Modern businesses depend heavily on technology to perform daily operations, communicate with customers, manage employees, process financial transactions, and store valuable information. From cloud-based software and databases to communication platforms and remote access tools, digital infrastructure supports almost every department inside an organization. Because of this dependence, even a small technical issue can quickly become a major business problem.
When systems suddenly become unavailable, employees may lose access to applications, customers may experience interruptions, and organizations can suffer financial losses. In some situations, downtime may even damage a company’s reputation permanently. Businesses that are not prepared for unexpected disruptions often struggle to recover quickly because they lack clear procedures, recovery systems, and communication strategies.
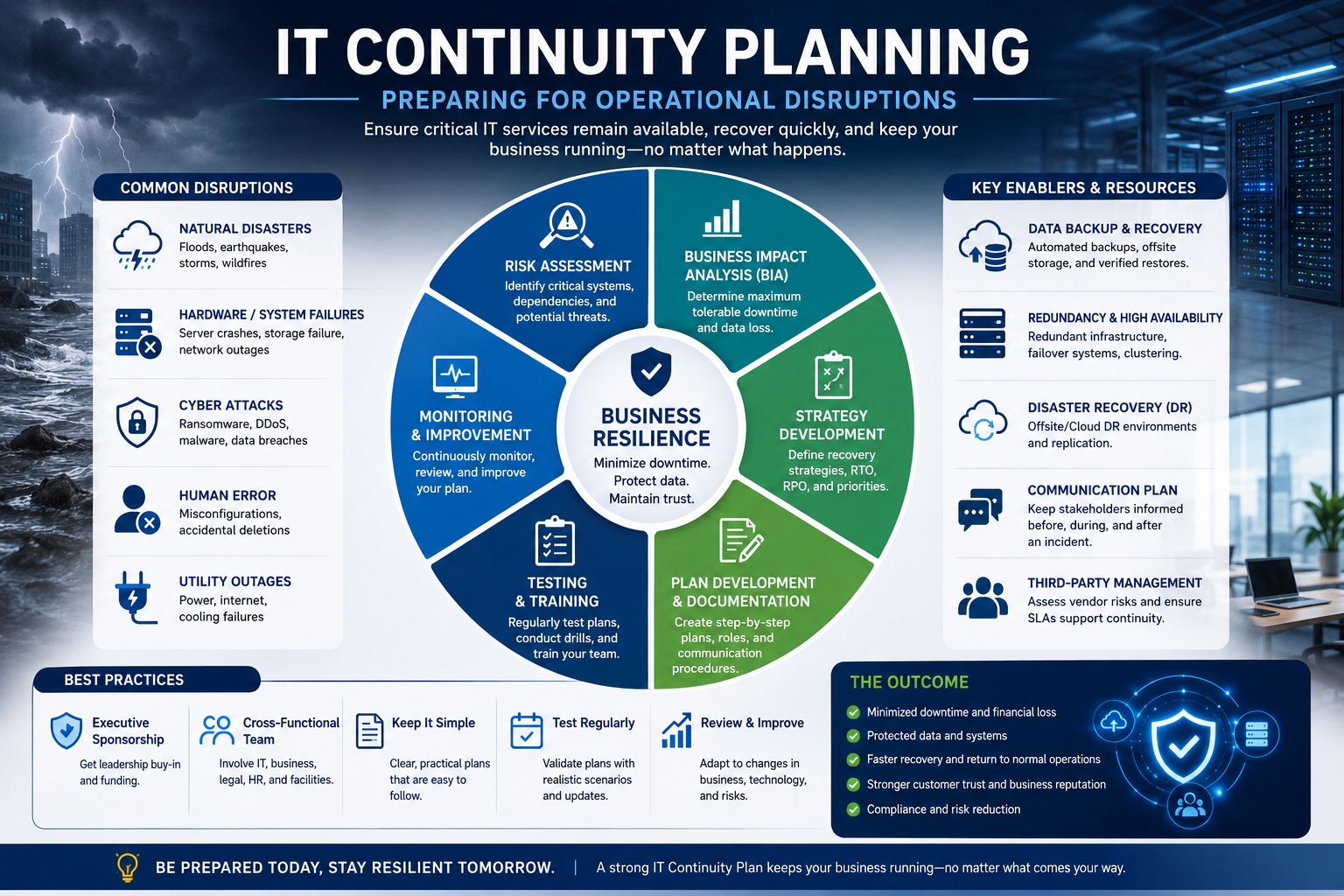
Business continuity planning helps organizations prepare for these situations before they happen. Instead of responding to emergencies with confusion and uncertainty, companies create structured plans that outline how systems, employees, and operations will continue functioning during disruptions. These plans help reduce downtime, protect data, and maintain operational stability during difficult situations.
Business continuity planning is more than a technical process. It is a long-term organizational strategy focused on resilience and preparedness. It ensures that businesses can continue delivering services, supporting customers, and maintaining critical operations even when major incidents occur. For IT departments, continuity planning is especially important because technology systems are at the center of modern business operations.
Why Business Continuity Planning Matters
Organizations today operate in highly connected digital environments. Systems interact with each other constantly, and many departments rely on shared infrastructure. A failure in one area can quickly affect multiple parts of the business. Because of this interconnected structure, even short disruptions can create widespread operational challenges.
For example, if a company’s authentication server fails, employees may lose access to email, cloud applications, internal portals, and communication platforms simultaneously. A ransomware attack may encrypt critical files and prevent teams from accessing customer information or financial records. A power outage could interrupt internet connectivity, disable on-premises systems, and stop production activities.
