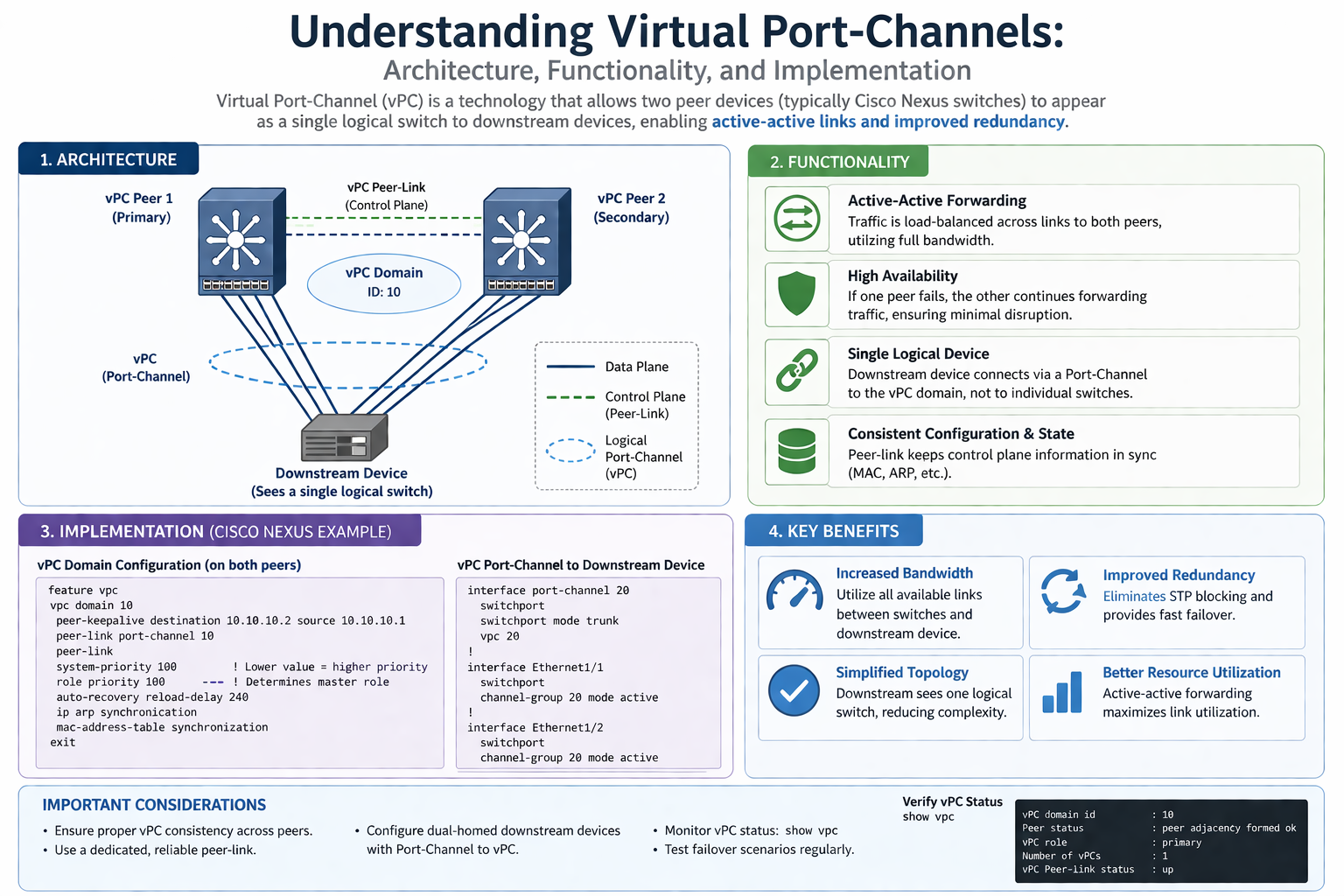
The peer-link is one of the most important elements in a Virtual Port-Channel environment because it acts as the communication bridge between the two vPC peer switches. Without this link, the switches cannot maintain synchronization, which is essential for stable forwarding decisions and consistent network operation.
