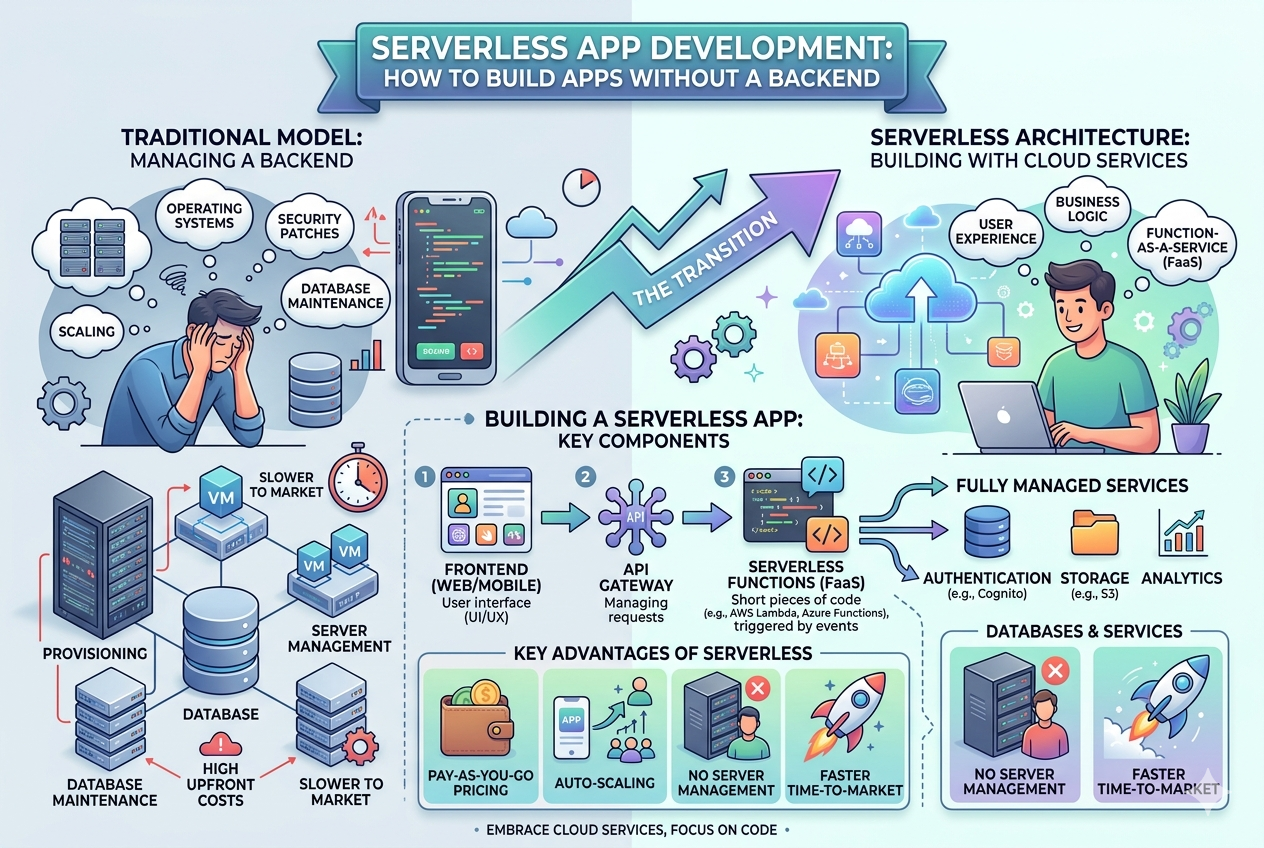
Serverless computing is not about the absence of servers, but rather about removing the need for developers to manage them directly. The infrastructure still exists, but it is completely abstracted away by cloud platforms. This abstraction allows developers to focus entirely on application logic while the underlying system handles provisioning, scaling, and execution automatically. The result is a development model that prioritizes speed, efficiency, and simplicity in building modern applications.