Business continuity planning exists to reduce the impact of these events. By preparing recovery procedures in advance, organizations can restore systems faster and minimize operational damage. Instead of making rushed decisions during emergencies, IT teams can follow predefined recovery processes that improve efficiency and reduce confusion.
One of the biggest reasons continuity planning matters is financial protection. Downtime costs businesses money in several ways. Employees may become unable to work, customers may abandon transactions, and operational delays may affect productivity across multiple departments. In industries where systems support revenue generation, even a few minutes of downtime can create major financial consequences.
Customer trust is another critical factor. Modern consumers expect services to remain available at all times. If applications, websites, or customer portals remain unavailable for long periods, users may begin questioning the reliability of the organization. Repeated outages can permanently damage a company’s reputation and push customers toward competitors.
Continuity planning also supports compliance and legal requirements. Many industries must follow strict regulations regarding data protection, service availability, and operational security. Businesses that fail to maintain continuity during emergencies may face penalties, lawsuits, or regulatory investigations.
For IT departments, business continuity planning helps create structure during stressful situations. Instead of reacting emotionally under pressure, teams can follow documented recovery procedures and communicate effectively with leadership, employees, and customers. This organized approach significantly improves recovery outcomes.
The Growing Dependence on Technology
Technology has transformed the way organizations operate. Businesses now depend on cloud platforms, remote collaboration tools, mobile applications, cybersecurity systems, and digital communication channels to maintain productivity and customer engagement.
In the past, some organizations could continue operating manually during technical failures. Today, that is often impossible. Employees rely on digital tools for nearly every aspect of their work. Customer service teams use online systems to manage requests, finance departments depend on accounting software, and sales teams use cloud platforms to track customer interactions.
Remote work has increased this dependence even further. Employees now access company systems from homes, coworking spaces, and mobile devices using internet-based services. This flexibility improves productivity, but it also introduces additional risks related to connectivity, cybersecurity, and infrastructure reliability.
Because businesses rely so heavily on technology, disruptions now have larger consequences than ever before. An outage may affect not only internal operations but also external customer experiences and partner relationships. Organizations must therefore prepare carefully for technical failures and unexpected incidents.
Cloud computing has also changed continuity planning significantly. Many organizations use cloud providers to host applications, store data, and support collaboration. While cloud platforms often improve resilience through redundancy and scalability, they are not immune to outages. Service interruptions at major providers can still affect thousands of businesses simultaneously.
This means organizations cannot rely entirely on external providers for continuity protection. IT departments must still create recovery procedures, backup strategies, and communication plans to ensure business operations remain stable during disruptions.
Common Threats to Business Operations
Business continuity planning addresses a wide range of risks that may interrupt operations. Some threats are technical, while others involve environmental factors, human mistakes, or cybersecurity incidents. Understanding these risks is one of the first steps in creating an effective continuity strategy.
Cybersecurity threats are among the most serious concerns facing organizations today. Ransomware attacks, phishing campaigns, malware infections, and data breaches can disrupt operations and compromise sensitive information. Cybercriminals often target businesses specifically because downtime creates pressure to restore systems quickly.
Ransomware attacks are particularly dangerous because they can encrypt critical systems and prevent organizations from accessing important files. Without proper backups and recovery procedures, businesses may struggle to restore operations.
Hardware failures are another common cause of downtime. Servers, storage systems, network devices, and power equipment can fail unexpectedly. Even high-quality hardware eventually experiences wear and performance degradation. Without redundancy and backup systems, a single hardware failure may affect multiple services.
Software issues can also create operational disruptions. Updates, configuration changes, compatibility problems, and application bugs may cause systems to become unstable or unavailable. Sometimes small changes create widespread problems across interconnected environments.
Natural disasters remain significant threats as well. Floods, earthquakes, fires, storms, and extreme weather conditions can damage infrastructure and interrupt operations for extended periods. Organizations located in disaster-prone areas must pay special attention to physical resilience and off-site recovery strategies.
Human error is another major factor in business disruptions. Employees may accidentally delete files, misconfigure systems, or introduce security vulnerabilities. Even experienced IT professionals can make mistakes during stressful situations or complex projects.
Third-party service providers also introduce risks. Many organizations depend on external vendors for cloud services, internet connectivity, software platforms, and managed security solutions. If a vendor experiences an outage, the business may also experience operational interruptions.
Business continuity planning helps organizations prepare for all these risks by identifying vulnerabilities and developing recovery procedures in advance.
The Role of IT Departments in Continuity Planning
IT departments play a central role in business continuity because they manage the systems that support modern business operations. Their responsibilities include protecting infrastructure, maintaining backups, monitoring system health, and coordinating recovery efforts during emergencies.
One of the most important responsibilities of IT teams is identifying critical systems. Not every application or service has the same level of importance. Some systems directly support revenue generation or customer service, while others are less essential.
For example, an online payment platform may require immediate recovery because downtime directly affects sales. Meanwhile, a noncritical internal reporting tool may tolerate longer downtime without severe consequences.
IT teams must evaluate these priorities carefully and create recovery strategies based on business impact. This ensures that resources are focused on restoring the most important systems first during emergencies.
Infrastructure management is another major responsibility. IT departments maintain servers, storage systems, network equipment, databases, cloud environments, and communication platforms. Continuity planning requires teams to design these environments with resilience in mind.
