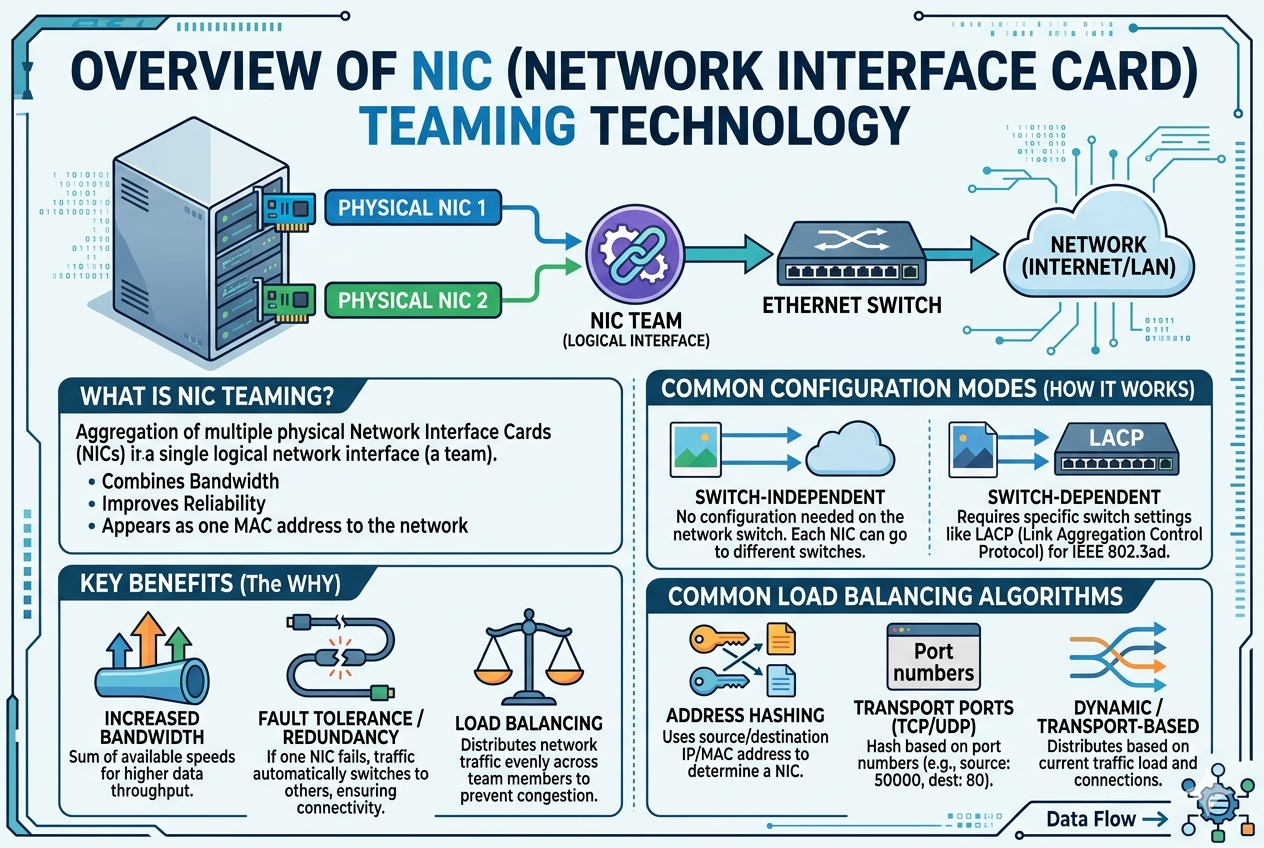
NIC teaming architecture is built on the concept of abstracting multiple physical network adapters into a single logical interface that the operating system and applications can use seamlessly. At the core of this design is a software or firmware-based teaming driver that sits between the network hardware and the network stack of the operating system. This driver is responsible for managing traffic distribution, monitoring link status, and ensuring continuity in case of failure. By consolidating multiple physical interfaces, the system gains flexibility in how network traffic is handled while maintaining a unified communication channel for upper-layer processes.
In a typical setup, each physical NIC remains independently connected to the network infrastructure, often through separate switches or switch stacks to enhance redundancy. The teaming software then binds these interfaces together and presents them as a single virtual network adapter. This abstraction ensures that applications and services do not need to be aware of the underlying complexity, allowing them to function normally even if individual physical links change status.