Event-Driven Nature of Serverless Applications
At the heart of serverless architecture lies an event-driven model. Every function in a serverless system is executed in response to a specific event. These events can come from user interactions, scheduled tasks, file uploads, database updates, or external API calls. Instead of running continuously like traditional servers, functions remain idle until triggered. This approach ensures that computing resources are used only when necessary, improving both performance and cost efficiency.
Function as a Service and Its Role
Function as a Service is the most common implementation of serverless architecture. It allows developers to write small, independent functions that perform a single task. These functions are deployed individually and executed in isolated environments when required. This modular design makes applications easier to manage, debug, and scale. Each function operates independently, which reduces the risk of system-wide failures.
Backend Services Without Traditional Servers
In serverless development, backend responsibilities are handled by managed cloud services. Instead of building and maintaining custom backend systems, developers rely on services for authentication, data storage, file management, and real-time communication. These services integrate seamlessly with serverless functions, forming a complete backend ecosystem without requiring server maintenance or manual scaling.
Database Integration in Serverless Applications
Databases in serverless environments are typically managed and highly scalable. They automatically adjust to traffic demands and do not require manual configuration for scaling. Serverless functions interact with databases through secure APIs, allowing data to be stored and retrieved efficiently. This separation between computation and storage helps improve performance and maintain system flexibility.
Scalability Without Manual Intervention
One of the most powerful features of serverless architecture is automatic scalability. When demand increases, the system automatically creates additional instances of functions to handle the load. When demand decreases, resources are reduced accordingly. This elasticity ensures that applications remain responsive under heavy traffic while minimizing unnecessary resource usage during low activity periods.
Cost Efficiency and Resource Optimization
Serverless computing follows a pay-as-you-use model, which significantly reduces operational costs. Instead of paying for idle server time, organizations are billed only for the actual execution of functions. This makes serverless especially attractive for startups, small businesses, and applications with unpredictable traffic patterns. Resource optimization is built into the system by design, eliminating wasteful infrastructure usage.
Security Considerations in Serverless Environments
Security in serverless architecture is managed at multiple layers. Cloud providers handle infrastructure security, including physical servers and virtualization layers. Developers are responsible for securing application logic, managing permissions, and ensuring proper authentication. Since functions are isolated, the attack surface is often smaller compared to traditional monolithic systems. However, proper configuration is essential to prevent vulnerabilities.
Performance Characteristics and Cold Start Behavior
Although serverless systems are highly efficient, they may experience latency during initial execution, commonly known as cold starts. This occurs when a function is triggered after a period of inactivity and needs to be initialized. While modern cloud platforms have reduced this delay significantly, it remains an important consideration for performance-sensitive applications. Warm execution, where functions remain active for repeated use, helps mitigate this issue.
Development Workflow in Serverless Architecture
Developing serverless applications involves a different workflow compared to traditional backend systems. Developers write small functions, define event triggers, and deploy them individually. Continuous integration and deployment practices are commonly used to automate updates. This workflow encourages rapid iteration and allows teams to push updates frequently without downtime.
Monitoring and Debugging Challenges
Since serverless applications are distributed across multiple functions and services, monitoring becomes more complex. Developers must track logs, performance metrics, and execution flows across different components. Debugging issues requires understanding how functions interact within the system. Modern observability tools help visualize execution paths and identify performance bottlenecks, making it easier to manage complex serverless architectures.
Integration with Frontend Applications
Serverless backends integrate smoothly with modern frontend frameworks. Applications communicate with backend functions through APIs, allowing dynamic data exchange. This separation between frontend and backend enables developers to work independently on different parts of the application. It also supports highly responsive and scalable user interfaces that rely on real-time data processing.
Microservices and Serverless Synergy
Serverless architecture naturally aligns with microservices principles. Each function can be considered a microservice that performs a specific task. This modular structure allows teams to develop, deploy, and scale components independently. It also improves fault isolation, meaning that a failure in one function does not affect the entire system. This synergy enhances system reliability and maintainability.
Real-Time Data Processing Capabilities
Serverless systems are highly effective for real-time data processing tasks. They can handle streaming data, process events instantly, and trigger automated workflows. This makes them suitable for applications such as analytics platforms, notification systems, and IoT solutions. The ability to process data in real time without dedicated infrastructure adds significant flexibility to application design.
