One of the biggest reasons NoSQL databases work so well with serverless architecture is their ability to handle changing workloads without requiring major structural changes. In traditional systems, databases often rely on fixed schemas, which means every table and relationship must be carefully planned in advance. While this works well for highly structured applications, it can slow down development in modern cloud environments where speed and flexibility matter most.
Serverless applications are often built for rapid deployment and continuous updates. Features change quickly, user behavior shifts unexpectedly, and traffic patterns may rise or fall within minutes. NoSQL databases support this environment because they allow developers to store data without being restricted by rigid table structures. This flexibility makes development faster and reduces the effort required when the application grows or changes direction.
Another major advantage is horizontal scalability. Instead of upgrading one powerful server, NoSQL systems can distribute data across multiple machines. This approach matches serverless architecture perfectly because serverless functions also scale horizontally by handling many requests at the same time. When both the application layer and the database layer scale together, performance remains stable even during sudden traffic spikes.
NoSQL databases also provide excellent performance for applications that require frequent read and write operations. Mobile apps, messaging platforms, gaming systems, and real-time analytics tools often depend on extremely fast responses. Since serverless systems are commonly used for these types of applications, NoSQL databases become a natural choice for maintaining speed without sacrificing scalability.
Cost efficiency is another reason businesses prefer NoSQL in serverless environments. Many modern NoSQL platforms use usage-based pricing, meaning companies pay only for the resources they actually consume. This aligns with the core principle of serverless architecture, where billing is based on execution rather than reserved infrastructure. For startups and growing businesses, this pricing model helps control expenses while supporting future expansion.
When Relational Databases Are the Better Choice
Although NoSQL databases are popular in serverless systems, relational databases remain essential for many business applications. Structured data still plays a major role in industries where precision, consistency, and transactions are critical. Banking systems, healthcare platforms, enterprise resource planning tools, and booking systems often depend on strict data relationships that relational databases manage very effectively.
Relational databases organize information into tables with clearly defined relationships between records. This structure makes it easier to maintain data integrity and prevent errors. For example, when processing payments, inventory records, and customer accounts, even a small inconsistency can create serious problems. Serverless architecture does not remove this need for reliability, which is why managed relational databases continue to be highly valuable.
The key difference in serverless environments is that businesses usually prefer managed versions of relational databases instead of self-hosted ones. Managing database servers manually creates operational overhead that goes against the purpose of serverless computing. Fully managed services reduce this burden by handling backups, updates, failover protection, and scaling automatically. This allows development teams to focus on application logic rather than infrastructure maintenance.
Relational databases are also stronger when complex queries are required. Reporting systems, analytics dashboards, and enterprise applications often need advanced joins, filtering, and transaction control. These operations are often easier and more efficient in SQL-based systems. If the application depends heavily on reporting and structured business logic, a managed relational database can outperform a NoSQL alternative.
The best approach is not always choosing one over the other. Many organizations use relational databases for core business operations and NoSQL databases for high-speed application features. This hybrid model creates a balance between reliability and flexibility, giving serverless systems the benefits of both worlds.
The Growing Importance of Serverless-Native Databases
As serverless architecture becomes more common, databases designed specifically for this model are becoming increasingly important. Serverless-native databases are built with automatic scaling, on-demand capacity, and usage-based billing at their core. Instead of adapting traditional systems for cloud workloads, these databases are created from the beginning to work with modern serverless applications.
One of their strongest advantages is instant scalability. In traditional systems, teams often need to predict future traffic and provision resources in advance. If the estimate is too low, performance suffers. If the estimate is too high, money is wasted. Serverless-native databases remove this problem by adjusting capacity automatically based on actual demand. This makes them ideal for businesses with unpredictable traffic patterns such as ecommerce platforms, seasonal services, or event-based applications.
Another benefit is simplified operations. Developers do not need to manage servers, configure complex clusters, or worry about infrastructure tuning. The platform handles performance optimization behind the scenes. This reduces operational complexity and helps smaller teams launch applications faster without requiring large database administration departments.