Load Balancing Mechanisms in NIC Teaming
Load balancing is one of the most critical components of NIC teaming, as it directly affects network performance and efficiency. The purpose of load balancing is to distribute outgoing and incoming network traffic across multiple physical adapters in a way that optimizes bandwidth usage and prevents any single link from becoming a bottleneck.
Different algorithms are used to achieve load balancing depending on the configuration and operating system capabilities. Some methods distribute traffic based on source and destination IP addresses, while others rely on MAC address hashing or session-based distribution. Session-based balancing is often preferred in environments where maintaining connection consistency is important, such as database communication or virtual machine networking.
The effectiveness of load balancing depends heavily on traffic patterns. In scenarios with multiple simultaneous connections, NIC teaming can significantly improve throughput by utilizing all available adapters. However, in single-stream communications, the improvement may be limited because a single session is typically bound to one physical link.
Failover and Redundancy Capabilities
One of the primary reasons for implementing NIC teaming is to ensure network redundancy. Failover capability allows the system to automatically redirect traffic to functioning adapters if one or more network interfaces fail. This process is seamless and typically does not require manual intervention, making it highly valuable in environments where uptime is critical.
When a failure occurs, the teaming driver continuously monitors link status using periodic health checks. If a failure is detected, the faulty adapter is removed from the active pool, and traffic is redistributed among the remaining active interfaces. Once the failed adapter is restored, it can be automatically reintegrated into the team, restoring full redundancy and performance capacity.
This redundancy mechanism is especially important in enterprise data centers, where even short periods of network downtime can lead to significant operational disruptions and financial loss.
Link Aggregation Control Protocol Integration
NIC teaming often works in conjunction with Link Aggregation Control Protocol, which is a standardized method for bundling multiple physical network links into a single logical link at the switch level. LACP enables dynamic negotiation between network devices to form and maintain aggregated links, ensuring that both ends of the connection are properly synchronized.
When LACP is enabled, switches and network adapters exchange control packets to verify compatibility and maintain the aggregated link. This allows for more efficient and standardized teaming compared to static configurations, where links are manually grouped without dynamic negotiation.
The integration of LACP enhances both scalability and reliability, especially in large network infrastructures where manual configuration would be inefficient and error-prone.
Operating System Support and Implementation Models
Different operating systems implement NIC teaming in distinct ways, though the underlying principles remain similar. In many server operating systems, teaming is handled either through built-in drivers or vendor-specific utilities provided by hardware manufacturers.
There are generally two primary implementation models. The first is software-based teaming, where the operating system manages all aspects of load balancing and failover. The second is hardware-assisted teaming, where network interface controllers or switches assist in handling certain aspects of traffic distribution.
Software-based implementations are more flexible and widely compatible, while hardware-assisted models often provide better performance and lower CPU overhead. The choice between these models depends on the performance requirements and infrastructure design of the environment.
NIC Teaming in Virtualized Environments
Virtualization environments rely heavily on NIC teaming to ensure efficient communication between virtual machines and physical networks. Hypervisors use teamed network interfaces to provide multiple virtual switches with redundant and high-bandwidth connectivity.
In such environments, each virtual machine communicates through virtual network adapters that are mapped to the underlying physical NIC team. This allows virtual machines to benefit from load balancing and failover without being aware of the physical network structure.
This abstraction is essential in cloud computing and virtual data centers, where workloads frequently move between physical hosts. NIC teaming ensures that network connectivity remains consistent and reliable during these transitions.
Performance Optimization Considerations
Proper configuration of NIC teaming is essential for achieving optimal performance. Factors such as traffic type, network topology, and switch configuration all play a significant role in determining effectiveness. For example, environments with high volumes of small, concurrent connections benefit more from advanced load balancing algorithms compared to environments dominated by large, single-stream transfers.
Another important consideration is switch compatibility. Not all switches handle aggregated links in the same way, and mismatched configurations can lead to inefficiencies or even network instability. Ensuring consistent configuration across all network components is critical for stable performance.
CPU overhead is another factor that must be considered. While modern systems handle NIC teaming efficiently, poorly optimized configurations can introduce unnecessary processing load on the host system.