Redundancy is a key concept in resilient infrastructure design. Redundant systems provide backup resources that continue operating when primary systems fail. Examples include duplicate servers, secondary internet connections, backup power systems, and mirrored databases.
Failover systems are also essential. A failover process automatically transfers operations from a failed system to a backup environment. This minimizes downtime and improves service availability during disruptions.
IT teams are also responsible for data protection. Organizations generate massive amounts of information every day, including customer records, financial data, operational reports, and intellectual property. Losing this information can create severe financial and legal consequences.
Backup strategies help protect against data loss. Effective backup systems create copies of important information and store them securely in multiple locations. These backups allow organizations to restore systems after failures, cyberattacks, or accidental deletions.
Cybersecurity management is another critical area of responsibility. IT departments implement security controls such as firewalls, antivirus software, multi-factor authentication, and intrusion detection systems. Continuity planning must include cybersecurity response procedures that help organizations contain threats and recover safely.
Communication coordination is equally important during disruptions. IT teams must provide updates to leadership, employees, customers, and vendors throughout recovery efforts. Clear communication reduces confusion and helps maintain organizational stability during crises.
Understanding Business Impact Analysis
A business impact analysis is one of the most important parts of continuity planning. This process helps organizations understand which systems are most critical and what consequences may occur if those systems become unavailable.
The purpose of a business impact analysis is to identify operational priorities. IT departments work with business leaders to evaluate how different systems support organizational functions and how downtime affects productivity, revenue, customer service, and compliance.
Some systems may support essential activities that cannot tolerate long outages. Others may be less critical and capable of remaining offline temporarily without major consequences.
For example, a hospital may prioritize patient management systems because downtime could affect healthcare delivery and patient safety. An online retailer may prioritize payment processing systems because outages directly affect sales revenue.
A business impact analysis also helps organizations estimate financial losses associated with downtime. Understanding these costs helps leadership teams justify investments in resilience, redundancy, and recovery infrastructure.
The analysis process often includes identifying dependencies between systems. Modern environments are highly interconnected, and failures in one area may affect other services unexpectedly. Mapping these relationships helps organizations develop more effective recovery strategies.
Business impact analyses should be reviewed regularly because organizational priorities and technology environments change over time. New applications, cloud platforms, and operational processes may alter recovery requirements significantly.
The Importance of Risk Assessments
Risk assessments help organizations identify vulnerabilities before they lead to major problems. Instead of waiting for disruptions to occur, IT teams proactively evaluate threats and strengthen weak areas within the environment.
An effective risk assessment examines multiple categories of threats, including cybersecurity risks, hardware failures, environmental hazards, software issues, and operational weaknesses.
Cybersecurity assessments evaluate areas such as password policies, endpoint security, network protection, and access controls. Hardware assessments examine equipment reliability, maintenance procedures, and redundancy capabilities.
Environmental assessments focus on physical risks such as fire hazards, flooding, and power reliability. Operational assessments review communication processes, staffing readiness, and recovery documentation.
Risk assessments also help organizations identify single points of failure. A single point of failure exists when one system or component can disrupt operations if it becomes unavailable. Eliminating these weaknesses improves resilience significantly.
For example, relying on a single internet connection may create unnecessary risk. Installing secondary connectivity solutions helps maintain operations during outages. Similarly, storing backups only in one physical location increases vulnerability to disasters.
The goal of risk assessment is not to eliminate every possible threat because that is unrealistic. Instead, organizations focus on reducing the likelihood and impact of disruptions through strategic planning and protective measures.
Recovery Objectives and Service Priorities
Business continuity planning requires organizations to define clear recovery goals. These goals help IT teams prioritize systems and measure recovery performance during disruptions.
Recovery Time Objective refers to the maximum acceptable amount of downtime for a system or service. Different systems have different recovery expectations depending on their importance to the business.
Some applications may require restoration within minutes, while others can remain unavailable for several hours without severe consequences. Clearly defining recovery expectations helps IT teams allocate resources effectively.
Recovery Point Objective measures acceptable data loss during recovery situations. This objective determines how much information an organization can afford to lose between backups.
For example, some businesses may tolerate losing one hour of transaction data, while others require near real-time backups to minimize information loss.
These recovery objectives guide decisions related to backup frequency, infrastructure investment, and recovery architecture. Systems with strict recovery requirements often require more advanced resilience strategies.
Clear objectives also improve communication between IT teams and leadership. Everyone understands recovery expectations and operational priorities before emergencies occur.
Building an Effective IT Business Continuity Strategy
Creating a business continuity strategy requires far more than simply writing recovery procedures in a document. Effective continuity planning involves understanding business operations, identifying risks, preparing backup systems, establishing communication processes, and continuously improving recovery capabilities. IT departments must approach continuity planning as an ongoing operational responsibility rather than a one-time project.
Organizations today face a wide variety of disruptions that can affect technology systems and business operations. Cyberattacks, cloud outages, hardware failures, software errors, natural disasters, and human mistakes can all interrupt services unexpectedly. Without a structured continuity strategy, businesses often experience prolonged downtime, data loss, operational confusion, and financial damage.
An effective continuity strategy helps organizations reduce these risks by preparing systems, employees, and recovery procedures in advance. Instead of scrambling to make decisions during emergencies, IT teams can follow predefined plans that support faster recovery and more stable operations.