These databases are also highly available by design. Replication, backup management, and fault tolerance are usually included as standard features. Since serverless applications often serve users across multiple regions and time zones, high availability becomes essential for maintaining reliability and customer trust.
Billing efficiency is especially attractive for businesses trying to control costs. Instead of paying for idle database servers running all day, organizations are charged based on actual usage. During low traffic periods, costs remain low. During peak demand, the system expands automatically without manual intervention. This creates strong financial efficiency for both startups and enterprise systems.
For modern digital products where speed, scalability, and cost control matter equally, serverless-native databases often provide the most balanced long-term solution.
The Role of In-Memory Databases in Performance Optimization
While primary databases store the main business data, performance often depends heavily on how quickly users can access frequently requested information. This is where in-memory databases become valuable. Instead of storing data on slower disk systems, these databases keep information directly in memory, allowing much faster retrieval times.
In serverless applications, response speed is extremely important because users expect instant results. Delays of even a few seconds can affect customer satisfaction and reduce engagement. In-memory databases help solve this problem by acting as a high-speed layer between the application and the primary database.
They are commonly used for caching product pages, session data, authentication tokens, user preferences, and real-time analytics. For example, an online shopping platform may use an in-memory database to store popular product details so customers can access them instantly without repeated requests to the main database.
This reduces pressure on the primary database and improves overall system efficiency. Since serverless functions may scale rapidly during busy periods, reducing unnecessary database calls becomes critical for maintaining stable performance and avoiding unnecessary costs.
In-memory databases are also useful for event-driven applications such as gaming platforms, chat systems, and live dashboards where updates happen continuously. These systems require near-instant communication, and memory-based storage provides the speed needed for smooth user experiences.
However, they are usually not used as the only database because memory storage is more expensive and may not provide the same long-term persistence as traditional storage systems. Instead, they work best as a supporting layer combined with relational, NoSQL, or serverless-native databases.
When designed properly, this combination creates a powerful architecture where speed and reliability work together instead of competing with each other.
How Data Consistency Affects Database Selection
Choosing the best database for serverless architecture also depends heavily on consistency requirements. Not every application needs the same level of precision. Some systems can tolerate slight delays in data synchronization, while others require every transaction to be perfectly accurate in real time.
For example, social media platforms can often accept eventual consistency. If a like count updates a few seconds later, the user experience is usually not harmed. In these cases, NoSQL databases perform very well because they prioritize availability and scalability over strict transaction control.
On the other hand, banking systems, airline reservations, and medical record platforms require immediate consistency. A payment must be recorded correctly the first time. A booked seat cannot be sold twice. Patient information must remain accurate at all times. These situations demand stronger transaction guarantees, making relational databases a better fit.
Serverless architecture does not eliminate these business requirements. Instead, it makes the database decision even more important because the application layer is highly distributed. Without the right consistency model, scaling the application can increase the risk of data conflicts.
Understanding the balance between consistency, availability, and performance helps organizations choose the right database system. This decision should be based on business priorities rather than trends. The most scalable option is not always the best if it creates operational risks for the business.
A strong serverless design begins with understanding how critical the data really is and selecting a database that protects that value.
Security and Compliance Considerations
Database selection in serverless architecture is not only about speed and scaling. Security and compliance are equally important, especially for businesses handling customer records, financial transactions, or sensitive personal information. The database must support strong protection mechanisms while fitting into the automated nature of serverless systems.
Managed databases often provide stronger security benefits because many core protections are handled automatically. Encryption, backup management, patching, and access control are built into the platform, reducing the chance of human error. This is particularly important in serverless environments where teams want to minimize infrastructure responsibilities.
Access management must also be carefully planned. Since serverless functions are triggered automatically by events, permissions should follow the principle of least privilege. Each function should access only the data it truly needs. This reduces the risk of unauthorized access if a function is compromised.
Compliance requirements such as data retention policies, audit trails, and regional storage rules may also influence database choice. Some industries require detailed transaction histories and strict reporting capabilities, which often make relational databases more suitable. Others prioritize fast global delivery and flexible storage, making NoSQL solutions more practical.