Security Implications of NIC Teaming
Although NIC teaming is primarily designed for performance and reliability, it also has indirect implications for network security. By providing multiple active pathways for data transmission, it reduces the risk of complete network isolation due to a single point of failure. However, misconfigurations can potentially expose inconsistencies in traffic routing, which may be exploited if network segmentation is not properly enforced.
In secure environments, NIC teaming should be implemented alongside strict network policies, including VLAN segmentation and access control mechanisms. This ensures that while redundancy and performance are enhanced, security boundaries remain intact.
Common Challenges and Limitations
Despite its advantages, NIC teaming is not without limitations. One of the main challenges is complexity in configuration and troubleshooting. Incorrect setup can lead to suboptimal performance or even network connectivity issues.
Another limitation is that not all traffic types benefit equally from teaming. Single-threaded applications may not experience noticeable performance improvements because their traffic is typically bound to a single physical link. Additionally, compatibility issues between different hardware vendors can sometimes lead to inconsistent behavior.
Debugging network issues in a teamed environment can also be more complex compared to single NIC configurations, as administrators must consider multiple physical and logical layers.
Best Practices for Implementation
Successful NIC teaming deployment requires careful planning and adherence to best practices. One important practice is ensuring that all network adapters used in a team are of similar performance capabilities to avoid bottlenecks. Mixing significantly different hardware can lead to uneven load distribution.
It is also recommended to use separate physical switches for redundant paths whenever possible. This reduces the risk of a single switch failure affecting all network links in the team.
Monitoring and logging should be enabled to track performance metrics and detect anomalies early. Regular testing of failover scenarios is also essential to ensure that redundancy mechanisms function as expected under real-world conditions.
Future Trends in NIC Teaming Technology
As network infrastructure continues to evolve, NIC teaming is also advancing to support higher speeds and more intelligent traffic management. Emerging technologies are integrating artificial intelligence-based load balancing, which dynamically adjusts traffic distribution based on real-time network conditions.
With the rise of high-speed networking such as 100GbE and beyond, traditional load balancing methods are being enhanced to handle significantly larger data flows. Additionally, integration with software-defined networking is making NIC teaming more flexible and programmable.
These advancements are expected to further improve both performance and resilience, making NIC teaming an even more critical component of modern network architecture.
Advanced Load Distribution Techniques in NIC Teaming
Modern NIC teaming implementations go beyond basic hashing or round-robin methods and incorporate more advanced load distribution techniques that adapt dynamically to network conditions. These intelligent methods evaluate real-time traffic patterns, link utilization, and even application behavior to make more efficient decisions about how data is distributed across available network adapters.
One commonly used advanced approach is adaptive load balancing, where the system continuously monitors bandwidth usage and shifts traffic away from congested links. This helps maintain consistent performance even during sudden spikes in network demand. Another approach is flow-aware distribution, which groups related packets from the same session or application flow and ensures they follow the same physical path to avoid packet reordering issues that could degrade performance.
In high-performance environments such as financial systems or large-scale virtualization platforms, these advanced techniques play a crucial role in maintaining both speed and stability under heavy workloads.
Role of Switch Configuration in NIC Teaming
Switch configuration is a fundamental aspect of NIC teaming that directly influences its effectiveness. Even if the host system is properly configured, improper switch setup can limit performance or introduce connectivity problems. In many cases, switches must be configured to recognize and support aggregated links using protocols such as LACP or static link aggregation settings.
When multiple NICs are connected to a switch, the switch must treat them as part of a single logical connection to ensure proper traffic distribution. If switches are misconfigured or if different switches are used without proper stacking or interconnection, issues such as asymmetric routing or packet loss can occur.
In enterprise environments, switch redundancy is often paired with NIC teaming to create a fully resilient network path. This ensures that both the server-side and network-side infrastructure can withstand failures without affecting service availability.
Impact of NIC Teaming on Virtual Machines and Containers
In virtualized and containerized environments, NIC teaming provides a critical foundation for network reliability and scalability. Virtual machines rely on virtual network interfaces that are mapped to physical NIC teams, allowing them to benefit from underlying redundancy and bandwidth aggregation without direct awareness of the physical network structure.
