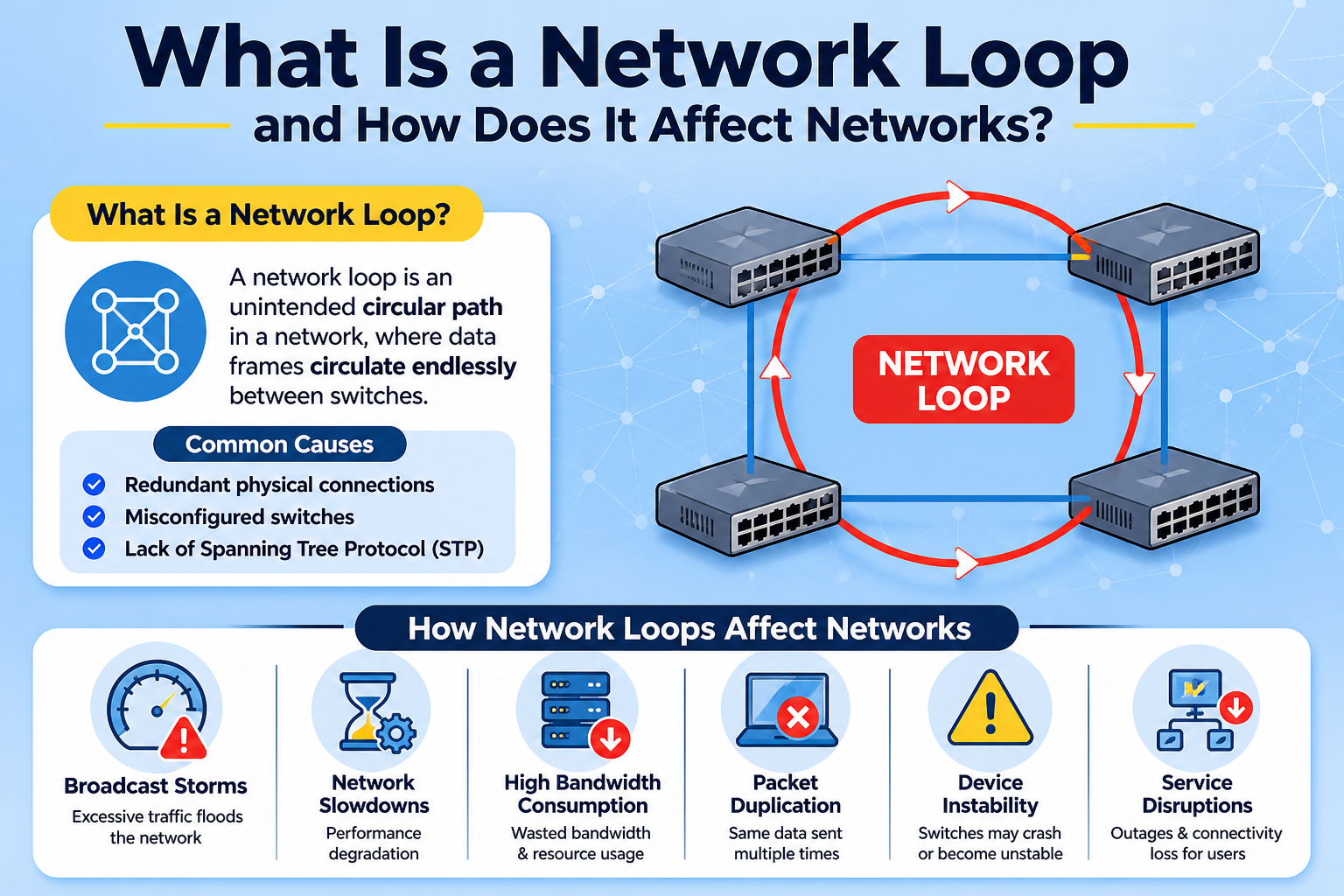
A network loop refers to a condition in a computer network where data packets circulate repeatedly between network devices without reaching their intended destination. This situation usually arises due to misconfigurations in network topology, especially when redundant paths exist without proper loop prevention mechanisms. In a well-designed network, data should follow a clear path, but in a loop, the same information keeps traveling endlessly, creating inefficiencies and instability.