Security should never be treated as an afterthought. A highly scalable serverless system loses its value if customer trust is damaged by weak database protection. The best database is one that supports both performance and long-term business responsibility.
Building a Hybrid Database Strategy
In many real-world applications, the strongest solution is not a single database type but a combination of multiple systems working together. This approach is known as a hybrid database strategy, and it is becoming increasingly common in serverless architecture.
For example, an ecommerce platform may use a relational database for orders, payments, and inventory because these require strong consistency and transaction reliability. At the same time, it may use a NoSQL database for customer activity tracking, product recommendations, and search optimization because these features require speed and flexibility.
An in-memory database may then be added to improve caching performance, while a serverless-native analytics database handles reporting and event processing. Each system serves a specific purpose based on business needs rather than forcing one technology to handle every task.
This strategy improves performance and allows each component to operate where it is strongest. It also reduces the risk of overloading a single database with responsibilities it was not designed to handle.
The challenge is maintaining good integration and clear data flow between systems. Without proper planning, complexity can increase quickly. Strong architecture design, event-driven communication, and clear ownership of data are essential for making hybrid systems successful.
When done correctly, a hybrid model provides the flexibility needed for modern serverless applications while protecting reliability, speed, and cost efficiency across the entire platform.
Understanding Database Latency in Serverless Applications
Database latency plays a major role in the overall performance of serverless applications. Since serverless functions are designed to execute quickly and respond instantly to events, even small delays in database communication can create noticeable performance issues. If the database takes too long to respond, the speed advantage of serverless architecture begins to disappear.
Latency becomes especially important because serverless functions are often short-lived. They are triggered, complete a task, and shut down within seconds. If most of that execution time is spent waiting for database queries, the application becomes less efficient and more expensive because billing is often tied to execution duration.
One common challenge is the cold start problem combined with database connections. When a serverless function starts after inactivity, establishing a new database connection can take time. This delay becomes more visible in high-frequency applications where fast response times are expected. Databases that support efficient connection pooling or serverless-native connection handling reduce this issue significantly.
Geographic distance also affects latency. If the application runs in one region and the database is hosted far away, every request takes longer to complete. For global applications serving customers across multiple countries, choosing the right deployment regions and replication strategies becomes critical for maintaining strong performance.
Caching strategies help reduce latency by limiting unnecessary database requests. Frequently accessed data can be stored closer to the application layer, reducing repeated queries to the main database. This not only improves speed but also lowers database costs by reducing resource consumption.
Latency should always be considered during database selection because performance problems are often caused by slow data access rather than weak application code. A fast serverless function still depends on a fast database response to deliver a strong user experience.
Connection Management Challenges in Serverless Databases
Traditional applications often maintain long-running database connections because servers remain active continuously. Serverless architecture works differently. Functions are created and destroyed rapidly, making persistent database connections much harder to manage efficiently.
If thousands of serverless functions are triggered at the same time, each trying to open a new database connection, the database can quickly become overloaded. This issue is especially common with traditional relational databases that were originally designed for stable server-based applications rather than burst-driven workloads.
Connection limits become a serious concern because many relational databases support only a fixed number of simultaneous active connections. If this limit is exceeded, users may experience failed requests, slow performance, or complete service interruptions.
Connection pooling helps solve this problem by allowing multiple function executions to share a smaller number of active database connections. Managed services often provide built-in pooling features that improve stability without requiring manual configuration.
Serverless-native databases are even better prepared for this challenge because they are designed to handle high-frequency connection patterns automatically. Instead of relying on traditional connection models, they often use optimized request handling systems that match serverless workloads more effectively.
Developers must also design functions carefully to avoid unnecessary database calls. Opening a connection for every minor task increases both latency and operational costs. Efficient architecture means minimizing connection creation while keeping the application responsive and secure.
Good connection management is often invisible to users, but it is one of the most important factors in building reliable serverless applications. Poor connection handling can destroy scalability even when the rest of the architecture is well designed.
How Event-Driven Workloads Influence Database Choice
Serverless systems are often built around event-driven architecture, where actions happen in response to triggers such as user requests, file uploads, payment confirmations, or system alerts. This model changes how databases are used and strongly influences which type works best.
