer hosted on a single server or location; instead, they are spread across multiple cloud services, microservices, and geographically distributed nodes.
This distribution improves scalability and performance but introduces significant recovery complexity. When a failure occurs, multiple interconnected services must be restored in the correct sequence to ensure full functionality. If even one dependency is delayed, it can affect the overall recovery time, causing RTO targets to be missed.
Data consistency across distributed systems also becomes a challenge. Ensuring that all nodes reflect the same state at the time of recovery is essential to meet RPO requirements. Without proper synchronization mechanisms, inconsistencies can lead to partial data loss or corruption during restoration.
Latency and Synchronization Limitations
Latency is a major constraint in achieving strict RPO objectives, especially in geographically distributed systems. When data is replicated across multiple locations, network delays can cause synchronization gaps between primary and secondary systems.
These delays mean that even in real-time replication systems, there is always a small window where data loss can occur during sudden failures. Reducing this gap requires high-speed networks and optimized replication protocols, which can significantly increase infrastructure costs.
Synchronization issues also arise when systems operate in different time zones or under varying loads. Maintaining consistent data states across all environments requires careful engineering and continuous monitoring.
Human Error and Operational Risks
Despite advancements in automation, human error remains one of the leading causes of system failures and recovery delays. Incorrect configuration changes, accidental deletions, or improper recovery execution can all impact RTO and RPO outcomes.
During high-pressure recovery situations, teams may also face decision-making delays or communication breakdowns. These operational risks can extend downtime beyond planned RTO limits, even if technical systems are capable of faster recovery.
To mitigate these risks, organizations rely on standardized procedures, automation, and regular training. However, complete elimination of human error is not possible, making it a persistent challenge in recovery planning.
Data Integrity Challenges During Recovery
Maintaining data integrity during recovery is one of the most critical aspects of meeting RPO objectives. When systems are restored from backups or replicas, there is always a risk of inconsistencies, duplication, or missing transactions.
This challenge becomes more pronounced in systems that handle continuous transactions, such as financial platforms or e-commerce systems. Even small inconsistencies in data recovery can lead to significant operational issues.
Ensuring data integrity requires advanced validation mechanisms, transaction logging, and rollback capabilities. These systems help verify that recovered data accurately reflects the state of the system before failure.
Cost Implications of Strict Recovery Objectives
One of the most significant constraints in defining RTO and RPO is cost. Achieving near-zero downtime and minimal data loss requires highly advanced infrastructure, including redundant systems, real-time replication, and multiple disaster recovery sites.
These setups can be extremely expensive to maintain, especially for small and medium-sized organizations. As a result, businesses often need to make trade-offs between ideal recovery targets and financial feasibility.
Cost also increases with the level of automation and redundancy implemented. While advanced systems reduce recovery time and improve data protection, they also require continuous investment in hardware, software, and skilled personnel.
Dependency Management Across Systems
Modern IT environments consist of interconnected applications that depend on shared databases, APIs, and services. This interdependency creates challenges when defining and achieving RTO and RPO targets.
If a single critical service fails, it can impact multiple dependent systems, increasing overall recovery time. Understanding and mapping these dependencies is essential for accurate recovery planning.
Failure to properly account for dependencies can lead to incomplete recovery, where some systems are restored while others remain non-functional. This mismatch can disrupt business operations even if individual systems meet their recovery objectives.
Scalability Issues in Recovery Systems
As organizations grow, their recovery systems must scale accordingly. However, scaling recovery infrastructure introduces additional complexity. Larger systems require more storage, higher network capacity, and more sophisticated orchestration mechanisms.
Scalability challenges also affect replication speed and backup processing times. As data volumes increase, maintaining low RPO values becomes more difficult without significant infrastructure upgrades.
Similarly, ensuring fast recovery across expanded systems can impact RTO performance, especially when multiple services need to be restored simultaneously.
Security Considerations in Recovery Planning
Security plays a critical role in RTO and RPO implementation. Recovery systems must be protected against unauthorized access, data breaches, and cyberattacks. Backup data itself is often a target for malicious actors, making it essential to secure replication channels and storage environments.
Encryption, access control, and secure authentication mechanisms are commonly used to protect recovery data. However, these security measures can sometimes introduce additional processing overhead, potentially impacting recovery speed.
Balancing security with performance is a key challenge in designing effective recovery systems.
Testing Limitations and Realistic Simulation Gaps
Although organizations regularly conduct disaster recovery testing, these simulations cannot always perfectly replicate real-world conditions. Live systems under stress may behave differently compared to controlled test environments.
Some failures, such as large-scale cyberattacks or simultaneous multi-region outages, are difficult to simulate accurately. As a result, recovery plans may not always perform as expected in real incidents.
This limitation highlights the importance of continuous improvement and adaptive recovery strategies that can adjust dynamically during unexpected scenarios.
Communication Breakdown During Recovery Events
Effective communication is essential during recovery operations. However, in real-world scenarios, communication breakdowns often occur due to system outages, lack of coordination, or unclear escalation procedures.
When teams are unable to communicate effectively, recovery actions may be delayed or executed incorrectly, increasing downtime and data loss. Clear communication protocols and redundant communication channels are necessary to minimize these risks.
Organizations often implement incident management systems to centralize communication and ensure that all stakeholders remain informed during recovery processes.
Evolution of Recovery Strategies in Modern IT Ecosystems
Recovery strategies have evolved significantly with the rise of cloud computing, automation, and artificial intelligence. Traditional backup-based recovery models are being replaced by continuous availability architectures and self-healing systems.
Modern systems are designed to detect failures automatically and initiate recovery without human intervention. This shift has greatly improved the ability to meet strict RTO and RPO targets in complex environments.
Adaptive systems that dynamically adjust recovery strategies based on system health and workload conditions are becoming more common, offering greater resilience and efficiency.
Long-Term Strategic Importance of RTO and RPO
Beyond technical implementation, RTO and RPO play a strategic role in shaping organizational resilience. They influence investment decisions, infrastructure design, and risk management policies.
Organizations that prioritize strong recovery capabilities are better positioned to handle disruptions and maintain customer trust. In competitive markets, the ability to recover quickly and protect data integrity can provide a significant advantage.
As digital dependency continues to grow, the importance of well-defined and effectively implemented recovery objectives will only increase, making them a core element of modern enterprise strategy.
Conclusion
Recovery Time Objective and Recovery Point Objective are fundamental pillars of modern disaster recovery and business continuity planning. They provide a structured way to measure and control how an organization responds to system disruptions and data loss events. RTO focuses on the acceptable duration of downtime, ensuring that critical systems are restored within a defined time frame to minimize operational impact. RPO, on the other hand, focuses on data loss tolerance, defining how much historical data an organization can afford to lose without severely affecting business operations.
Together, these two concepts create a balanced framework for designing resilient IT systems. They guide decisions related to infrastructure design, backup frequency, replication strategies, and recovery mechanisms. By clearly defining these objectives, organizations can prioritize systems based on business importance and allocate resources more effectively during both planning and emergency situations.
In practical environments, achieving optimal RTO and RPO values requires a combination of technology, strategy, and operational discipline. Automation, redundancy, cloud computing, and real-time replication all play a major role in improving recovery performance. At the same time, human factors, cost constraints, and system complexity must also be carefully managed to ensure realistic and achievable recovery targets.
Ultimately, RTO and RPO are not just technical metrics but strategic tools that help organizations maintain continuity, protect critical data, and ensure resilience in the face of unexpected disruptions. As technology continues to evolve, their importance will only grow, making them essential components of every modern IT and business infrastructure.