One of the most important aspects of continuity planning is preparation. Businesses that prepare early typically recover more successfully than organizations that react only after disruptions occur. Preparation allows teams to identify weaknesses, improve infrastructure resilience, and create clear response procedures before crises begin.
IT continuity strategies should also align with business priorities. Technology systems exist to support organizational goals, customer needs, and operational functions. Recovery planning therefore requires collaboration between IT departments and business leadership to ensure critical services receive the highest level of protection.
Developing a Structured Continuity Framework
A structured framework provides the foundation for successful continuity planning. Without organization and clear processes, recovery efforts can become inconsistent and ineffective during emergencies.
The first step in building a framework is identifying critical operational functions. IT teams must understand which systems support the most important business activities and determine how disruptions would affect employees, customers, and revenue.
Some systems may be absolutely essential for business survival. Payment platforms, communication services, cloud applications, customer databases, and authentication systems often fall into this category. If these systems become unavailable, operations may stop almost immediately.
Other systems may still be important but capable of tolerating longer downtime periods. Internal reporting tools, nonessential applications, or archived data systems may not require immediate restoration during emergencies.
Categorizing systems by priority allows organizations to focus recovery resources more effectively. During disruptions, IT teams can restore high-priority services first while addressing less critical systems later.
A structured continuity framework should also include clearly defined roles and responsibilities. During emergencies, confusion often occurs when employees are unsure who is responsible for specific tasks. Clear assignments reduce delays and improve coordination.
For example, one team may manage infrastructure recovery while another handles communication with leadership and customers. Security specialists may focus on incident containment while cloud engineers restore virtual environments.
Documentation is another critical component of continuity frameworks. Recovery procedures, infrastructure diagrams, contact information, vendor details, and escalation processes should all be documented clearly and stored securely. During emergencies, teams need quick access to accurate information.
Organizations should also ensure continuity documentation remains accessible during outages. Storing recovery plans only on unavailable systems can create major problems during crises. Many businesses maintain both digital and offline copies of critical documentation.
Strengthening Infrastructure Resilience
Infrastructure resilience is one of the most important aspects of business continuity planning. Resilient infrastructure helps organizations maintain operations even when failures occur.
Redundancy is a key principle in resilient infrastructure design. Redundant systems provide backup resources that continue operating when primary systems fail. This prevents single failures from causing widespread outages.
For example, organizations may use multiple servers to host important applications. If one server becomes unavailable, another server can continue handling workloads without interrupting services. Similarly, businesses may install backup internet connections to maintain connectivity during provider outages.
Power redundancy is equally important. Data centers and office environments often use uninterruptible power supplies and backup generators to maintain operations during electrical failures. Without these protections, even brief power interruptions can damage systems and disrupt services.
Storage redundancy also helps protect data availability. Technologies such as RAID configurations, replicated storage systems, and geographically distributed backups reduce the risk of permanent data loss during hardware failures.
Network resilience is another major priority. Businesses rely heavily on network connectivity for communication, cloud access, and application availability. Redundant network paths, load balancing, and failover routing improve stability during disruptions.
Cloud computing has introduced additional opportunities for resilience. Many cloud providers offer distributed infrastructure that spans multiple geographic regions. Organizations can use these capabilities to improve availability and reduce downtime risks.
For example, applications may operate across multiple cloud regions simultaneously. If one region experiences an outage, workloads can continue running in another location. This approach improves service continuity significantly.
However, organizations should not assume cloud services automatically eliminate continuity risks. Cloud providers can still experience outages, misconfigurations, or security incidents. Businesses must therefore create independent recovery strategies even when using cloud infrastructure.
Hybrid environments also require careful planning. Many organizations use combinations of on-premises infrastructure and cloud services. These interconnected systems create additional complexity because failures in one environment may affect others.
IT teams must understand how systems interact and ensure recovery procedures account for these dependencies. Without proper planning, organizations may restore one system only to discover connected services remain unavailable.
Implementing Reliable Backup Strategies
Backups are among the most important elements of continuity planning because they protect organizations from permanent data loss. Without reliable backups, businesses may struggle to recover after cyberattacks, hardware failures, or accidental deletions.
A strong backup strategy includes multiple layers of protection. Organizations should create backups regularly, store them securely, and verify that recovery procedures work correctly.
Backup frequency depends on operational requirements and acceptable data loss limits. Some organizations perform backups once daily, while others require continuous replication or near real-time synchronization.
Businesses with high transaction volumes often require frequent backups because losing even small amounts of recent data may create significant operational or financial problems.
Storage location is another critical consideration. Storing backups only in the same physical location as production systems creates unnecessary risk. Fires, floods, theft, or infrastructure failures may affect both primary systems and local backups simultaneously.
Off-site storage provides additional protection by keeping backup copies in separate geographic locations. Cloud-based backup solutions have become especially popular because they offer scalability, remote accessibility, and geographic redundancy.
Organizations should also follow the principle of maintaining multiple backup copies. Keeping several versions of backups reduces the risk of corruption or accidental overwriting.
Immutable backups provide another layer of security. These backups cannot be modified or deleted for a specific period, making them highly effective against ransomware attacks. Even if attackers compromise production systems, immutable backups remain protected.
Testing backups is equally important. Many organizations create backups regularly but fail to verify whether data can actually be restored successfully. Recovery testing helps identify corrupted files, incomplete backups, or configuration problems before real emergencies occur.