In traditional systems, applications may rely on scheduled operations and predictable traffic patterns. In event-driven systems, workloads are much less predictable. A marketing campaign, viral social media post, or seasonal sales event can suddenly create massive demand within minutes.
Databases supporting event-driven workloads must handle sudden bursts of activity without delays or failures. NoSQL and serverless-native databases perform well in these situations because they are designed for rapid scaling and high write throughput.
For example, when a customer places an order, multiple events may happen instantly. Payment processing starts, inventory updates, email confirmations are triggered, analytics are recorded, and shipping workflows begin. Each event may interact with different database services at the same time.
This requires strong performance under concurrency, where many operations happen simultaneously without conflict. Databases with weak scaling capabilities struggle under this pressure, creating slowdowns across the entire business workflow.
Message queues and event streams often work alongside the database to improve reliability. Instead of forcing immediate direct database writes during heavy traffic, events can be processed asynchronously. This reduces pressure on the main database and improves stability during peak demand.
Choosing a database for event-driven workloads means thinking beyond storage alone. The database must fit naturally into a larger automated system where speed, reliability, and scalability all work together.
Backup and Disaster Recovery in Serverless Data Systems
Even the most scalable database is not complete without strong backup and disaster recovery planning. Serverless architecture improves automation, but it does not remove the risk of accidental deletion, system failures, or security incidents. Protecting data remains one of the highest business priorities.
Managed databases often provide automatic backups as part of the service. This is a major advantage because it reduces manual operational work and ensures recovery options are always available. Point-in-time recovery allows teams to restore data to a specific moment before an error occurred, which is extremely valuable during production incidents.
Replication across multiple regions also improves resilience. If one region experiences downtime, another can continue serving users with minimal interruption. For businesses operating internationally, this level of redundancy is often essential rather than optional.
Disaster recovery planning should include more than technical backups. Teams must understand recovery time objectives and recovery point objectives. These determine how quickly systems must return online and how much data loss is acceptable. Different industries have very different expectations in this area.
For example, a content platform may tolerate small delays in recovery, while a payment platform may require near-instant failover with almost zero data loss. The database choice must support these business requirements from the beginning.
Testing recovery plans is just as important as creating them. Many organizations assume backups are working until a real failure proves otherwise. Regular testing ensures that recovery processes actually function under pressure.
A database that scales perfectly but cannot recover safely from failure creates serious long-term risk. Reliability includes both everyday performance and the ability to survive unexpected problems without major business damage.
Cost Optimization Strategies for Serverless Databases
Cost control is one of the biggest reasons businesses adopt serverless architecture, but poor database choices can quickly remove those savings. Understanding how database pricing works is essential for building an efficient and sustainable system.
Traditional databases often require fixed provisioning, meaning companies pay for reserved capacity even during periods of low activity. This creates waste when applications experience irregular traffic. Serverless databases reduce this problem by charging based on actual usage, allowing businesses to align costs more closely with demand.
However, usage-based pricing also requires careful monitoring. High traffic, inefficient queries, or excessive read and write operations can increase costs unexpectedly. Without visibility into database usage, expenses may grow faster than expected.
Optimizing query design is one of the simplest cost-saving strategies. Poorly written queries consume more resources, increase latency, and raise billing. Indexing, caching, and minimizing unnecessary scans all improve both performance and financial efficiency.
Data lifecycle management is another important factor. Not all data needs to remain in high-performance storage forever. Older records can often be moved to lower-cost archive systems while keeping recent operational data in faster storage. This reduces long-term expenses without losing business value.
Auto-scaling settings should also be reviewed carefully. Unlimited scaling may protect performance, but it can also create surprise costs during traffic spikes if limits are not properly managed. Smart thresholds help balance reliability and budget control.
Cost optimization is not about choosing the cheapest database. It is about selecting the right system and managing it intelligently so performance and financial sustainability remain aligned over time.
Monitoring and Observability for Database Performance
As serverless systems grow, monitoring database performance becomes increasingly important. Without clear visibility, small performance issues can turn into major outages before teams realize there is a problem.