This abstraction is especially important in environments where virtual machines are frequently migrated between hosts. During live migration, network continuity must be maintained without interruption, and NIC teaming helps ensure that active connections remain stable throughout the process.
Containers also benefit from NIC teaming when deployed in clustered environments. By leveraging the underlying network redundancy, container orchestration platforms can maintain high availability for microservices even when individual network components experience failures or congestion.
Bandwidth Aggregation and Real-World Performance
One of the most frequently misunderstood aspects of NIC teaming is bandwidth aggregation. While combining multiple NICs does increase total available bandwidth, this does not always translate into a simple multiplication of speed for a single connection.
Instead, total bandwidth is distributed across multiple sessions or flows. For example, if a system has two 10 Gbps network interfaces, it can theoretically support 20 Gbps of total throughput, but a single data stream may still be limited to 10 Gbps depending on the load balancing method used.
Real-world performance improvements are most noticeable in environments with multiple concurrent connections, such as web servers, database clusters, and file storage systems. In these scenarios, NIC teaming significantly improves responsiveness and throughput by distributing traffic efficiently across all available links.
Fault Detection and Recovery Mechanisms
NIC teaming systems continuously monitor the health of each network interface using a combination of link-state detection and heartbeat mechanisms. These monitoring processes ensure that failures are detected quickly and accurately.
When a fault is detected, the teaming driver immediately removes the affected NIC from the active pool and redirects traffic to the remaining operational interfaces. This transition is designed to be seamless, with minimal or no packet loss in most cases.
Recovery is equally important, as failed interfaces must be reintegrated into the team once they are restored. The system performs validation checks before reintroducing the recovered NIC to ensure that it is stable and fully functional. This dynamic recovery process helps maintain long-term reliability without requiring manual intervention.
Hardware vs Software NIC Teaming Approaches
NIC teaming can be implemented using either hardware-based or software-based approaches, each with distinct advantages and trade-offs. Hardware-based teaming relies on network interface controllers or switch-level intelligence to manage traffic distribution. This approach often delivers lower latency and reduced CPU overhead, making it suitable for high-performance computing environments.
Software-based teaming, on the other hand, is managed entirely by the operating system. It provides greater flexibility and compatibility across different hardware platforms. This method is widely used in general-purpose servers and virtualized environments where adaptability is more important than specialized hardware optimization.
In many modern systems, a hybrid approach is used, combining elements of both hardware and software-based techniques to achieve an optimal balance between performance and flexibility.
Scalability Considerations in Large Networks
As network environments grow in size and complexity, scalability becomes a key consideration in NIC teaming design. Large data centers may deploy hundreds or even thousands of servers, each with multiple network interfaces contributing to a highly interconnected infrastructure.
In such environments, consistent configuration standards are essential to ensure predictable behavior. Even small inconsistencies in teaming policies or switch settings can lead to performance degradation or network instability at scale.
Automation tools are often used to manage NIC teaming configurations across large infrastructures. These tools help ensure consistency, reduce manual errors, and simplify ongoing maintenance as the network evolves.
Troubleshooting NIC Teaming Issues
Troubleshooting NIC teaming problems can be more complex than diagnosing issues in single-NIC setups due to the additional abstraction layer. Common issues include misconfigured load balancing policies, incompatible switch settings, or faulty physical connections.
Performance issues often arise when traffic distribution is uneven, leading to one NIC being heavily utilized while others remain underused. This can usually be resolved by adjusting the load balancing algorithm or verifying switch configuration.
Connectivity issues may occur if failover mechanisms are not properly configured or if heartbeat monitoring fails to detect link status accurately. In such cases, reviewing driver logs and network diagnostics is essential for identifying the root cause.
Energy Efficiency and Resource Optimization
NIC teaming can also contribute to improved energy efficiency in certain scenarios. By intelligently distributing traffic across multiple interfaces, systems can avoid overloading individual components and reduce the need for peak hardware utilization.
Some advanced configurations allow unused NICs to enter low-power states during periods of low network activity. This helps reduce overall power consumption in large-scale deployments, particularly in data centers where energy efficiency is a major operational concern.
At the same time, efficient resource utilization ensures that network infrastructure is used optimally, reducing the need for additional hardware expansion.