Backup restoration exercises should simulate realistic recovery situations. IT teams should practice restoring systems, applications, and databases under time constraints similar to actual incidents. These exercises improve preparedness and increase confidence in recovery capabilities.
Documentation of backup procedures is also essential. Teams must understand backup schedules, storage locations, retention policies, and restoration processes clearly. During emergencies, confusion about backup availability can delay recovery significantly.
The Importance of Disaster Recovery Planning
Disaster recovery planning focuses specifically on restoring IT systems after major disruptions. While business continuity planning covers broader operational resilience, disaster recovery concentrates on technical restoration processes.
An effective disaster recovery plan outlines how systems will be recovered, which teams are responsible for specific tasks, and how long restoration should take. This structured approach improves coordination during emergencies.
Disaster recovery planning begins with identifying critical systems and establishing recovery priorities. Organizations must determine which applications, databases, and infrastructure components require immediate restoration.
Recovery environments are another major consideration. Some organizations maintain secondary data centers that can take over operations during emergencies. Others use cloud-based recovery environments that activate only when needed.
Hot sites provide fully operational backup environments capable of supporting immediate failover. Warm sites offer partially prepared environments that require some configuration before use. Cold sites provide physical infrastructure but require substantial setup during recovery situations.
The choice between these approaches depends on business requirements, recovery expectations, and budget considerations.
Automation has become increasingly valuable in disaster recovery. Automated failover systems can detect outages and switch workloads to backup environments quickly. This reduces manual intervention and improves recovery speed.
Recovery procedures should also include verification steps. Restoring systems is not enough if applications remain unstable or data becomes corrupted. IT teams must validate functionality carefully before returning systems to normal operations.
Disaster recovery plans should account for different types of incidents. Cybersecurity attacks may require different recovery procedures than hardware failures or natural disasters. Flexible planning improves adaptability during unpredictable situations.
Communication remains essential throughout recovery processes. Leadership teams, employees, customers, and vendors all require updates regarding operational status and expected recovery timelines. Clear communication reduces uncertainty and maintains trust during disruptions.
Managing Cybersecurity Risks in Continuity Planning
Cybersecurity has become one of the most important aspects of business continuity planning. Modern attacks can disrupt operations, compromise sensitive data, and create long-term reputational damage.
Ransomware attacks are especially dangerous because they target operational continuity directly. Attackers encrypt systems and demand payment in exchange for restoration keys. Organizations without reliable backups may face difficult recovery decisions.
Continuity planning helps reduce ransomware risks by establishing secure backup strategies, incident response procedures, and recovery environments. Businesses that prepare in advance often recover faster and avoid paying attackers.
Network segmentation is another valuable security strategy. Dividing networks into separate sections limits the spread of malware and reduces operational impact during breaches.
Access control policies also improve resilience. Employees should receive only the system access necessary for their roles. Limiting permissions reduces the likelihood of widespread compromise if accounts become breached.
Multi-factor authentication adds additional protection by requiring multiple forms of verification before granting access. This significantly reduces unauthorized access risks.
Continuous monitoring helps organizations detect suspicious activity early. Monitoring systems can identify unusual login attempts, malware behavior, or network anomalies before incidents escalate into major disruptions.
Employee awareness training is equally important. Many attacks begin with phishing emails or social engineering attempts. Educating employees about cybersecurity threats reduces the likelihood of successful attacks.
Incident response procedures should integrate closely with continuity planning. Organizations must know how to isolate infected systems, contain attacks, and restore operations safely.
Cybersecurity recovery also requires careful coordination with legal, compliance, and communication teams. Data breaches may involve regulatory reporting obligations and public communication responsibilities.
Communication Planning During Emergencies
Communication is one of the most overlooked aspects of continuity planning, yet it often determines how effectively organizations manage crises.
During disruptions, employees need clear instructions regarding operational expectations, recovery progress, and safety procedures. Without communication, confusion spreads quickly and productivity declines further.
Leadership teams also require regular updates to make informed decisions about operations, customer communication, and resource allocation.
External communication is equally important. Customers, partners, and vendors need transparency regarding service disruptions and recovery timelines. Organizations that communicate honestly often maintain stronger trust during difficult situations.
Communication plans should define who is responsible for providing updates, which communication channels will be used, and how frequently information will be shared.
Multiple communication channels are important because primary systems may become unavailable during emergencies. Organizations often maintain backup messaging platforms, emergency contact systems, and alternative communication methods.
Consistency is also critical. Conflicting information from different departments can increase confusion and damage credibility. Centralized communication coordination improves accuracy and professionalism.
Communication planning should also include escalation procedures. Teams must understand when to involve leadership, legal departments, cybersecurity specialists, or external vendors during incidents.
Media management may become necessary during large-scale disruptions. Public statements should be accurate, transparent, and carefully coordinated to protect organizational reputation.
Testing Continuity and Recovery Procedures
A continuity plan is only valuable if it functions effectively during real emergencies. Testing helps organizations validate recovery procedures, identify weaknesses, and improve preparedness before actual incidents occur.
Tabletop exercises are one common testing method. Teams discuss simulated scenarios and review how they would respond to specific disruptions. These exercises improve coordination and reveal planning gaps.
Technical recovery tests involve restoring systems, activating backup environments, and verifying operational functionality. These exercises provide practical validation of recovery capabilities.
Cybersecurity simulations help organizations practice responding to attacks such as ransomware incidents or data breaches. These exercises improve incident response coordination and technical recovery processes.