Limitations and Design Constraints
Despite its advantages, serverless architecture is not suitable for every use case. Long-running processes, highly stateful applications, and workloads requiring consistent low-latency performance may face limitations. Additionally, reliance on third-party cloud providers introduces dependency concerns. Developers must carefully evaluate architectural requirements before adopting a serverless approach.
Best Practices for Building Serverless Applications
Effective serverless development requires careful planning and design. Functions should be kept small and focused on single responsibilities. Stateless design should be prioritized to ensure scalability and reliability. Efficient use of triggers and event sources helps optimize performance. Proper error handling and logging are also essential for maintaining system stability.
Future of Serverless Computing
Serverless computing continues to evolve rapidly as cloud technologies advance. Improvements in execution speed, tooling, and integration capabilities are making it more practical for a wider range of applications. As adoption grows, serverless architecture is expected to become a standard approach for building scalable and efficient cloud-based systems. It represents a shift toward fully managed computing environments where developers focus entirely on innovation rather than infrastructure management.
Advanced Scaling Mechanisms in Serverless Systems
Serverless platforms are designed to scale automatically, but advanced scaling goes beyond simply increasing the number of function instances. Modern cloud systems use intelligent load distribution, regional replication, and concurrency management to ensure applications remain stable under extreme traffic conditions. When demand spikes, new instances of functions are created almost instantly across multiple availability zones. This distributed execution model ensures that no single server becomes a bottleneck, allowing applications to handle unpredictable workloads with ease.
Concurrency Control and Execution Limits
Every serverless platform imposes certain limits on concurrent executions to maintain system stability. Concurrency refers to how many instances of a function can run at the same time. When properly configured, concurrency ensures optimal performance without overwhelming backend resources. Developers often implement throttling strategies or request queuing systems to manage high traffic scenarios. Understanding concurrency behavior is essential for building reliable and scalable applications in production environments.
State Management in Stateless Systems
Serverless functions are inherently stateless, meaning they do not retain information between executions. This design improves scalability but introduces challenges for applications that require persistent state. To overcome this, external storage systems such as databases, caching layers, or object storage services are used. Each function retrieves the required data at runtime, processes it, and stores the updated state externally. This separation of computation and state allows for greater flexibility and reliability.
Workflow Orchestration in Serverless Applications
Complex applications often require multiple functions to work together in a defined sequence. Workflow orchestration tools help manage these interactions by coordinating the execution of serverless functions. Instead of manually linking functions, developers define workflows that automatically trigger the next step based on previous outcomes. This approach is especially useful for multi-step processes such as payment processing, data transformation pipelines, and user onboarding systems.
Serverless Architecture Design Patterns
Several architectural patterns have emerged specifically for serverless development. One common pattern is the API-driven model, where functions are exposed through API endpoints. Another is the event-driven pipeline, where each function processes data and passes it to the next stage. The fan-out pattern allows a single event to trigger multiple functions in parallel, while the fan-in pattern aggregates results from multiple functions into a single output. These patterns help structure applications for better scalability and maintainability.
Data Flow Optimization in Serverless Systems
Efficient data flow is critical for serverless performance. Since functions are stateless and short-lived, minimizing unnecessary data transfer improves execution speed and reduces cost. Developers often design systems to pass only essential data between functions. Large datasets are stored externally, and functions retrieve them only when needed. This approach reduces latency and ensures smoother execution across distributed environments.
Cold Start Optimization Techniques
Cold start latency remains one of the key challenges in serverless computing. To reduce delays, developers use techniques such as keeping functions warm through scheduled invocations or optimizing runtime environments for faster initialization. Choosing lightweight dependencies and minimizing package size also improves startup performance. Some platforms offer provisioned concurrency, where a certain number of function instances are always kept ready to handle requests instantly.
Security Architecture in Distributed Functions
Security in serverless systems is built around the principle of least privilege. Each function is assigned only the permissions it needs to perform its task. Identity and access management systems control interactions between services, ensuring secure communication. Encryption is used for data in transit and at rest, while environment variables are protected to prevent unauthorized access. Since functions are isolated, security breaches are often contained within a single component rather than affecting the entire system.