The peer-link is typically configured as a Layer 2 trunk carrying multiple VLANs. It is responsible for synchronizing MAC address tables, ARP information, IGMP state, and various control-plane updates between both switches. This ensures that both peers always have the same understanding of the network and connected devices.
When traffic arrives on one switch for a destination known by the other switch, the peer-link allows the traffic to be forwarded correctly without interruption. This becomes especially important when orphan devices or traffic asymmetry exists in the environment.
Because of its importance, the peer-link should be built using multiple high-speed interfaces bundled into a port-channel. This improves both redundancy and bandwidth capacity. If the peer-link becomes congested or unstable, it can affect the entire vPC domain.
Network administrators must carefully protect the peer-link from failure by using reliable physical paths, proper monitoring, and consistent configuration practices. It should always be treated as a critical infrastructure connection rather than a normal uplink.
vPC Peer-Keepalive Link in Detail
The peer-keepalive link is often misunderstood because it does not carry normal data traffic. Its purpose is simple but extremely important: it allows each vPC peer switch to confirm that the other switch is still alive.
This link usually operates over a Layer 3 connection using management interfaces or routed ports. It sends heartbeat messages between the two switches. These heartbeat messages help prevent split-brain situations, where both switches incorrectly assume the other has failed and both try to act independently.
A split-brain condition can create serious network problems, including duplicate forwarding decisions, MAC flapping, and Layer 2 instability. The peer-keepalive link helps avoid this by providing a separate communication path outside the peer-link.
It is recommended that the peer-keepalive link be physically separate from the peer-link. If both links share the same path and that path fails, both switches may lose communication entirely, increasing the risk of incorrect failover behavior.
Although the keepalive link does not require high bandwidth, it must be stable and reliable. Even small failures on this link can trigger unnecessary alerts or operational concerns, so careful design is still important.
Understanding vPC Domains
A vPC domain is the logical structure that defines the relationship between the two participating switches. Both switches must belong to the same domain in order to form a proper vPC pair.
The domain ID is used internally for identification and coordination. It helps the switches recognize each other as peers and establish the synchronization process. The domain configuration must match correctly for successful operation.
Inside the domain, both switches maintain shared information while still operating as independent control planes. This is one of the major strengths of vPC. Unlike technologies that rely on a single active control plane, vPC allows both switches to maintain independence while still behaving like one logical system to connected devices.
This balance between independence and cooperation improves resilience. If one switch experiences a control-plane issue, the other can continue forwarding traffic without requiring complete failover of the entire environment.
A well-designed vPC domain forms the foundation for reliable dual-homed connectivity and should always be planned with long-term scalability in mind.
Role of Member Ports
Member ports are the physical interfaces that connect downstream devices to the vPC peer switches. These ports are bundled into a single logical port-channel and assigned a unique vPC number.
For example, a server with two network interfaces may connect one link to each switch. Through vPC, the server sees both links as one single logical connection rather than two separate paths. This simplifies configuration on the server side while improving redundancy and throughput.
Member ports can connect many different types of devices, including access switches, firewalls, load balancers, storage devices, and virtualization hosts. The downstream device does not need to understand the internal complexity of vPC. It only sees a normal EtherChannel or Link Aggregation Group.
Consistency is critical when configuring member ports. Speed, duplex, VLAN membership, trunk settings, allowed VLANs, and spanning-tree behavior must match exactly. Any mismatch can cause the port to be suspended automatically to protect the network.
Proper planning of member ports ensures smooth failover and maximum traffic efficiency, especially in high-demand environments such as enterprise data centers.
vPC and Spanning Tree Protocol Relationship
One of the most valuable benefits of vPC is its ability to reduce dependency on Spanning Tree Protocol while still maintaining loop-free Layer 2 connectivity.