Organizations should also test communication procedures regularly. Employees must understand emergency notification systems, escalation paths, and reporting responsibilities.
Testing should occur consistently because technology environments change frequently. New applications, infrastructure updates, and organizational changes may affect recovery procedures significantly.
After each test, organizations should review results carefully and document lessons learned. Continuous improvement is essential for maintaining effective continuity capabilities.
Businesses that test regularly often recover much faster during real disruptions because employees are familiar with procedures and systems have already been validated under simulated conditions.
Creating a Long-Term Continuity Culture
Business continuity planning should become part of organizational culture rather than existing as an isolated technical initiative.
Preparedness requires ongoing attention, investment, and collaboration across departments. Leadership teams must support resilience efforts and recognize continuity planning as a strategic priority.
Employees at all levels should understand the importance of continuity and their roles during emergencies. Training programs, awareness initiatives, and regular exercises help reinforce preparedness throughout the organization.
Technology environments will continue evolving rapidly. Cloud adoption, artificial intelligence, remote work, and digital transformation initiatives all introduce new operational risks and recovery requirements.
Organizations that maintain strong continuity cultures are better prepared to adapt to these changes while protecting operational stability. Instead of viewing disruptions as isolated events, resilient businesses continuously improve systems, processes, and recovery strategies over time.
Ultimately, continuity planning is about protecting people, operations, and organizational trust. Businesses that invest in resilience today are far more likely to succeed during future disruptions and maintain stability in increasingly complex digital environments.
Maintaining Long-Term IT Resilience and Operational Stability
Business continuity planning does not end once recovery procedures are documented and backup systems are deployed. Technology environments constantly evolve, new cybersecurity threats emerge regularly, and business operations continue changing over time. Because of this, organizations must treat continuity planning as an ongoing process focused on continuous improvement, operational resilience, and long-term stability.
IT departments play a critical role in maintaining this resilience. Their responsibility extends beyond restoring systems during emergencies. They must also monitor infrastructure health, improve recovery capabilities, educate employees, evaluate new risks, and ensure the organization remains prepared for future disruptions.
As businesses become increasingly dependent on digital systems, continuity planning becomes more important every year. Organizations now rely on cloud services, remote work environments, artificial intelligence tools, mobile devices, and interconnected applications to support daily operations. While these technologies improve efficiency and flexibility, they also introduce additional complexity and potential vulnerabilities.
Maintaining long-term resilience requires businesses to think proactively rather than reactively. Waiting until systems fail before improving recovery capabilities often results in unnecessary downtime, financial losses, and operational confusion. Organizations that continuously strengthen continuity strategies are far more likely to recover successfully during major incidents.
The Importance of Continuous Monitoring
Continuous monitoring is one of the most valuable tools for maintaining operational stability. Monitoring systems help IT departments detect issues early before they escalate into larger disruptions.
Modern infrastructure environments generate enormous amounts of operational data. Servers, applications, cloud platforms, network devices, and security systems constantly produce logs and performance information. Monitoring tools analyze this data to identify abnormalities, performance degradation, and potential failures.
For example, monitoring systems may detect increasing server temperatures, unusual network traffic, storage capacity issues, or application response delays. These warnings allow IT teams to investigate and resolve problems before users experience service interruptions.
Cybersecurity monitoring is equally important. Threat detection systems can identify suspicious login attempts, malware activity, unauthorized access, and unusual user behavior. Early detection significantly improves incident response capabilities and reduces the likelihood of widespread operational damage.
Cloud monitoring has become especially important as organizations migrate workloads to distributed environments. Businesses often rely on multiple cloud providers and hybrid infrastructures that span several geographic locations. Monitoring helps IT teams maintain visibility across these complex environments.
Automated alerting systems improve response times further by notifying administrators immediately when critical issues occur. Instead of waiting for users to report problems, IT departments can begin troubleshooting as soon as monitoring systems identify anomalies.
Monitoring also supports capacity planning and infrastructure optimization. Organizations can analyze trends related to storage usage, bandwidth consumption, and application performance to anticipate future needs. This proactive approach reduces the likelihood of resource shortages causing operational disruptions.
Another major benefit of monitoring involves compliance and reporting. Many industries require organizations to maintain operational records, security logs, and audit trails. Monitoring systems help businesses meet these requirements while improving operational visibility.
Continuous monitoring should not focus only on technical infrastructure. Organizations should also monitor vendor performance, service reliability, and operational workflows. Third-party disruptions can affect business continuity just as significantly as internal failures.
By maintaining strong monitoring capabilities, organizations gain valuable insight into infrastructure health and operational risks. This visibility allows businesses to respond faster, reduce downtime, and maintain greater overall stability.
The Value of Regular Continuity Testing
Testing is one of the most important aspects of business continuity planning because it validates whether recovery strategies actually work under realistic conditions. A continuity plan that has never been tested may fail unexpectedly during a real emergency.
Many organizations make the mistake of creating recovery documentation and assuming systems will function properly during disruptions. However, untested procedures often contain hidden weaknesses, outdated information, or operational gaps.
Regular testing helps identify these issues before real incidents occur. IT teams can practice recovery procedures, evaluate system performance, and improve coordination across departments.
Tabletop exercises are a common starting point for continuity testing. During these sessions, employees discuss simulated scenarios and review how they would respond to specific incidents. These exercises improve communication and help teams understand their responsibilities during emergencies.