How Network Loops Form in Modern Networks
Network loops typically occur in switched networks where multiple interconnections are created for redundancy and fault tolerance. While redundancy is important for reliability, it must be carefully managed. When two or more switches are connected in a way that forms a circular path for data, and no loop control protocol is active or correctly configured, frames begin to circulate continuously.
This issue is common in large enterprise networks where multiple switches are deployed across departments or buildings. A simple mistake such as connecting an additional cable between switches without proper configuration can unintentionally create a loop. Once formed, the loop begins to multiply traffic rapidly, affecting overall network performance.
Understanding the Technical Behavior of a Network Loop
At the technical level, network loops primarily affect Layer 2 of the OSI model, which is responsible for switching and MAC address learning. Switches use MAC address tables to determine where to send frames. However, in a loop condition, broadcast and unknown unicast frames are forwarded repeatedly across all available paths.
As these frames circulate, switches continuously update their MAC address tables with conflicting information. This leads to a phenomenon known as MAC table instability, where the same MAC address appears on multiple ports in rapid succession. As a result, the switch becomes confused about the correct forwarding path, further worsening the loop condition.
Broadcast Storms and Network Congestion
One of the most damaging effects of a network loop is the creation of a broadcast storm. A broadcast storm occurs when broadcast packets are endlessly multiplied and forwarded across the network. Since broadcast frames are sent to all devices, the looping effect causes exponential traffic growth.
As traffic increases uncontrollably, network bandwidth becomes saturated. This leads to severe congestion, making it difficult or impossible for legitimate data to pass through the network. Even simple tasks like accessing files, loading websites, or using internal applications become extremely slow or completely unresponsive.
Impact on Network Devices and Hardware Performance
Network loops do not only affect traffic flow but also place significant strain on network hardware. Switches and routers are forced to process a massive amount of redundant data, which increases CPU and memory usage dramatically.
When a device becomes overwhelmed, it may begin to drop legitimate packets or become unresponsive. In extreme cases, network devices may crash entirely, causing a temporary or complete outage of the affected network segment. This makes network loops a critical issue in enterprise environments where uptime is essential.
How Network Loops Affect End Users
From an end-user perspective, network loops often manifest as slow internet speeds, frequent disconnections, or inability to access shared resources such as printers, servers, or cloud applications. Users may also experience intermittent connectivity where the network works briefly and then stops responding.
These issues are often difficult to diagnose at first because they may resemble general network congestion or ISP-related problems. However, the root cause often lies within the internal network infrastructure itself.
Role of Redundancy and Why It Can Cause Loops
Redundancy in networking is designed to improve reliability by providing multiple paths for data to travel. If one path fails, another can take over, ensuring continuous connectivity. However, without proper loop prevention mechanisms, redundancy can become a liability instead of an advantage.
When redundant links are created without control protocols, switches may treat each connection as a valid forwarding path. This leads to circular data flow, which is the foundation of network loops. Therefore, redundancy must always be paired with intelligent loop prevention technologies.
Spanning Tree Protocol and Loop Prevention
One of the most widely used methods to prevent network loops is the Spanning Tree Protocol. This protocol automatically detects redundant paths in a network and blocks unnecessary links to ensure a loop-free topology.
By creating a logical tree structure, it allows only one active path between any two network devices while keeping backup paths in standby mode. If the primary path fails, the protocol reactivates a backup path, maintaining network continuity without creating loops.
Enhanced versions of this protocol, such as Rapid Spanning Tree Protocol, improve convergence time and make networks more efficient in responding to changes.
VLAN Misconfigurations and Loop Risks
Virtual Local Area Networks also play an important role in modern networking, but improper VLAN configuration can contribute to loop issues. When VLANs are incorrectly mapped or trunk ports are misconfigured, traffic can circulate between switches in unintended ways.
This often leads to broadcast traffic leaking across VLAN boundaries, increasing the likelihood of loop formation. Proper VLAN design and segmentation are essential for maintaining a stable and efficient network structure.