Observability means understanding not only when something fails but also why it fails. This includes tracking query speed, error rates, connection usage, replication health, and storage growth. In serverless environments, where workloads change rapidly, real-time monitoring becomes even more valuable.
Performance bottlenecks are often hidden inside database interactions rather than application code. A slow checkout process, delayed notifications, or failed API requests may all trace back to overloaded queries or inefficient indexing.
Alert systems help teams respond quickly before customers are affected. Instead of waiting for user complaints, automated monitoring can detect unusual latency spikes, connection failures, or abnormal cost increases immediately.
Distributed tracing is especially useful in event-driven systems. Since one user action may trigger multiple serverless functions across several services, tracing helps identify exactly where performance breakdowns occur. This prevents guesswork and speeds up incident resolution.
Capacity forecasting is another important benefit of observability. Even with automatic scaling, teams still need to understand long-term usage patterns for budgeting, compliance planning, and architecture improvements.
Strong monitoring transforms database management from reactive problem-solving into proactive performance optimization. In modern serverless environments, visibility is not optional. It is a core part of maintaining stability and customer trust.
Why Future Growth Should Shape Database Decisions
Many businesses choose databases based only on current needs, but long-term growth should always be part of the decision. A system that works perfectly for a small application may become a major limitation once traffic, users, and business complexity increase.
Serverless architecture is often chosen because organizations expect growth and want infrastructure that can scale without major redesigns. The database should support that same vision. Choosing a system that cannot grow easily creates expensive migrations later.
Growth affects more than traffic volume. New features may require new data models, global expansion may require multi-region support, and regulatory changes may introduce stricter compliance requirements. The right database should be flexible enough to support these changes without forcing a complete rebuild.
Vendor lock-in is another important consideration. Some highly specialized serverless databases offer excellent short-term efficiency but create difficulty when businesses want to move across platforms later. Understanding portability and long-term architectural freedom helps avoid future operational constraints.
Team expertise also matters. A technically powerful database is not useful if the team cannot manage it effectively. Growth should include operational sustainability, training, and realistic maintenance expectations.
Planning for the future does not mean overbuilding on day one. It means selecting technology that supports both present needs and future opportunities. The best database decision is one that remains strong not only during launch but throughout the entire business journey.
A successful serverless architecture depends on thinking beyond immediate performance and building a foundation that supports long-term reliability, adaptability, and business success.
How Data Modeling Changes in Serverless Architecture
Data modeling in serverless architecture often looks very different from traditional application design. In conventional systems, developers usually begin by creating normalized database structures with multiple related tables to reduce duplication and maintain strict organization. While this approach remains valuable in many business applications, serverless systems often require a more flexible mindset focused on speed and scalability.
Because serverless applications are highly event-driven and distributed, reducing the number of database queries becomes a major priority. Every additional query increases latency, cost, and execution time. This is why denormalized data models are often preferred, especially in NoSQL environments. Instead of splitting data across many related tables, important information is stored together so it can be retrieved quickly in a single request.
For example, an ecommerce application may store customer details, recent purchases, and shipping preferences in a structure designed for fast access rather than perfect normalization. This improves performance during checkout and reduces the number of serverless function calls needed to complete a task.
Data modeling must also reflect access patterns rather than only business relationships. Instead of asking how data should be organized logically, teams must ask how data will actually be used most often. This practical approach improves efficiency and reduces unnecessary database pressure.
At the same time, poor denormalization can create maintenance challenges if updates become difficult to manage. The goal is balance, not extreme simplification. Good serverless data modeling supports both fast execution and long-term maintainability.
Choosing the right structure from the beginning prevents major redesigns later and helps the entire application remain stable as traffic and business requirements grow.
Handling Transactions Across Distributed Services
Transactions become more complex in serverless architecture because applications are often divided into multiple independent functions and services. In traditional monolithic systems, a single database transaction can handle multiple related actions together. In distributed systems, maintaining that same reliability requires more careful planning.
For example, when a customer places an order, the system may need to process payment, update inventory, send confirmation messages, and trigger shipping workflows. In a monolithic application, this might happen inside one controlled transaction. In a serverless environment, these tasks may happen across multiple services running independently.