Integration with Modern Networking Technologies
NIC teaming continues to evolve alongside modern networking technologies such as software-defined networking and cloud-native architectures. In these environments, network behavior is increasingly controlled through centralized software controllers rather than static hardware configurations.
This integration allows NIC teaming to become more dynamic and programmable, enabling real-time adjustments based on workload demands. It also enhances compatibility with automated orchestration systems that manage large-scale distributed environments.
As networking continues to shift toward more flexible and software-driven models, NIC teaming remains a foundational technology that supports both legacy systems and next-generation infrastructures.
Security Enhancements Enabled Through NIC Teaming
NIC teaming indirectly strengthens network resilience, which plays an important role in overall infrastructure security. By maintaining multiple active network paths, systems become less vulnerable to single points of failure that could otherwise be exploited to disrupt services. In high-availability environments, this redundancy ensures that even if one network interface is compromised or disconnected, communication can continue through alternate paths without interruption.
Beyond redundancy, NIC teaming can support segmented traffic flows when combined with VLAN configurations and access control policies. This allows administrators to isolate different types of traffic, such as management, storage, and application data, across separate logical paths while still benefiting from shared physical infrastructure. When properly configured, this reduces the attack surface and limits lateral movement within a network.
However, security effectiveness depends heavily on correct implementation. Misconfigured teaming setups may unintentionally merge traffic streams that should remain separated, which can introduce risks in sensitive environments. For this reason, NIC teaming is often deployed alongside strict network segmentation and monitoring practices.
Quality of Service and Traffic Prioritization
In advanced networking environments, NIC teaming can work alongside Quality of Service mechanisms to prioritize certain types of traffic over others. This is particularly important in systems where latency-sensitive applications such as voice communication, financial transactions, or real-time analytics operate alongside bulk data transfers.
Traffic prioritization ensures that critical packets are transmitted with minimal delay even when the network is under heavy load. Within a teamed interface, QoS policies can influence how traffic is distributed across physical adapters, allowing high-priority flows to take advantage of less congested links.
This combination of teaming and prioritization helps maintain predictable performance levels across diverse workloads, improving user experience and system responsiveness.
NIC Teaming in High-Performance Computing Environments
High-performance computing environments place extreme demands on network infrastructure due to the volume and speed of data exchange between nodes. NIC teaming is widely used in these environments to maximize throughput and ensure consistent connectivity between compute clusters.
In such systems, parallel processing tasks often require frequent synchronization between nodes. NIC teaming helps reduce communication delays by distributing traffic efficiently across multiple high-speed interfaces. This reduces bottlenecks and allows compute resources to operate at maximum efficiency.
In addition, failover capabilities are especially critical in high-performance clusters, where even brief network interruptions can disrupt long-running computations or cause task failures.
Interaction with Storage Networks
Storage networks benefit significantly from NIC teaming, particularly in environments that rely on network-attached storage or storage area networks. These systems require consistent and high-speed data transfer between servers and storage devices.
By aggregating multiple NICs, storage traffic can be distributed more effectively, reducing congestion and improving read/write performance. This is especially important for applications that handle large datasets, such as databases, virtualization platforms, and media processing systems.
In storage-heavy environments, NIC teaming also helps ensure that data availability is maintained even during network component failures, reducing the risk of data access interruptions.
Virtual Switching and Software-Defined Networking Integration
Modern infrastructure increasingly relies on virtual switching technologies that operate within hypervisors or cloud platforms. NIC teaming integrates closely with these virtual switches to provide redundant and high-performance network connectivity for virtual workloads.
In software-defined networking environments, network behavior is controlled through centralized controllers that dynamically manage traffic flow. NIC teaming fits into this model by providing the underlying physical redundancy and bandwidth aggregation required for virtual networks to function efficiently.
This integration allows network administrators to define policies that span both physical and virtual layers, creating a more flexible and responsive networking environment.
Latency Considerations in Teaming Configurations
While NIC teaming improves overall throughput and reliability, it can introduce subtle variations in latency depending on configuration. Different load balancing methods may result in packets taking different physical paths, which can affect timing consistency in sensitive applications.
For applications that require strict latency control, such as real-time trading systems or industrial automation, careful selection of teaming policies is essential. Flow-based distribution methods are often preferred in these cases because they maintain consistency by keeping related packets on the same physical link.