Common Causes of Network Loops
Several factors can lead to network loops, including incorrect cabling between switches, accidental duplication of connections, disabled loop prevention protocols, or faulty network devices. Human error during network expansion or maintenance is one of the most common causes.
In some cases, outdated hardware or firmware bugs may also contribute to loop behavior. Poor documentation of network topology can further increase the risk, as administrators may unknowingly create redundant paths.
Symptoms of a Network Loop
Identifying a network loop early is crucial to minimizing damage. Common symptoms include sudden network slowdowns, unusually high traffic levels, device overheating, frequent disconnections, and unstable connectivity.
Network monitoring tools may show spikes in broadcast traffic or rapidly changing MAC address tables. These indicators often point to an underlying loop condition that needs immediate attention.
Troubleshooting Network Loops
Diagnosing a network loop requires a systematic approach. Network administrators often begin by isolating segments of the network to identify where the loop originates. Disconnecting suspected links one at a time can help restore normal traffic flow.
Monitoring tools that analyze traffic patterns and switch behavior are also essential. Once the problematic segment is identified, the configuration must be corrected to eliminate redundant paths or properly enable loop prevention mechanisms.
Preventive Best Practices for Network Stability
Preventing network loops requires careful planning and proper network design. Administrators should ensure that all redundant links are managed by loop prevention protocols. Proper documentation of network topology is also essential to avoid accidental misconfigurations.
Using managed switches with built-in loop detection features can significantly reduce risk. Regular network audits and monitoring help detect anomalies early before they escalate into major issues.
Importance of Network Design in Avoiding Loops
A well-structured network design plays a crucial role in preventing loops. Hierarchical designs, such as core, distribution, and access layers, help maintain clear traffic flow paths. This structure reduces the chances of accidental circular connections.
Network segmentation and controlled redundancy ensure that even if multiple paths exist, they do not interfere with each other. Proper planning at the design stage is the most effective way to avoid loop-related issues in the long term.
Long-Term Impact of Network Loops if Unresolved
If left unresolved, network loops can cause repeated outages and long-term instability in an organization’s infrastructure. Productivity loss, downtime, and data access issues can significantly impact business operations.
In critical environments such as data centers or financial systems, even a short-lived loop can lead to major disruptions. This highlights the importance of proactive monitoring and immediate response strategies.
Advanced Understanding of Network Loop Behavior in Large-Scale Networks
In larger and more complex network environments, network loops become significantly more challenging to detect and resolve. Enterprise networks often consist of multiple layers of switches, routers, virtual networks, and redundant connections designed to improve reliability. While these designs enhance performance and fault tolerance, they also increase the risk of unintended loop formation if not properly controlled.
As networks scale, even a small configuration error can propagate across multiple segments. A loop that begins in a single access switch can quickly spread across distribution and core layers, affecting thousands of connected devices. This cascading effect makes loop issues particularly dangerous in high-density environments such as data centers and corporate infrastructures.
Role of MAC Address Flapping in Loop Detection
One of the key indicators of a network loop is MAC address flapping. This occurs when a switch observes the same MAC address appearing on different ports within a short time interval. Under normal conditions, a MAC address should remain associated with a single port unless a legitimate topology change occurs.
In a loop scenario, however, frames containing the same source MAC address circulate through multiple paths, causing the switch to continuously update its MAC address table. This instability creates confusion in forwarding decisions, leading to inconsistent traffic delivery and further network degradation.
Impact on Bandwidth Utilization and Traffic Amplification
Network loops cause a dramatic increase in unnecessary traffic, which leads to bandwidth exhaustion. Since packets are continuously forwarded without termination, the same data occupies network channels repeatedly. This phenomenon is known as traffic amplification.
As amplification continues, available bandwidth for legitimate applications decreases rapidly. Services that rely on consistent data flow, such as VoIP, video conferencing, and cloud-based applications, are often the first to experience degradation. Eventually, the network becomes saturated, resulting in widespread service disruption.