Logging and Observability in Serverless Applications
Observability is essential for maintaining serverless applications at scale. Since functions execute independently, tracking their behavior requires centralized logging and monitoring systems. Logs capture execution details, errors, and performance metrics, which are then aggregated for analysis. Tracing tools help visualize how requests move through different functions, making it easier to identify bottlenecks and diagnose issues. Effective observability ensures system reliability and simplifies debugging.
Cost Management Strategies
Although serverless computing is generally cost-efficient, improper design can lead to unexpected expenses. High-frequency function invocations, inefficient code, or excessive data transfer can increase costs significantly. Developers must optimize function execution time and reduce unnecessary invocations. Caching frequently used data and minimizing external service calls also contribute to better cost control. Monitoring usage patterns helps identify areas where optimization is needed.
Integration with Third-Party Services
Serverless applications often rely heavily on third-party services for extended functionality. These services include authentication providers, payment gateways, messaging systems, and analytics tools. Integration is typically handled through APIs, allowing seamless communication between services. This ecosystem-based approach reduces development effort and enables rapid feature expansion without building everything from scratch.
Handling Failures and Retry Mechanisms
Failure handling is a critical aspect of serverless design. Since functions operate independently, failures must be managed at the function level. Retry mechanisms are commonly implemented to automatically re-execute failed functions. Dead-letter queues are used to capture failed events for later analysis. These strategies ensure that transient errors do not disrupt the overall application flow.
Real-World Use Cases of Serverless Systems
Serverless architecture is widely used in real-world applications across industries. E-commerce platforms use it for handling order processing and inventory updates. Media companies rely on it for video processing and content delivery. Financial systems use serverless functions for fraud detection and transaction monitoring. Its flexibility makes it suitable for applications that require dynamic scaling and event-driven processing.
Hybrid Architectures Combining Serverless and Traditional Systems
Many organizations adopt hybrid architectures that combine serverless components with traditional backend systems. This approach allows them to leverage the strengths of both models. Serverless functions handle dynamic and event-driven workloads, while traditional servers manage long-running or stateful processes. This balance provides flexibility while maintaining control over critical systems.
Developer Experience and Tooling Improvements
The developer experience in serverless computing has improved significantly with modern tools and frameworks. These tools simplify deployment, testing, and monitoring of serverless applications. Local development environments simulate cloud behavior, allowing developers to test functions before deployment. Automation tools streamline continuous integration and delivery, making the development process faster and more efficient.
Performance Tuning and Optimization Techniques
Optimizing serverless performance involves careful attention to function design, execution time, and resource usage. Reducing cold starts, minimizing dependencies, and optimizing code logic all contribute to better performance. Developers also analyze execution metrics to identify inefficiencies and improve system responsiveness. Performance tuning is an ongoing process that ensures applications remain efficient as they scale.
Future Trends in Serverless Computing
Serverless computing continues to evolve toward more advanced and intelligent systems. Emerging trends include better support for long-running workflows, improved debugging tools, and deeper integration with artificial intelligence services. Edge computing is also becoming increasingly relevant, allowing serverless functions to run closer to users for lower latency. These advancements are shaping the future of cloud-native application development.
Building Production-Grade Serverless Applications
Moving from basic serverless functions to production-ready systems requires careful architectural planning. At scale, applications must handle high traffic, ensure reliability, and maintain consistent performance. This involves designing functions with clear boundaries, separating concerns across services, and ensuring that every component is independently deployable. Production-grade serverless systems are not just collections of functions but carefully engineered ecosystems where each part plays a defined role in the overall workflow.
Domain-Driven Design in Serverless Systems
Domain-driven design becomes especially useful in serverless architecture because it helps structure complex systems into meaningful business domains. Each domain can be mapped to a group of serverless functions responsible for specific business logic. This approach improves maintainability and ensures that changes in one domain do not unintentionally affect others. By aligning functions with business capabilities, development teams can work more efficiently and reduce architectural complexity.