Technical recovery testing goes further by actively restoring systems, activating backup environments, and validating operational functionality. For example, IT teams may simulate server failures, cloud outages, or ransomware attacks to test recovery procedures in controlled environments.
Backup restoration testing is especially important. Organizations should verify regularly that backup data can actually be restored successfully. Corrupted backups or incomplete configurations may go unnoticed until recovery becomes urgently necessary.
Failover testing also helps organizations validate resilience capabilities. During these exercises, workloads are transferred from primary systems to backup environments to ensure continuity mechanisms function correctly.
Cybersecurity simulations provide additional value. Businesses can practice responding to phishing attacks, malware infections, or ransomware incidents while evaluating coordination between security teams and infrastructure administrators.
Testing should involve multiple departments whenever possible. Business continuity affects the entire organization, not just IT teams. Human resources, customer service, finance, leadership, and communications teams all play important roles during disruptions.
Organizations should also document lessons learned after every test. Recovery exercises often reveal communication issues, procedural weaknesses, or infrastructure limitations that require improvement.
Testing frequency depends on organizational complexity and risk exposure. Highly regulated industries or businesses with critical operational requirements may conduct exercises several times each year. Regardless of frequency, testing should remain consistent and ongoing.
Continuous testing helps organizations build confidence in recovery capabilities while ensuring employees remain familiar with emergency procedures.
Training Employees for Continuity Preparedness
Technology alone cannot guarantee successful continuity outcomes. Employees play a major role in preventing disruptions, responding to incidents, and supporting recovery efforts.
Training programs help employees understand operational risks, emergency procedures, and continuity responsibilities. Well-trained employees can react more effectively during crises and reduce the likelihood of mistakes worsening disruptions.
IT staff require specialized technical training related to disaster recovery, cybersecurity response, backup management, cloud recovery, and infrastructure troubleshooting. Because technology changes rapidly, continuous education is necessary to maintain current knowledge and skills.
Cybersecurity awareness training is especially important for all employees. Many security incidents begin with phishing emails, weak passwords, or social engineering attacks. Educating users about these threats significantly reduces organizational risk.
Employees should learn how to recognize suspicious activity, report security concerns, and follow safe operational practices. Regular awareness campaigns help reinforce these behaviors throughout the organization.
Communication training also supports continuity preparedness. Employees need to understand emergency notification procedures, escalation paths, and reporting responsibilities during incidents.
Remote work environments create additional training requirements. Employees accessing systems from multiple locations must understand secure access procedures, device management policies, and communication expectations during disruptions.
Leadership training is equally valuable. Managers and executives must know how to make decisions under pressure, coordinate recovery efforts, and communicate effectively with stakeholders during crises.
Organizations should also cross-train employees whenever possible. Cross-training ensures essential operational knowledge remains available even if key personnel become unavailable during emergencies.
Preparedness training should not occur only once. Regular refreshers, simulations, and awareness exercises help maintain readiness and reinforce continuity culture across the organization.
Businesses that invest in employee preparedness often recover more efficiently because staff members understand their roles and responsibilities during difficult situations.
Managing Vendor and Third-Party Risks
Modern organizations rely heavily on third-party vendors for cloud hosting, internet connectivity, software platforms, cybersecurity services, and operational support. While these partnerships improve efficiency and scalability, they also introduce additional continuity risks.
A disruption affecting a critical vendor can quickly affect business operations. For example, a cloud provider outage may interrupt customer-facing applications, while an internet service provider failure could prevent remote employees from accessing systems.
Business continuity planning must therefore include vendor risk management strategies. Organizations should evaluate the reliability, security practices, and continuity capabilities of critical service providers.
Vendor assessments often include reviewing disaster recovery procedures, service-level agreements, compliance certifications, and operational history. Understanding how vendors manage disruptions helps organizations evaluate potential risks.
Contracts should clearly define availability expectations, support responsibilities, and communication requirements during outages. Strong agreements improve accountability and reduce uncertainty during incidents.
Organizations should also avoid excessive dependence on single vendors whenever possible. Diversifying providers reduces the risk of widespread operational impact if one service becomes unavailable.
For example, businesses may use multiple internet providers, distribute workloads across cloud platforms, or maintain secondary communication systems. These strategies improve operational flexibility and resilience.
Vendor communication plans are equally important. Organizations need clear escalation procedures and emergency contact information for external providers during disruptions.
Regular vendor reviews help businesses ensure third-party relationships remain aligned with operational requirements and continuity goals.
Third-party cybersecurity risks require additional attention. Vendors with access to organizational systems or sensitive information may become targets for attackers. Security assessments and access controls help reduce these risks.
Managing vendor dependencies effectively strengthens overall continuity capabilities and reduces the likelihood of external disruptions causing severe operational damage.
The Role of Automation in Continuity Planning
Automation has become increasingly valuable in business continuity planning because it improves speed, accuracy, and operational efficiency during disruptions.
Automated monitoring systems detect issues quickly and generate alerts immediately when problems occur. This reduces response times and allows IT teams to address incidents before they escalate.
Automated backups improve data protection by ensuring information is copied consistently without relying entirely on manual processes. Organizations can schedule backups regularly and reduce the likelihood of human error affecting recovery capabilities.
Failover automation is another major advantage. Automated failover systems can transfer workloads from failed infrastructure to backup environments almost instantly. This minimizes downtime and improves service availability during outages.
Cloud environments often support extensive automation capabilities. Businesses can automatically scale resources, deploy recovery environments, and restore services based on predefined rules and operational triggers.