Effects on Routing and Higher-Layer Protocols
Although network loops primarily occur at Layer 2, their impact extends to higher layers of the OSI model. Routing protocols may begin to receive inconsistent or excessive updates due to unstable link states. This can lead to routing table instability and frequent recalculations of network paths.
In extreme cases, dynamic routing protocols may interpret loop-induced traffic as topology changes, triggering unnecessary convergence processes. This further increases network load and contributes to instability across multiple network layers.
Loop Guard and Additional Protection Mechanisms
Beyond basic loop prevention protocols, modern networks often implement additional safeguards such as Loop Guard. This feature is designed to prevent alternative ports from unintentionally becoming active in situations where expected network traffic is not received.
Loop Guard helps protect against scenarios where unidirectional link failures or misconfigurations might otherwise allow a loop to form. By keeping certain ports in a blocking state under suspicious conditions, it adds an extra layer of security to network stability.
BPDU Handling and Its Importance in Loop Prevention
Bridge Protocol Data Units (BPDUs) play a critical role in maintaining loop-free topologies. These control messages are exchanged between switches to determine the structure of the network and identify redundant paths.
If a switch stops receiving BPDUs from a designated neighbor, it may incorrectly assume that the network topology has changed. This can result in unintended port activation and potential loop formation. Proper BPDU handling ensures that switches maintain accurate topology information and avoid making incorrect forwarding decisions.
Network Loop in Virtualized and Cloud Environments
In modern IT infrastructures, virtualization and cloud computing add additional complexity to network design. Virtual switches, software-defined networking (SDN), and containerized environments all rely on logical networking layers that can also be affected by loop conditions.
Misconfigured virtual switches or incorrect bridging between virtual machines can create internal loops that are harder to detect than physical network loops. These issues may remain hidden until they cause performance degradation or service outages at scale.
Impact on Security and Network Attacks
Network loops can also be exploited or triggered unintentionally during certain types of network attacks. For example, denial-of-service conditions may be amplified if attackers intentionally create broadcast storms or manipulate switching behavior.
While loops are not always a direct security vulnerability, their impact can weaken network defenses by overwhelming monitoring systems and reducing visibility. This makes it more difficult to detect genuine security threats during an ongoing loop condition.
Diagnostic Tools Used for Loop Identification
Network administrators rely on specialized diagnostic tools to identify and resolve loop conditions. These tools monitor traffic patterns, switch port behavior, and MAC address changes in real time. Sudden spikes in broadcast traffic or repeated frame forwarding are strong indicators of a loop.
Advanced network analyzers can also trace packet paths to identify where looping begins. By isolating affected segments, administrators can quickly locate misconfigured links or faulty devices responsible for the issue.
Importance of Network Segmentation in Loop Control
Network segmentation plays a crucial role in reducing the impact of loops. By dividing a network into smaller, controlled segments, administrators can limit the spread of broadcast traffic and isolate potential issues.
Segmentation ensures that even if a loop occurs in one part of the network, it does not immediately affect the entire infrastructure. This containment strategy is especially important in large organizations with multiple departments and distributed systems.
Hardware Limitations and Loop Sensitivity
Not all network devices handle loop conditions equally. Older or low-end switches may lack advanced loop detection features, making them more vulnerable to broadcast storms and MAC table instability.
In contrast, enterprise-grade switches are designed with built-in protections that can automatically detect and mitigate loop conditions. These devices often include hardware-level acceleration for traffic filtering, which helps maintain stability under high load conditions.
Recovery Process After a Network Loop Incident
Once a network loop has been identified and resolved, recovery is not always immediate. Network devices may require time to rebuild their MAC address tables and stabilize forwarding behavior. During this period, temporary performance issues may still occur.
Clearing MAC tables, restarting affected devices, and verifying configuration consistency are common steps in restoring normal network operations. Full recovery depends on the size and complexity of the affected network segment.
Long-Term Strategies for Loop Prevention
Preventing network loops requires a long-term strategy that includes proper design, continuous monitoring, and regular audits. Network administrators must ensure that redundancy is implemented correctly and that all devices are configured consistently.