Event Sourcing and Data Consistency Models
In distributed serverless systems, maintaining data consistency is a major challenge. Event sourcing is a design approach where all changes in the system are stored as a sequence of events rather than overwriting data directly. Each event represents a state change, allowing the system to reconstruct the current state at any time. This model improves traceability and makes it easier to debug complex workflows, especially in applications with high transaction volumes.
Serverless API Design and Gateway Management
APIs serve as the primary interface between users and serverless functions. Proper API design is essential for performance, security, and scalability. API gateways manage incoming requests, route them to appropriate functions, and handle authentication, throttling, and caching. A well-structured API layer ensures that backend logic remains decoupled from client applications, enabling independent evolution of both frontend and backend systems.
Latency Reduction Strategies in Distributed Environments
Latency is a critical factor in serverless applications, especially those serving global users. Reducing latency involves optimizing function execution time, minimizing cold starts, and strategically deploying functions across multiple regions. Edge computing also plays a role by executing functions closer to the user’s location. This distributed approach significantly improves response times and enhances user experience in real-time applications.
Caching Mechanisms for Performance Optimization
Caching is an essential optimization technique in serverless architecture. Frequently accessed data is stored in fast-access storage layers to reduce repeated computation and database queries. This improves response time and reduces operational costs. Cache invalidation strategies ensure that outdated data is refreshed appropriately. When implemented correctly, caching can dramatically enhance system performance under heavy load.
Database Architecture Choices in Serverless Systems
Choosing the right database architecture is critical for serverless applications. Managed NoSQL databases are often preferred due to their scalability and flexibility. They allow dynamic schema changes and can handle large volumes of unstructured data. Relational databases are also used when strong consistency and structured relationships are required. The key is to design data access patterns that align with function-based execution models.
Asynchronous Processing and Message Queues
Asynchronous processing is a core concept in serverless systems. Instead of executing tasks immediately, functions can place messages in queues for later processing. This decouples system components and improves resilience under heavy load. Message queues ensure that tasks are processed reliably even if downstream services are temporarily unavailable. This design pattern is widely used in background processing, data pipelines, and notification systems.
Fault Tolerance and System Resilience
Fault tolerance ensures that applications continue functioning even when individual components fail. In serverless architecture, resilience is achieved through retries, redundancy, and graceful degradation. Functions are designed to fail independently without affecting the entire system. Circuit breakers and fallback mechanisms help prevent cascading failures, ensuring system stability under unpredictable conditions.
Security Hardening for Enterprise Serverless Applications
Enterprise-grade serverless systems require strict security controls. This includes fine-grained access policies, encrypted communication channels, and secure secret management. Each function operates with minimal permissions, reducing the risk of unauthorized access. Security audits and automated vulnerability scanning help identify potential weaknesses. In highly regulated industries, compliance requirements also influence system design and data handling practices.
Infrastructure as Code in Serverless Deployment
Infrastructure as code allows developers to define cloud resources using configuration files instead of manual setup. This approach ensures consistency across environments and simplifies deployment processes. Serverless applications benefit significantly from this model because entire systems, including functions, APIs, and databases, can be version-controlled and deployed automatically. This reduces human error and improves repeatability.
Continuous Integration and Continuous Deployment Pipelines
CI/CD pipelines are essential for maintaining fast and reliable serverless development cycles. Every code change is automatically tested, validated, and deployed if it meets quality standards. Automated pipelines reduce deployment time and ensure that updates reach production quickly. This approach supports agile development practices and allows teams to iterate rapidly without compromising stability.
Observability at Scale in Distributed Systems
As serverless applications grow, observability becomes more complex. Monitoring systems must track thousands of function executions across multiple regions. Distributed tracing helps visualize request flows across services, while metrics provide insights into performance trends. Centralized logging ensures that all execution data is accessible for analysis. Together, these tools provide a complete view of system behavior in real time.
Cost Optimization at Enterprise Scale
At scale, even small inefficiencies can lead to significant cost increases. Optimizing serverless systems involves reducing execution time, minimizing unnecessary invocations, and selecting appropriate memory configurations for functions. Data transfer costs and external service usage must also be carefully monitored. Enterprises often implement automated cost alerts and optimization policies to maintain budget control.