In traditional Layer 2 designs, STP blocks redundant links to prevent loops. This means backup links remain idle and bandwidth is wasted. During a failure, STP must recalculate paths, which can introduce delay and temporary service interruption.
With vPC, both uplinks remain active simultaneously. Since the two switches appear as one logical switch to the downstream device, STP does not need to block one of the links. This enables active-active forwarding and better bandwidth utilization.
STP still exists in the environment and must still be configured properly, but its role becomes less disruptive. Instead of relying on blocked ports for protection, the network uses the vPC mechanism for loop prevention and path consistency.
This results in faster convergence, better application performance, and a more predictable traffic flow pattern across the network.
Administrators should still monitor root bridge placement and spanning-tree design carefully, especially in larger environments where non-vPC devices are also present.
vPC Failure Scenarios
Understanding failure behavior is critical for successful vPC operation. The goal of vPC is not only normal forwarding efficiency but also graceful behavior during unexpected outages.
If one vPC peer switch fails completely, the downstream device continues forwarding traffic through the remaining active switch. Since both links were already active, failover is fast and usually causes minimal disruption.
If the peer-link fails but the keepalive link remains active, the secondary switch typically suspends its vPC member ports to prevent split-brain behavior. This protects the network from loops and duplicate forwarding decisions.
If both the peer-link and keepalive link fail at the same time, the situation becomes more serious because each switch may not know whether the other is alive. Proper design helps minimize the chance of this event by separating both communication paths physically.
If only the peer-keepalive link fails while the peer-link remains active, traffic usually continues normally because synchronization still exists through the peer-link. However, administrators should investigate quickly because the backup protection path has been lost.
Testing these scenarios during maintenance windows helps teams understand operational behavior before real failures occur in production.
vPC Split-Brain Prevention
Split-brain is one of the most dangerous situations in a vPC environment. It happens when both peer switches believe the other has failed and both try to independently forward traffic without proper coordination.
This can lead to MAC address instability, duplicate packet forwarding, loops, and major service disruption. Preventing split-brain is one of the primary design goals of the peer-keepalive mechanism.
The keepalive link ensures that even if the peer-link fails, each switch can still confirm whether the peer is alive. If communication continues over keepalive, the switches know the issue is only the peer-link and can apply safe protection mechanisms.
Secondary role behavior is important here. In many designs, the secondary switch will suspend vPC member ports if peer-link communication is lost while keepalive remains active. This avoids both switches forwarding independently.
Good design practices such as separate keepalive paths, stable management connectivity, and proper monitoring greatly reduce split-brain risk and improve long-term reliability.
vPC Consistency Checks
Consistency checks are built into vPC to protect the network from misconfiguration. Since both switches must behave as a single logical system, mismatched settings can cause major operational problems.
There are two main types of consistency parameters: Type 1 and Type 2.
Type 1 mismatches are critical and usually cause the affected vPC ports to be suspended. Examples include STP mode mismatches, VLAN inconsistencies, and port-channel compatibility problems. These are serious enough to stop forwarding because they could create instability.
Type 2 mismatches are less severe and usually generate warnings without immediate port shutdown. These may include settings that should be aligned for best practice
vPC Consistency Checks Continued
Even though Type 2 mismatches may not immediately disable traffic forwarding, they should never be ignored. Over time, these small differences can create troubleshooting challenges, unexpected forwarding behavior, and operational confusion. A stable vPC design depends on both switches behaving as closely as possible to a single logical unit.
Examples of Type 2 mismatches may include differences in quality of service settings, certain VLAN parameters, or interface-level optional features. While traffic may continue to pass, the network may not behave predictably during failover conditions or maintenance windows.
Administrators should regularly verify consistency status using operational commands and monitoring systems. Waiting until a production outage occurs is never a good strategy. Preventive validation helps maintain long-term reliability.
Documentation also plays a major role. Keeping detailed records of configuration standards makes it easier for teams to maintain consistency across both peer switches, especially in large enterprise environments where multiple engineers manage the infrastructure.