Automation tools and network management systems can help reduce human error by enforcing standardized configurations. Regular testing and simulation of network failures can also help identify potential loop risks before they occur in production environments.
Network Loop Behavior in High Availability and Enterprise Architectures
In high availability network designs, redundancy is intentionally built into the infrastructure to ensure uninterrupted service during failures. However, this same redundancy increases the complexity of the network and raises the possibility of network loops if control mechanisms are not properly implemented. Enterprise environments often use multiple interconnected switches, backup links, and failover systems, all of which must be carefully managed to avoid unintended circular traffic paths.
When redundancy is not properly coordinated, the network may interpret multiple active paths as valid forwarding routes. This can cause data packets to circulate endlessly between devices, especially when loop prevention protocols are disabled or incorrectly configured. As networks become more distributed and dynamic, maintaining loop-free operation becomes increasingly critical.
Role of Convergence in Preventing Loop Conditions
Network convergence refers to the process by which all network devices agree on the current topology after a change occurs. In a stable network, convergence happens quickly and ensures that all switches and routers update their forwarding tables consistently.
However, during a loop condition, convergence may be delayed or disrupted. The continuous circulation of packets creates inconsistent topology information, preventing devices from reaching a stable state. This instability can prolong the loop condition and make recovery more difficult.
Fast and efficient convergence protocols are essential in modern networks to minimize the impact of topology changes and prevent loops from persisting for extended periods.
Impact of Network Loops on Application Performance
Network loops do not only affect infrastructure components; they also have a direct impact on application performance. Applications that rely on real-time data transmission, such as online databases, cloud services, and communication platforms, are particularly vulnerable.
As loops increase network congestion, application requests may experience delays, timeouts, or failed connections. In severe cases, applications may become completely inaccessible due to the inability to transmit or receive data reliably. This can significantly affect business operations and user experience.
Multilayer Switching and Loop Complexity
Modern networks often use multilayer switches that operate at both Layer 2 and Layer 3 of the OSI model. While these devices improve performance and flexibility, they also introduce additional complexity in loop management.
A loop that begins at Layer 2 can propagate upward and influence routing decisions at Layer 3. Similarly, routing inconsistencies can feed back into switching behavior, creating complex loop scenarios that are harder to isolate. This interdependence requires careful configuration across all layers of the network stack.
Storm Control Mechanisms in Loop Mitigation
To reduce the impact of broadcast storms caused by network loops, many switches implement storm control features. These mechanisms monitor the rate of broadcast, multicast, and unknown unicast traffic on each port.
When traffic exceeds predefined thresholds, storm control temporarily limits or blocks excessive traffic to prevent network saturation. While this does not eliminate the loop itself, it helps contain its effects and prevents complete network collapse. This allows administrators time to identify and resolve the root cause.
Impact on Data Integrity and Packet Loss
Network loops can also lead to significant data integrity issues. As packets circulate repeatedly, they may become duplicated, delayed, or dropped. This results in inconsistent data delivery across the network.
In applications where data accuracy is critical, such as financial systems or database synchronization, packet duplication or loss can lead to serious inconsistencies. Ensuring loop-free communication is therefore essential for maintaining data reliability.
Loop Detection in Software-Defined Networking
Software-defined networking introduces a centralized approach to network management, allowing administrators to control traffic flow through software-based controllers. While SDN improves visibility and control, it also introduces new challenges in loop detection.
Misconfigured flow rules or controller errors can inadvertently create logical loops within the network fabric. Because SDN environments are highly dynamic, loop detection mechanisms must operate in real time to prevent widespread disruption.
Impact of Network Loops on Virtual LAN Isolation
Virtual LANs are designed to separate network traffic into isolated segments. However, when loops occur, VLAN boundaries can become compromised. Broadcast traffic may leak between VLANs, breaking isolation and increasing congestion across multiple segments.
This not only affects performance but also undermines network segmentation policies designed for security and efficiency. Proper VLAN configuration and strict trunking rules are essential to maintain isolation in loop-free environments.