This creates the challenge of distributed transactions. If one step succeeds and another fails, the system must still remain consistent. A payment cannot be completed without inventory updates, and an order should not be shipped without successful payment confirmation.
Instead of relying only on traditional transaction locks, many serverless systems use event-driven compensation strategies. If one step fails, another action is triggered to reverse the previous successful step. For example, if shipping fails after payment succeeds, the system may automatically issue a refund.
This approach requires strong workflow design and careful monitoring, but it scales better than forcing strict database locks across multiple services. It also fits naturally with event-driven architecture where systems respond to business events rather than centralized commands.
Relational databases remain useful for core transaction control, but the larger architecture must support distributed consistency across the full workflow. Reliability in serverless systems depends as much on process design as on the database itself.
Read and Write Patterns That Shape Database Performance
Understanding how an application reads and writes data is one of the most important parts of choosing the right database. Two applications with the same number of users may require completely different database strategies depending on how they handle information.
Some systems are read-heavy, meaning users request information far more often than they update it. News websites, content platforms, product catalogs, and educational systems often fall into this category. These applications benefit from caching, content delivery optimization, and databases designed for fast retrieval.
Other systems are write-heavy, where continuous updates happen all the time. Payment processing systems, IoT platforms, live tracking applications, and messaging services generate constant write operations. These workloads require databases that can handle high write throughput without slowing down.
Serverless architecture often supports both patterns at the same time. For example, a ride-sharing platform may process constant location updates while also serving users searching for available drivers nearby. The database must support rapid writes and fast reads simultaneously.
NoSQL databases often perform well in write-heavy environments because they scale horizontally and support high concurrency. Relational databases are stronger when write operations require strict consistency and transactional control.
Read and write patterns also affect pricing. Frequent writes may increase operational costs significantly in usage-based systems, while inefficient read patterns can create unnecessary database load. Optimizing both improves performance and financial efficiency together.
A database should never be selected based only on popularity. It should be chosen based on how the application actually behaves under real user activity.
Cold Starts and Their Impact on Database Interaction
Cold starts are one of the most discussed performance challenges in serverless architecture. They happen when a function has been inactive and must initialize again before handling a new request. This startup delay becomes more noticeable when database connections are involved.
If a serverless function needs to establish a fresh connection to the database every time it starts, response times can increase significantly. Users may experience delays even if the actual business logic is simple and fast.
This problem becomes especially serious in applications requiring real-time responses such as payment gateways, authentication systems, customer support tools, and interactive dashboards. Even small delays can affect user trust and satisfaction.
Connection pooling, lightweight drivers, and optimized initialization strategies help reduce cold start impact. Some managed platforms provide built-in solutions specifically designed for serverless workloads. These services reduce connection setup time and improve consistency during traffic spikes.
Keeping frequently used data in memory or using caching layers also reduces the number of direct database interactions needed during function execution. This minimizes cold start delays and improves overall system speed.
Developers should also avoid unnecessary dependencies inside functions because larger packages increase initialization time. Efficient function design supports faster execution and better database performance together.
Cold starts are not only an application problem. They are closely connected to database architecture. Reducing startup delays creates smoother user experiences and improves the practical value of serverless systems.
Multi-Region Database Design for Global Applications
As businesses grow internationally, database architecture must support users across multiple geographic regions. A serverless application serving customers worldwide cannot depend on a single database location without creating latency, availability, and reliability problems.
If users in one country must send every request to a database hosted on another continent, performance slows down noticeably. This affects customer satisfaction and may reduce conversion rates in high-speed environments such as ecommerce, streaming, and financial services.
Multi-region database design solves this by placing data closer to users. Replication allows multiple regions to serve requests while maintaining synchronization across the system. This reduces latency and improves fault tolerance if one region experiences downtime.
However, global distribution creates consistency challenges. Updates made in one region must remain accurate everywhere else. Some applications can accept eventual consistency, while others require immediate synchronization. The right model depends on business priorities.