Consistency checks are not just technical safeguards—they are operational tools that help ensure confidence in every failover event and daily network activity.
vPC Orphan Ports Explained
An orphan port is a device connection that exists on only one of the two vPC peer switches instead of being dual-homed across both switches. These ports are common in real-world environments because not every device supports dual connections or port-channel configurations.
For example, a single-homed server, printer, management appliance, or legacy device connected to only one switch becomes an orphan port. While this is normal in some designs, it introduces special considerations during failure events.
If the switch hosting the orphan port fails, the connected device loses network access because it has no secondary path. This is different from dual-homed devices using vPC, which continue forwarding through the surviving peer switch.
Another challenge appears during peer-link failure scenarios. Depending on the design and traffic flow, orphan ports may experience communication issues if traffic forwarding relies heavily on peer synchronization.
Administrators should identify orphan ports clearly and evaluate whether they require additional protection. In some critical environments, orphan devices may need redesign or migration to dual-homed connectivity for better availability.
Understanding orphan port behavior helps prevent unexpected outages and improves overall network planning.
vPC for Server Connectivity
One of the most common use cases for vPC is server connectivity in modern data centers. Servers often require both high availability and maximum bandwidth, making vPC an ideal solution.
A server with multiple network interface cards can connect one link to each vPC peer switch. From the server’s perspective, both links appear as a single logical port-channel. This allows active-active communication without relying on one standby link.
This design improves bandwidth utilization because both links forward traffic simultaneously. It also provides fast failover. If one switch or one physical link fails, the server continues operating through the remaining active path with little interruption.
Virtualization platforms such as hypervisors especially benefit from this architecture because they often carry large volumes of east-west traffic between virtual machines, storage systems, and application clusters.
Storage environments also rely heavily on stable server connectivity. Database systems, backup platforms, and clustered applications require consistent network access, and vPC helps support these requirements with reduced downtime risk.
The simplicity from the server side is another advantage. Most servers only require standard NIC teaming or LACP configuration without needing awareness of the internal vPC design.
This combination of performance, redundancy, and operational simplicity makes vPC a preferred design for enterprise server networks.
vPC for Access Layer Connectivity
vPC is also widely used between access switches and aggregation or distribution switches. In campus and data center environments, uninterrupted uplink connectivity is critical for end-user access and application availability.
Traditionally, an access switch connected to two upstream switches would depend heavily on Spanning Tree Protocol, with one uplink often blocked. This wasted bandwidth and introduced slower failover times during failures.
With vPC, both uplinks remain active at the same time. The access switch sees the upstream pair as one logical port-channel and can forward traffic across both links simultaneously.
This improves throughput and allows better load balancing across the available infrastructure. It also reduces the impact of maintenance activities because one upstream switch can be serviced while the other continues forwarding traffic.
Network administrators benefit from simplified operations because failover becomes more predictable and less dependent on STP recalculation events.
This design is especially valuable in environments with high user density, application-heavy workloads, or strict uptime requirements where access layer resilience directly affects business operations.
vPC with Firewalls and Security Appliances
Firewalls, intrusion prevention systems, and other security appliances are often deployed in high-availability pairs, making them strong candidates for vPC connectivity.
A firewall with dual interfaces can connect to both vPC peer switches and use a single logical port-channel for stable traffic forwarding. This removes single points of failure and supports uninterrupted inspection of network traffic.
Load balancers, VPN gateways, and security monitoring appliances also benefit from this architecture because they often sit in critical traffic paths where downtime must be minimized.
Without vPC, these devices might rely on STP-blocked links or complex failover mechanisms that introduce delay during outages. With vPC, both links remain active and traffic distribution becomes more efficient.
Security environments must still be designed carefully because asymmetric routing and stateful inspection can create challenges. Administrators should ensure that traffic paths remain consistent and appliance behavior aligns with the active-active forwarding model.