Role of Firmware and Software Updates in Loop Prevention
Network devices rely on firmware and software to manage switching behavior and loop prevention protocols. Outdated firmware may contain bugs or limitations that increase the risk of loop formation.
Regular updates ensure that devices support the latest protocols and security enhancements. In many cases, vendors release updates specifically aimed at improving loop detection and recovery mechanisms. Keeping network infrastructure up to date is a key part of maintaining stability.
Human Error as a Major Cause of Network Loops
Despite advances in automation and intelligent networking, human error remains one of the most common causes of network loops. Incorrect cable connections, misconfigured ports, or disabled safety features can all lead to loop formation.
During network expansion or maintenance, even a small oversight can introduce serious instability. This highlights the importance of proper training, documentation, and change management procedures in network administration.
Monitoring and Real-Time Alerting Systems
Modern networks rely heavily on monitoring systems to detect anomalies such as loops. These systems continuously analyze traffic patterns, device performance, and topology changes.
When unusual behavior is detected, such as sudden spikes in broadcast traffic or MAC address instability, alerts are generated to notify administrators. Real-time monitoring allows for faster response and reduces the potential damage caused by network loops.
Redundancy vs Stability Trade-Off in Network Design
One of the key challenges in network design is balancing redundancy with stability. While redundancy improves fault tolerance, it also increases the risk of loops if not properly managed.
Designers must carefully plan network topology to ensure that backup paths exist without creating circular dependencies. This often involves using hierarchical designs and strict control protocols to maintain a stable and efficient structure.
Future Trends in Loop Prevention Technologies
As networks continue to evolve, new technologies are being developed to improve loop prevention and detection. Artificial intelligence and machine learning are increasingly being used to analyze network behavior and predict potential loop conditions before they occur.
These advanced systems can identify abnormal traffic patterns and automatically adjust network configurations to prevent instability. This proactive approach represents a significant improvement over traditional reactive methods.
Network Loop Challenges in Hybrid and Multi-Cloud Environments
In modern IT infrastructures, many organizations operate in hybrid or multi-cloud environments where on-premises networks are connected with cloud-based services. This introduces additional layers of networking abstraction, making loop detection and prevention more complex. Data now travels across physical switches, virtual switches, and cloud routing systems, all of which must remain synchronized to avoid circular traffic flows.
When network policies are not consistently applied across these environments, logical loops can form between cloud gateways and internal network bridges. These loops are often harder to detect because they do not always follow traditional physical network patterns. Instead, they may exist within virtual routing configurations or misaligned synchronization between cloud and on-premises systems.
Influence of Overlay Networks on Loop Formation
Overlay networks, which are built on top of existing physical infrastructure, are widely used in virtualization and cloud networking. Technologies such as tunneling and encapsulation allow multiple virtual networks to coexist over a single physical network.
However, if overlay configurations are not properly designed, encapsulated traffic can circulate within virtual tunnels, creating hidden loops. These loops may not be visible at the physical layer, making troubleshooting significantly more difficult. Proper alignment between underlay and overlay networks is essential to maintain loop-free operation.
Latency Spikes and Performance Degradation Caused by Loops
One of the early signs of a network loop in complex environments is sudden and unpredictable latency spikes. As packets circulate repeatedly, network devices become overwhelmed with processing redundant traffic, leading to delays in packet forwarding.
This increased latency affects time-sensitive applications such as video streaming, online collaboration tools, and financial trading platforms. Even small delays can significantly impact user experience and operational efficiency, especially in globally distributed systems.
Impact on Load Balancing Systems
Load balancers distribute traffic across multiple servers to ensure optimal performance and resource utilization. However, network loops can interfere with load balancing algorithms by creating duplicate or inconsistent traffic paths.
When a loop exists, load balancers may receive repeated requests or conflicting session information, causing uneven distribution of traffic. This can lead to server overload on certain nodes while others remain underutilized, reducing overall system efficiency.
Role of ARP and Broadcast Traffic in Loop Propagation
Address Resolution Protocol (ARP) plays an important role in mapping IP addresses to MAC addresses within a local network. In loop conditions, excessive ARP requests and replies can circulate repeatedly, contributing to broadcast storms.