Network designers must balance the benefits of redundancy and throughput with the need for predictable latency behavior.
Monitoring and Performance Analysis
Continuous monitoring is essential in environments where NIC teaming is deployed at scale. Network administrators typically track metrics such as link utilization, packet loss, error rates, and failover events to ensure that the system is performing as expected.
Performance analysis tools can help identify imbalances in traffic distribution, which may indicate misconfiguration or inefficient load balancing policies. These insights allow administrators to fine-tune settings to achieve optimal performance.
Historical data is also valuable for capacity planning, as it helps predict future bandwidth requirements and identify when infrastructure upgrades may be necessary.
Driver-Level and Firmware-Level Optimization
NIC teaming performance is heavily influenced by the quality of drivers and firmware used by network adapters. Modern NIC drivers often include advanced features that optimize packet handling, reduce CPU overhead, and improve compatibility with teaming configurations.
Firmware updates can also introduce improvements in link detection, error correction, and power management, all of which contribute to more stable and efficient teaming behavior. Keeping both drivers and firmware up to date is therefore an important maintenance practice in enterprise environments.
In some cases, vendor-specific enhancements provide additional performance benefits beyond standard implementations, particularly in high-end networking hardware.
Fault Isolation and Diagnostic Techniques
Diagnosing issues in NIC teaming setups requires a structured approach due to the multiple layers involved. Problems may originate at the physical layer, driver layer, operating system layer, or switch configuration level.
Fault isolation typically begins with verifying physical connectivity and link status for each adapter. From there, administrators examine teaming configuration settings to ensure that load balancing and failover policies are correctly defined.
Advanced diagnostic tools can simulate traffic patterns to test how the system behaves under different conditions. This helps identify hidden issues such as uneven load distribution or intermittent link instability.
Role in Cloud Infrastructure
Cloud computing environments rely heavily on NIC teaming to support large-scale, distributed workloads. In these environments, network reliability and scalability are critical due to the dynamic nature of virtual resource allocation.
NIC teaming ensures that virtual machines and containerized services maintain consistent connectivity even as they are moved across physical hosts. It also supports high-bandwidth communication between cloud services, which is essential for distributed computing and microservices architectures.
As cloud environments continue to grow, NIC teaming remains a foundational technology that supports both performance and resilience at scale.
Future Evolution of NIC Teaming Systems
The future of NIC teaming is closely tied to advancements in intelligent networking and automation. Emerging systems are increasingly capable of making real-time decisions based on machine learning models that analyze traffic behavior and predict network congestion.
These intelligent systems aim to optimize load distribution dynamically without manual intervention, improving both performance and reliability. Integration with next-generation network fabrics is also expected to enhance scalability and reduce configuration complexity.
As network speeds continue to increase and infrastructure becomes more software-driven, NIC teaming will evolve into a more adaptive and self-optimizing technology that plays a central role in modern digital ecosystems.
Operational Best Practices for Stable NIC Teaming Deployment
Successful NIC teaming deployment depends heavily on following consistent operational practices that ensure stability, predictability, and long-term performance. One of the most important practices is maintaining uniformity across all network interfaces participating in the team. This includes using similar hardware capabilities, compatible drivers, and consistent firmware versions to prevent imbalance in traffic handling.
Another key practice is proper planning of network topology before implementation. Each physical NIC should ideally connect to separate switches or switch stacks configured for redundancy. This ensures that a single switch failure does not compromise the entire team. Without this design consideration, the redundancy benefits of NIC teaming can be significantly reduced.
Regular testing is also essential. Failover scenarios should be simulated periodically to confirm that traffic is seamlessly redirected in the event of a link failure. This helps identify misconfigurations early and ensures that the system behaves as expected under real-world conditions.
Advanced Troubleshooting and Optimization Strategies
In complex environments, troubleshooting NIC teaming issues often requires deeper analysis beyond basic connectivity checks. One common issue is uneven traffic distribution, where one adapter handles significantly more load than others. This is typically resolved by adjusting load balancing algorithms or reviewing session distribution behavior.
Another frequent challenge involves intermittent connectivity drops caused by mismatched switch settings or incorrect LACP configuration. In such cases, verifying consistency between server-side teaming policies and switch-side aggregation settings is critical.