For example, product browsing may tolerate small delays in updates, but payment confirmation cannot. This often leads to hybrid strategies where critical transactions remain strongly consistent while less sensitive features prioritize speed and availability.
Compliance requirements also influence regional design. Some countries require customer data to remain within specific geographic boundaries. Database selection must support these legal responsibilities while maintaining strong operational performance.
Global applications require databases that think beyond local performance. Multi-region planning creates resilience, improves customer experience, and supports long-term international growth without forcing major architectural rebuilds later.
The Importance of Schema Evolution
Even in well-planned systems, database structures must change over time. New features, business requirements, and customer expectations constantly create pressure for updates. In serverless architecture, schema evolution must happen carefully because changes affect multiple independent services at once.
In traditional monolithic systems, updating a database schema may be simpler because fewer services depend on the same structure. In distributed serverless systems, one schema change can impact APIs, event processors, analytics tools, and reporting systems simultaneously.
NoSQL databases offer more flexibility because they allow schema evolution without strict table redesign. New fields can often be added gradually without interrupting existing operations. This supports faster product development and easier experimentation.
Relational databases require more structured migration planning, but they provide stronger consistency and clearer governance. Schema changes must be tested carefully to avoid breaking dependent services. Managed migration tools help reduce operational risk during these updates.
Backward compatibility becomes extremely important. New application versions must often work alongside older services temporarily during deployment. A poorly planned schema change can create outages even when the database itself remains healthy.
Documentation also matters. Rapid serverless development without clear schema ownership creates confusion over time. Teams must understand which services depend on specific fields and how changes affect the larger system.
Schema evolution is not a sign of poor planning. It is a normal part of healthy software growth. The goal is not avoiding change but managing it safely so the system remains stable while the business continues to evolve.
Avoiding Overengineering in Database Selection
One of the most common mistakes in serverless architecture is choosing a database that is far more complex than the business actually needs. Teams sometimes select advanced distributed systems because they expect future growth, but unnecessary complexity often creates more problems than it solves.
A small application with predictable traffic may not need a globally distributed NoSQL platform with advanced event streaming and multi-region failover from day one. Simpler managed relational databases may provide better reliability, easier maintenance, and lower costs during the early stages.
Overengineering increases operational burden, training requirements, debugging difficulty, and migration risk. Developers spend more time managing architecture and less time improving actual product value.
This does not mean future growth should be ignored. It means growth planning should be realistic rather than based on theoretical scale that may never happen. Technology should support business strategy, not replace it.
The best architecture is often the simplest one that solves the real problem effectively. Complexity should be added only when clear business needs justify it.
Regular reviews help prevent overengineering. As traffic increases and requirements change, the database strategy can evolve gradually instead of forcing premature decisions based on assumptions.
Serverless architecture is meant to reduce unnecessary infrastructure management. Choosing an overly complicated database works against that goal. Strong design comes from clarity, not from using the most advanced technology available.
The right database is the one that fits current needs, supports realistic future growth, and allows teams to operate confidently without unnecessary technical weight.