Since ARP relies heavily on broadcast communication, it becomes highly susceptible to amplification in loop scenarios. This further increases network congestion and accelerates performance degradation across connected devices.
Impact on Network Virtualization Platforms
Virtualization platforms rely on virtual switches to manage internal traffic between virtual machines. If these virtual switches are misconfigured, they can create internal loops that remain isolated from physical network visibility tools.
Such loops can severely impact virtual machine performance, causing delays in inter-VM communication and disrupting services hosted within the virtual environment. In extreme cases, entire virtual clusters may become unstable due to uncontrolled traffic circulation.
Spine-Leaf Architecture and Loop Reduction
Modern data centers often use spine-leaf network architecture to improve scalability and reduce latency. This design minimizes the number of hops between devices and provides predictable traffic flow patterns.
By eliminating complex hierarchical dependencies, spine-leaf architecture reduces the likelihood of accidental loop formation. However, proper configuration of routing protocols and leaf-spine connections is still essential to maintain a loop-free environment.
Impact of Network Loops on Cloud Service Availability
Cloud services depend heavily on stable and efficient networking to deliver consistent performance. When network loops occur, cloud service availability can be severely affected, leading to partial or complete service outages.
Users may experience slow response times, failed API calls, or inability to access cloud-hosted applications. In large-scale cloud environments, even a localized loop can have cascading effects across multiple regions or availability zones.
Detection Challenges in Encrypted Traffic Environments
With the increasing use of encryption protocols, detecting network loops has become more challenging. Encrypted traffic limits visibility into packet contents, making it harder for monitoring tools to analyze behavior at a granular level.
As a result, administrators must rely more on metadata, traffic patterns, and statistical anomalies to identify potential loop conditions. This requires more advanced analytics and intelligent monitoring systems.
Role of AI-Based Network Monitoring in Loop Prevention
Artificial intelligence is increasingly being used to enhance network monitoring capabilities. AI-based systems can analyze large volumes of network data in real time and detect abnormal patterns that may indicate a loop.
These systems can also predict potential loop conditions based on historical behavior and automatically adjust configurations to prevent issues before they escalate. This proactive approach significantly improves network resilience.
Impact on Disaster Recovery and Failover Systems
Disaster recovery systems are designed to maintain continuity during network or system failures. However, network loops can interfere with failover mechanisms by creating unstable routing paths.
When failover systems are triggered during a loop condition, they may inadvertently redirect traffic into already congested paths, worsening the situation. Proper coordination between redundancy and loop prevention is essential for effective disaster recovery.
Importance of Configuration Consistency Across Devices
Inconsistent configuration across network devices is a major contributor to loop formation. When switches and routers have mismatched settings, they may interpret network topology differently, leading to forwarding conflicts.
Maintaining standardized configurations across all devices ensures predictable behavior and reduces the likelihood of accidental loops. Configuration management tools are often used to enforce consistency across large-scale networks.
Long-Term Network Scalability Considerations
As networks continue to expand, scalability becomes a critical factor in loop prevention. Poorly designed networks may function well at small scale but become unstable as additional devices and connections are added.
Scalable network design requires careful planning of redundancy, routing policies, and segmentation strategies. Without these considerations, the probability of loop formation increases significantly over time.
Operational Best Practices for Large Enterprises
Large organizations must adopt strict operational practices to minimize loop risks. These include controlled change management processes, regular network audits, and automated configuration validation.
Training network administrators to recognize early warning signs of loops is also essential. A well-prepared operations team can respond quickly to issues before they escalate into major outages.
Conclusion
Network loops present a complex challenge in modern networking environments, especially as infrastructures become more virtualized, distributed, and cloud-integrated. Their impact extends across performance, security, availability, and scalability, making them one of the most critical issues in network management.
Through the use of advanced architectures, intelligent monitoring systems, standardized configurations, and proactive design strategies, organizations can effectively reduce the risk of network loops. A stable, well-optimized network ensures consistent performance, reliable connectivity, and seamless operation across all environments, from traditional data centers to modern cloud ecosystems.