Performance tuning may also involve analyzing packet flow behavior at a granular level. Administrators often use monitoring tools to inspect how traffic is being distributed across interfaces and identify bottlenecks or inefficiencies. Fine-tuning these parameters can lead to substantial improvements in throughput and stability.
Scalability in Modern Data Center Architectures
As data centers continue to expand, scalability becomes one of the defining advantages of NIC teaming. Large-scale infrastructures often consist of thousands of interconnected servers, each relying on aggregated network interfaces to handle massive traffic loads.
NIC teaming allows these environments to scale horizontally without requiring proportional increases in individual link capacity. Instead, additional NICs can be added to teams as demand grows, providing a flexible and cost-effective scaling model.
In cloud-native environments, this scalability is further enhanced by automation systems that dynamically adjust network configurations based on workload demands. This reduces manual intervention and ensures consistent performance even during rapid scaling events.
Role in High Availability and Disaster Recovery Systems
High availability systems depend heavily on NIC teaming to maintain continuous service delivery. In mission-critical environments, even brief network interruptions can lead to significant operational disruptions. NIC teaming mitigates this risk by ensuring that multiple redundant network paths are always available.
In disaster recovery scenarios, NIC teaming works alongside broader infrastructure redundancy strategies to maintain connectivity during system failures or site outages. If a primary network path becomes unavailable, traffic is automatically rerouted through secondary interfaces, preserving service continuity.
This capability is especially important in industries such as finance, healthcare, and telecommunications, where downtime can have severe consequences.
Integration with Automation and Orchestration Tools
Modern IT environments increasingly rely on automation and orchestration platforms to manage complex infrastructure. NIC teaming integrates seamlessly into these systems, allowing network configurations to be deployed, monitored, and adjusted programmatically.
Automation tools can dynamically create or modify NIC teams based on predefined policies, reducing the need for manual configuration. This improves consistency and reduces the risk of human error, especially in large-scale deployments.
Orchestration platforms also enable real-time monitoring and automatic remediation. For example, if a network interface becomes unstable, automated systems can remove it from the team and trigger alerts or corrective actions without human intervention.
Energy Efficiency and Resource Management Considerations
While NIC teaming primarily focuses on performance and reliability, it also contributes to more efficient resource utilization. By distributing network load across multiple interfaces, systems can avoid overloading individual components, leading to more balanced hardware usage.
In some configurations, unused network interfaces can be placed into low-power states during periods of low demand. This helps reduce overall energy consumption, particularly in large-scale data centers where thousands of interfaces may be active simultaneously.
Efficient resource management not only improves sustainability but also extends the operational lifespan of networking hardware by reducing continuous peak load stress.
Emerging Trends in NIC Teaming Technology
NIC teaming continues to evolve alongside advancements in networking technology. One of the most significant trends is the shift toward intelligent, software-defined networking environments where traffic management is increasingly automated and adaptive.
Future systems are expected to incorporate predictive analytics that anticipate network congestion and proactively adjust load distribution before performance degradation occurs. This represents a shift from reactive to proactive network management.
Another emerging trend is tighter integration with cloud-native infrastructures, where NIC teaming becomes part of a broader ecosystem of dynamically managed network services. This enables more flexible and responsive network architectures capable of supporting highly distributed workloads.
Conclusion
NIC teaming remains a foundational technology in modern networking, providing a powerful combination of performance enhancement, redundancy, and scalability. By aggregating multiple physical network interfaces into a single logical connection, it enables systems to achieve higher bandwidth utilization while ensuring continuous availability even in the event of hardware failures.
Its role extends across a wide range of environments, from enterprise servers and virtualization platforms to cloud data centers and high-performance computing systems. Through advanced load balancing techniques, failover mechanisms, and integration with modern networking technologies, NIC teaming ensures that network infrastructure remains resilient and efficient under varying workloads.
Although it introduces additional complexity in configuration and management, the benefits of NIC teaming far outweigh its challenges when implemented correctly. With ongoing advancements in automation, intelligent traffic management, and software-defined networking, NIC teaming is expected to become even more adaptive and efficient in the future, continuing to serve as a critical component of reliable and high-performance network design.