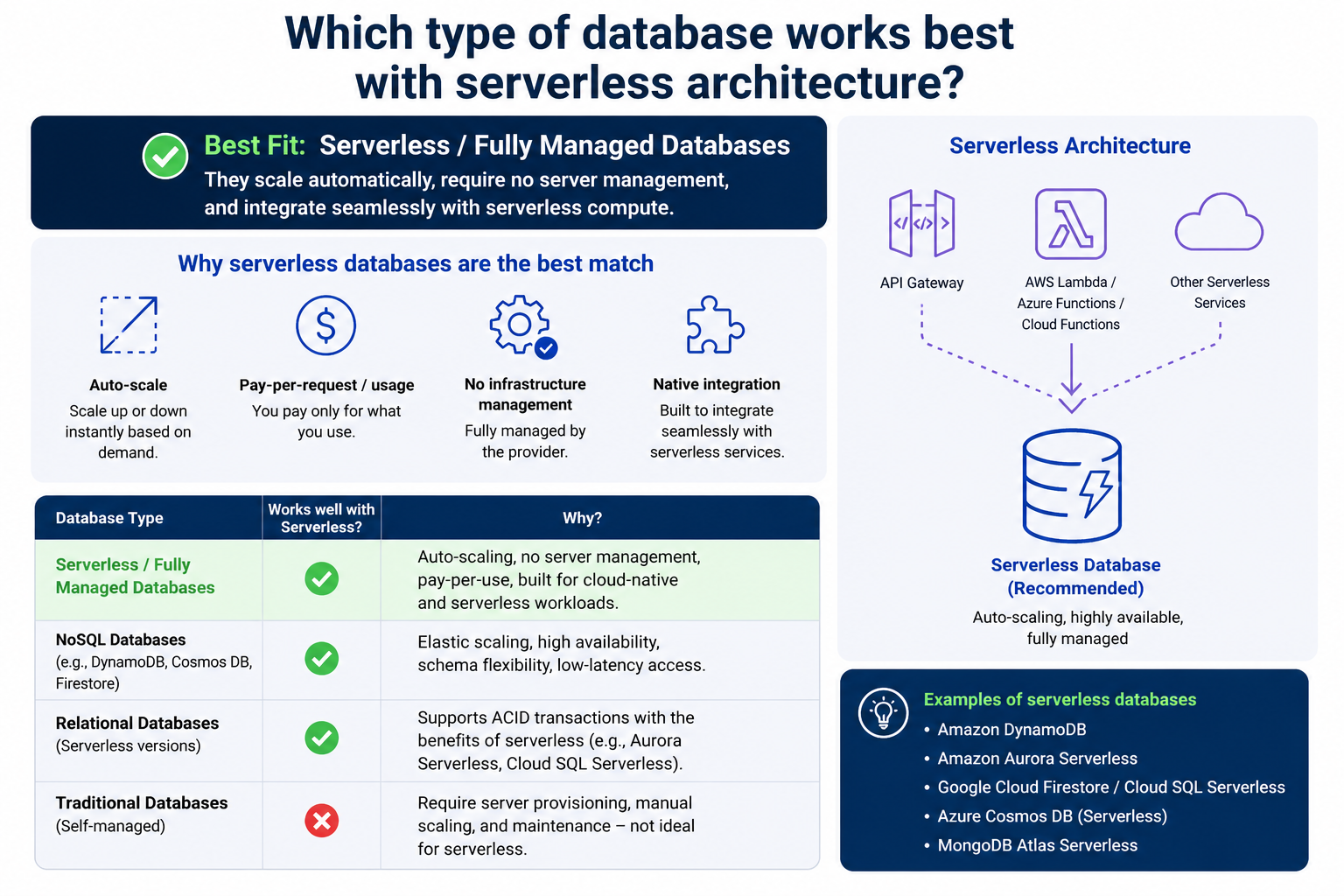
Conclusion
Selecting the right database for serverless architecture is ultimately about aligning technology with real application needs rather than following a single universal solution. Serverless systems are built for flexibility, automatic scaling, and reduced infrastructure management, so the database must support the same principles to ensure consistent performance and efficiency.
NoSQL databases are often preferred for their scalability, speed, and ability to handle unstructured or rapidly changing data. They work especially well in event-driven systems where workloads are unpredictable and high performance is required. Managed relational databases, however, remain essential for applications that depend on structured data, strong consistency, and reliable transaction handling. Serverless-native databases further simplify operations by offering automatic scaling and usage-based pricing, making them highly effective for modern cloud-first applications.
In many real-world scenarios, the most effective approach is not choosing one database type but combining multiple systems to handle different responsibilities. This hybrid strategy allows each database to operate in its strongest area, whether that is speed, structure, analytics, or caching. Supporting tools like in-memory databases, caching layers, and event-driven processing systems further enhance performance and reduce load on primary databases.
Beyond technology selection, factors such as latency, connection management, cost optimization, security, scalability, and monitoring all play a critical role in determining overall system success. A well-designed database strategy ensures that serverless applications remain fast, reliable, and cost-efficient even under changing workloads and growing user demands.
In the end, the best database for serverless architecture is not defined by popularity or complexity but by how well it supports the application’s behavior, growth expectations, and long-term business goals.