Proper integration of security appliances with vPC improves both resilience and operational stability while maintaining strong network protection.
vPC with Storage Networks
Storage traffic demands high reliability, low latency, and consistent performance. This makes vPC highly valuable in storage network designs where interruptions can affect critical business applications.
Storage arrays often connect to multiple switches for redundancy. Using vPC allows these connections to remain active simultaneously instead of depending on blocked standby paths.
Applications such as databases, virtualization clusters, backup systems, and disaster recovery platforms depend heavily on uninterrupted storage access. A short network outage can lead to application failures, performance degradation, or service downtime.
By using vPC, storage devices gain faster failover and better bandwidth usage. Both links participate in traffic forwarding, which improves throughput for replication, backup transfers, and real-time application access.
This is especially useful in environments using network-attached storage, IP-based storage systems, or converged infrastructure where storage and application traffic share common switching platforms.
Careful VLAN planning and interface consistency remain important because storage systems are often sensitive to path instability. Strong vPC design helps protect these critical workloads from avoidable disruption.
vPC and Layer 3 Design Considerations
Although vPC is primarily a Layer 2 technology, Layer 3 design decisions strongly influence its stability and performance.
Many data center networks use Layer 3 routing at the aggregation or core layer while maintaining Layer 2 connectivity for server access and application clustering. vPC fits naturally into this model by providing stable Layer 2 dual-homing below the routing boundary.
Routing protocols such as OSPF, EIGRP, or BGP may operate above or around the vPC environment depending on the architecture. Designers must ensure that Layer 3 failover aligns smoothly with Layer 2 behavior.
The peer-keepalive link itself is typically a Layer 3 connection, which highlights the importance of reliable routed communication even inside a primarily Layer 2 feature.
Default gateway placement is another important factor. Technologies like first-hop redundancy protocols may work alongside vPC to provide resilient gateway services for downstream devices.
Administrators should avoid unnecessary complexity by clearly defining where Layer 2 ends and Layer 3 begins. Overextending Layer 2 domains can create larger failure zones and more difficult troubleshooting.
A balanced design combines the resilience of vPC with the scalability and control of strong Layer 3 architecture.
vPC and VLAN Planning
VLAN design directly affects vPC stability. Since the peer-link carries VLAN synchronization and forwarding information, administrators must carefully plan which VLANs are allowed and how they are distributed.
The peer-link should include all VLANs required for proper vPC operation. Missing VLANs can lead to traffic black holes, inconsistent forwarding, or suspended ports during validation checks.
At the same time, unnecessary VLAN extension should be avoided. Expanding VLANs beyond their required boundaries increases broadcast domains and operational complexity.
Critical application VLANs, management networks, storage traffic, and virtualization platforms should all be mapped carefully with redundancy and isolation in mind.
Consistency between peer switches is essential. VLAN IDs, names, spanning-tree settings, and trunk permissions should match exactly. Even small differences can trigger warnings or service impact.
Good VLAN planning improves troubleshooting speed and helps maintain predictable failover behavior during both planned maintenance and unexpected outages.
A disciplined VLAN strategy supports the long-term health of the entire vPC environment rather than simply making the initial deployment successful.
vPC and First-Hop Redundancy Protocols
First-Hop Redundancy Protocols such as HSRP, VRRP, and GLBP are commonly used with vPC to provide resilient default gateway services for downstream devices. While vPC handles Layer 2 path redundancy, these protocols ensure that end devices always have access to a reliable Layer 3 gateway.
In many designs, both vPC peer switches participate in gateway services while presenting stable forwarding paths to connected servers and access switches. This creates a strong active-active architecture where traffic can move efficiently without depending on a single switch.
Careful planning is required so that the forwarding path and gateway path remain aligned. If traffic enters through one switch but must always leave through another, unnecessary peer-link utilization can occur. This may create congestion and inefficient traffic flow.
Features such as active gateway behavior improve this design by allowing both switches to forward traffic more naturally. This reduces dependency on peer-link traversal and supports better performance.