Security automation also strengthens continuity planning. Automated threat detection systems can isolate compromised devices, block suspicious activity, and trigger incident response workflows immediately after identifying attacks.
Automation reduces operational workloads during emergencies, allowing IT teams to focus on strategic decision-making rather than repetitive technical tasks.
However, organizations should not rely entirely on automation without human oversight. Automated systems can fail, generate false alerts, or behave unexpectedly during unusual scenarios. Human expertise remains essential for evaluating complex incidents and making informed recovery decisions.
Testing automated recovery processes regularly is also important. Organizations must ensure scripts, workflows, and failover systems continue functioning properly as infrastructure changes over time.
When implemented carefully, automation significantly improves continuity capabilities and operational resilience.
Creating a Culture of Preparedness
Business continuity planning works best when preparedness becomes part of organizational culture rather than existing only as a technical requirement.
A culture of preparedness encourages employees at all levels to think proactively about operational resilience, security, and risk management. Instead of viewing continuity planning as an isolated IT responsibility, organizations integrate resilience into everyday operations.
Leadership support plays a critical role in building this culture. Executives and managers must recognize continuity planning as a strategic priority and provide necessary resources for preparedness initiatives.
Employees should understand how their actions contribute to organizational resilience. Encouraging awareness, accountability, and proactive communication strengthens preparedness across departments.
Regular discussions about operational risks and recovery planning help maintain focus on continuity objectives. Organizations that prioritize resilience consistently often respond more effectively during real disruptions.
Preparedness culture also supports continuous improvement. Businesses that encourage feedback and operational learning adapt more successfully to evolving technologies and emerging threats.
Recognition programs and training initiatives can reinforce positive behaviors related to security awareness, operational readiness, and collaboration during recovery exercises.
Preparedness should also extend to physical environments. Emergency supplies, backup communication systems, and workspace recovery plans contribute to overall organizational resilience.
Remote and hybrid work models require additional cultural considerations. Employees working from multiple locations must remain connected to continuity processes and communication systems.
Organizations with strong preparedness cultures typically recover faster because employees understand operational priorities and respond more confidently during crises.
Addressing Common Continuity Challenges
Even organizations with strong continuity strategies face ongoing challenges related to operational resilience.
One common issue involves outdated documentation. Technology environments change rapidly, and recovery plans can become inaccurate if not updated regularly. New applications, infrastructure modifications, and organizational changes may affect recovery procedures significantly.
Regular reviews help ensure continuity documentation remains accurate and relevant.
Resource limitations create another challenge. Building highly resilient environments requires financial investment, staffing, and technical expertise. Organizations must balance operational budgets with continuity priorities carefully.
Complexity is also a growing concern. Modern infrastructures often include cloud services, hybrid environments, mobile devices, remote users, and interconnected applications. Managing recovery across these environments can become difficult without strong coordination and visibility.
Employee turnover introduces additional risk. Losing experienced personnel may reduce operational knowledge and affect recovery capabilities. Documentation and cross-training help reduce this vulnerability.
Cybersecurity threats continue evolving rapidly as well. Attackers constantly develop new techniques designed to bypass defenses and disrupt operations. Businesses must continuously adapt security strategies to address these emerging risks.
Communication failures remain another common challenge during emergencies. Confusion, inconsistent messaging, and delayed updates can worsen operational disruptions significantly.
Organizations should continuously evaluate these challenges and improve strategies proactively rather than waiting for failures to occur.
The Future of Business Continuity Planning
Technology will continue evolving rapidly, and continuity planning must evolve alongside it. Artificial intelligence, automation, edge computing, remote work, and cloud-native architectures are already reshaping operational environments.
Artificial intelligence may improve predictive monitoring, automated recovery, and threat detection capabilities significantly. Machine learning systems can identify anomalies faster and help organizations respond more proactively to potential disruptions.
Cloud adoption will likely continue increasing, creating greater dependence on distributed infrastructure and service providers. Businesses must therefore strengthen cloud resilience strategies and vendor management practices.
Cybersecurity will remain a central focus of continuity planning. Ransomware attacks, supply chain compromises, and advanced persistent threats will continue challenging organizations worldwide.
Environmental and geopolitical risks may also affect continuity planning in new ways. Climate-related disruptions, global supply chain issues, and regional instability can all influence operational resilience strategies.
Organizations that embrace continuous improvement and adaptability will be better prepared for these evolving challenges.
Conclusion
Business continuity planning has become an essential part of modern IT operations. As organizations grow increasingly dependent on technology, the impact of disruptions continues expanding across every aspect of business activity. Downtime, data loss, cybersecurity incidents, and operational failures can create serious financial, reputational, and legal consequences if businesses are not prepared.
Strong continuity planning helps organizations reduce these risks by building resilience into infrastructure, processes, and operational culture. Through continuous monitoring, reliable backups, disaster recovery planning, employee training, vendor management, and regular testing, businesses can improve their ability to withstand unexpected disruptions and recover more effectively.
IT departments play a central role in maintaining this resilience. Their responsibilities extend far beyond technical support because they help protect operational stability, customer trust, and long-term business success.
The most successful organizations understand that continuity planning is not a one-time task. It is an ongoing commitment to preparedness, improvement, and adaptability. Technology environments will continue evolving, and new challenges will continue emerging. Businesses that remain proactive, flexible, and resilient will be far better prepared to navigate future disruptions while maintaining stable and reliable operations.