Gateway placement should always match the application design and routing strategy of the environment. Proper integration of vPC and first-hop redundancy protocols creates a seamless user experience with minimal failover impact.
vPC and Load Balancing
Load balancing is one of the major operational advantages of vPC because both uplinks remain active and available for forwarding traffic. Instead of one blocked standby path, the network uses all available bandwidth for better efficiency.
Traffic distribution depends on hashing algorithms that evaluate source and destination information such as MAC addresses, IP addresses, or transport-layer details. This helps spread flows across multiple physical links inside the port-channel.
The quality of load balancing depends on traffic patterns. A large number of diverse flows usually creates excellent distribution, while a small number of very large flows may lead to uneven utilization across links.
Administrators should understand how the switching platform performs hashing and verify that the selected method aligns with application requirements. Different environments may benefit from different load-balancing strategies.
Monitoring is important because traffic imbalance can create false assumptions about congestion or performance problems. Sometimes the issue is not lack of bandwidth but poor distribution of active flows.
Proper load balancing ensures that vPC delivers its full value by maximizing throughput and improving the efficiency of expensive data center infrastructure.
vPC and Maintenance Operations
One of the strongest business advantages of vPC is simplified maintenance. Network teams can perform upgrades, hardware replacements, and software changes with reduced service interruption compared to traditional single-path designs.
Because both switches actively forward traffic, administrators can take one switch offline for maintenance while the other continues serving downstream devices. This supports rolling upgrades and controlled operational changes.
Software upgrades become less disruptive because failover does not depend entirely on Spanning Tree reconvergence. Devices continue forwarding through the surviving peer while maintenance is performed on the other switch.
Hardware replacement also becomes safer. Line cards, supervisors, power supplies, and other components can often be serviced with reduced impact when the design is planned correctly.
However, maintenance must still follow careful procedures. Incorrect shutdown order, peer-link disruption, or configuration mismatches introduced during upgrades can create unexpected outages.
Pre-change validation, peer health checks, and rollback planning are essential. vPC reduces operational risk, but it does not eliminate the need for disciplined change management.
Well-managed maintenance processes are one of the reasons vPC is highly valued in enterprise and data center environments.
vPC Monitoring and Troubleshooting
Strong monitoring is necessary for stable vPC operations because many failures begin as small inconsistencies before becoming major outages. Administrators should regularly verify peer-link health, keepalive status, consistency checks, and interface behavior.
Operational commands provide visibility into peer status, role assignments, suspended ports, orphan port conditions, and synchronization details. These checks help identify warning signs before users notice service disruption.
MAC address movement, unexpected peer-link traffic spikes, and repeated keepalive alerts are often early indicators of deeper problems. Ignoring these signs can lead to difficult troubleshooting later.
Log analysis is also important. Events related to VLAN mismatches, port suspensions, or peer role changes should be investigated quickly rather than treated as normal background noise.
Performance monitoring should include bandwidth utilization across member links and peer-links. High peer-link usage may indicate poor traffic path design or gateway misalignment.
A good troubleshooting process focuses first on peer-link health, keepalive stability, and consistency status because many visible symptoms originate from these areas.
Proactive monitoring transforms vPC from a reactive support challenge into a predictable and stable infrastructure platform.
vPC Best Practices
Successful vPC deployment depends heavily on following best practices rather than simply enabling the feature. Strong design choices prevent most operational problems before they appear.
The peer-link should always use multiple high-speed interfaces bundled into a resilient port-channel. This avoids single points of failure and provides enough capacity for synchronization traffic and failover events.
The peer-keepalive link should remain physically separate from the peer-link path. Shared infrastructure increases the risk of simultaneous failure and split-brain conditions.
Configuration consistency must be treated as a strict requirement, not a recommendation. VLANs, port-channel settings, spanning-tree behavior, and interface parameters should match exactly across both peers.
Critical devices should be dual-homed whenever possible to avoid orphan port risk. Where orphan ports must exist, their behavior should be documented and monitored carefully.
Peer switch software versions and feature compatibility should also be planned carefully. Unsupported combinations can create hidden operational issues.
Regular testing of failover scenarios ensures that the design behaves as expected under real failure conditions. Best practices are valuable only when validated in production-ready operations.
vPC Common Mistakes
Many vPC problems come from avoidable design mistakes rather than platform limitations. Understanding these mistakes helps administrators build stronger and safer environments.
One common mistake is underestimating the importance of the peer-link. Treating it like a normal trunk instead of critical infrastructure can create bandwidth shortages and operational instability.
Another frequent issue is placing the peer-keepalive link on the same physical path as the peer-link. This removes failure isolation and increases split-brain risk during outages.
Configuration mismatches are also a major source of trouble. Even small VLAN or trunk differences can lead to suspended ports, failed failover, or unpredictable traffic flow.
Ignoring orphan ports creates false assumptions about redundancy. A network may appear highly available while single-homed critical devices remain vulnerable to simple switch failures.
Poor gateway alignment often leads to excessive peer-link traffic. This reduces efficiency and may create performance bottlenecks during high-demand periods.
Skipping failure testing is another serious mistake. A design that looks correct on paper may behave differently during real outages. Validation is essential for confidence.
Avoiding these mistakes significantly improves both stability and long-term operational trust in the vPC environment.
vPC and Data Center Scalability
Modern data centers must support continuous growth, and vPC helps create scalable Layer 2 connectivity without sacrificing availability. As server density increases, active-active forwarding becomes more valuable.
Large virtualization clusters, cloud platforms, and application farms require efficient bandwidth usage because traffic volume grows rapidly over time. vPC ensures that both physical paths contribute to performance instead of leaving backup links idle.
Scalability also improves because devices can be added without major architectural redesign. New servers, storage systems, and access switches can join the environment using the same predictable dual-homed model.
Operational scaling matters as much as technical scaling. Standardized vPC design reduces complexity for engineering teams and makes troubleshooting faster as the environment expands.
However, scalability requires discipline. Extending Layer 2 too far without clear boundaries can create oversized failure domains and management challenges. vPC should support growth, not encourage uncontrolled network expansion.
Combining vPC with strong Layer 3 architecture allows organizations to scale performance while maintaining fault isolation and operational clarity.
This balance makes vPC a long-term strategy rather than only a short-term redundancy feature.
Comparing vPC with Traditional Port-Channels
A traditional port-channel combines multiple physical links into one logical connection, but all links typically terminate on the same physical switch. This improves bandwidth and redundancy only within that single device.
If that switch fails, the entire port-channel becomes unavailable because all links depend on one upstream device. This creates a major limitation for environments that require continuous availability.
vPC removes this limitation by allowing the port-channel to span two separate physical switches. The downstream device still sees one logical connection, but physical redundancy now exists across multiple switches.
This creates stronger fault tolerance because failure of one switch does not remove the entire connection. Traffic continues through the surviving peer with minimal disruption.
Traditional port-channels are simpler and may be suitable for smaller environments where switch-level redundancy is less critical. However, enterprise data centers usually require the higher availability provided by vPC.
The choice depends on business requirements, but for mission-critical workloads, the difference between switch-level redundancy and link-level redundancy is extremely important.
This is why vPC is considered a major advancement over traditional single-switch port-channel designs.
Final Operational Perspective
vPC is not simply a configuration feature—it is a design philosophy focused on resilience, active-active forwarding, and operational stability. Its value comes from how it changes the way redundancy is delivered in modern networks.
Instead of accepting blocked links and slow failover as normal behavior, vPC creates a more efficient architecture where both performance and availability improve together.
Its success depends on careful planning, consistent configuration, and strong operational discipline. Peer-links, keepalive paths, VLAN design, gateway placement, and monitoring all contribute to the final outcome.
Organizations that treat vPC as strategic infrastructure rather than a quick technical feature gain the greatest long-term benefit. It supports maintenance flexibility, business continuity, and scalable growth across critical services.
For data centers, enterprise networks, and high-availability application environments, vPC remains one of the most valuable Layer 2 design technologies for building stable and future-ready infrastructure.
vPC Security and Stability Considerations
Security and stability must always be part of vPC planning because a highly available network should also remain protected and controlled. Access to peer-link interfaces, management paths, and configuration changes should be restricted only to authorized administrators. Since the peer-link carries critical synchronization traffic, any misconfiguration or unauthorized change can affect the entire vPC domain. Strong monitoring, role-based access control, and regular configuration backups help reduce operational risk and improve recovery speed during incidents.
Stability also depends on software lifecycle management. Running unsupported software versions or mismatched feature sets between peer switches can create hidden problems that may only appear during failover events. Regular upgrades, compatibility validation, and lab testing before production deployment help maintain a stable environment. Security policies should also include logging, alerting, and clear incident response procedures so that network teams can quickly identify and resolve abnormal behavior.
Future of vPC in Modern Networks
As data centers continue to grow and support cloud services, virtualization, and high-performance applications, the importance of resilient Layer 2 design remains strong. vPC continues to play a major role because it provides a practical balance between redundancy, performance, and operational simplicity. Even in environments adopting software-defined networking and advanced automation, the need for stable dual-homed connectivity remains essential.
Modern architectures often combine vPC with automation platforms, orchestration tools, and advanced monitoring systems to improve operational efficiency. This allows faster deployment, better consistency, and reduced human error during configuration changes. While network technologies continue to evolve, the core principles of vPC—active-active forwarding, reduced failure impact, and simplified redundancy—remain highly valuable for enterprise and data center design.
vPC Documentation and Change Management
Proper documentation is a critical part of successful vPC operations because even a well-designed network can become difficult to manage without clear records. Administrators should maintain detailed information about peer-link design, keepalive paths, VLAN assignments, port-channel mappings, orphan ports, and failover procedures. Accurate documentation helps teams respond faster during troubleshooting and reduces the risk of human error during upgrades or emergency maintenance. It also supports smoother knowledge transfer when multiple engineers manage the same environment.
Change management is equally important because small configuration changes can have large effects in a vPC domain. Every modification should be reviewed carefully, tested when possible, and scheduled with rollback planning in place. Configuration consistency between both peer switches must always be verified after changes are applied. Controlled change management reduces unexpected outages and ensures that network reliability is maintained even as the environment grows and evolves.
vPC and Disaster Recovery Planning
Disaster recovery planning should include vPC behavior because network resilience is a major part of business continuity. During major failures such as power outages, hardware loss, or site-level disruption, understanding how vPC reacts helps organizations restore services faster. Administrators should test peer switch recovery, peer-link restoration, and failover behavior during controlled maintenance windows so that emergency responses are based on real operational knowledge rather than assumptions.
Backup strategies should also include configuration snapshots, peer switch state validation, and clear recovery procedures for rebuilding the vPC domain if needed. In multi-site environments, vPC may work alongside disaster recovery solutions such as redundant data centers and application failover platforms. Strong planning ensures that vPC supports larger business continuity goals and helps maintain service availability even during unexpected large-scale incidents.
Conclusion
Virtual Port-Channels provide a powerful and reliable approach to building high-availability network infrastructure. By allowing two physical switches to function as one logical system for downstream devices, vPC improves redundancy, bandwidth utilization, and operational flexibility. It removes many of the limitations of traditional Layer 2 designs and reduces dependence on blocked links and slow failover processes.
From server connectivity and storage networks to access layer design and security appliance integration, vPC supports a wide range of critical business applications. Its success depends on strong peer-link design, reliable keepalive communication, configuration consistency, and proactive monitoring. When implemented with proper planning and best practices, vPC becomes more than a technical feature—it becomes a foundation for stable, scalable, and future-ready network architecture.