Multi-Tenant Serverless Architectures
Multi-tenant systems serve multiple users or organizations from a single infrastructure. In serverless architecture, this requires careful isolation of data and execution environments. Each tenant’s data must remain secure and separate while sharing underlying resources efficiently. Proper isolation strategies ensure scalability without compromising security or performance.
Edge Computing and Distributed Serverless Execution
Edge computing extends serverless architecture beyond centralized cloud regions. Functions are executed closer to end users, reducing latency and improving responsiveness. This is particularly useful for applications requiring real-time interaction, such as gaming, streaming, and IoT systems. Edge-based serverless execution represents the next step in distributed computing evolution.
Machine Learning Integration with Serverless Platforms
Serverless systems are increasingly used for machine learning workflows. Functions can preprocess data, trigger model training, and serve predictions in real time. This allows scalable and cost-efficient deployment of AI-driven applications. By combining serverless architecture with machine learning models, developers can build intelligent systems without managing complex infrastructure.
Handling High-Traffic Event Bursts
Serverless systems are well-suited for handling sudden spikes in traffic, such as product launches or viral events. Automatic scaling ensures that additional resources are allocated instantly. However, proper design is required to prevent downstream bottlenecks in databases or external services. Load balancing and queue-based buffering help stabilize the system during extreme demand.
Long-Term Evolution of Serverless Architecture
Serverless computing is evolving toward more integrated and intelligent cloud ecosystems. Future systems are expected to reduce cold starts further, improve debugging capabilities, and offer deeper automation in deployment and scaling. As abstraction increases, developers will focus even less on infrastructure and more on solving business problems directly.
Final Perspective on Serverless Transformation
Serverless architecture represents a fundamental shift in software development philosophy. It removes traditional infrastructure barriers and enables highly scalable, efficient, and event-driven systems. When designed correctly, serverless applications offer unmatched flexibility and operational simplicity. As cloud technology continues to mature, serverless computing is expected to become a core foundation of modern digital infrastructure.
Scaling Serverless Beyond Simple Applications
At enterprise level, serverless architecture evolves far beyond simple function-based applications. Large systems require coordination across hundreds or even thousands of functions, multiple regions, and interconnected services. Scaling at this level is not just about handling traffic but about maintaining architectural clarity, operational stability, and predictable behavior across all environments. Enterprises must design systems that remain manageable even as complexity grows significantly over time.
Composable Architecture and Modular System Design
A key principle in large-scale serverless systems is composability. Applications are designed as independent modules that can be combined in different ways without changing their internal logic. Each module performs a specific business function and communicates through well-defined interfaces. This modularity allows teams to develop, test, and deploy components independently, reducing coordination overhead and improving development speed across large organizations.
Choreography vs Orchestration in Distributed Workflows
Serverless systems often rely on two major workflow patterns: choreography and orchestration. In choreography, functions communicate through events without a central controller, creating a decentralized system where each component reacts independently. In orchestration, a central workflow manager controls the execution order of functions. Both approaches have advantages, and modern systems often combine them depending on complexity, reliability requirements, and business logic structure.
Advanced Event-Driven System Design
Event-driven architecture is the backbone of serverless computing at scale. Every action in the system generates events that trigger downstream processes. Designing effective event flows requires careful planning to avoid circular dependencies, event duplication, or unintended cascading effects. Proper event schema design ensures that all services can interpret and process events consistently, even across different teams and development cycles.
Data Partitioning and Distributed Storage Strategies
As serverless systems scale, data partitioning becomes essential for performance and reliability. Instead of relying on a single centralized database, data is distributed across multiple partitions based on usage patterns, user segments, or geographic regions. This reduces latency and improves fault tolerance. Distributed storage systems must be carefully synchronized to maintain consistency while avoiding performance bottlenecks.
Consistency Models in Large Serverless Systems
Consistency is one of the most complex challenges in distributed serverless architectures. Systems may adopt eventual consistency, where data updates propagate gradually, or strong consistency, where all users see the same data instantly. Each model has trade-offs between performance and accuracy. Selecting the right consistency model depends on application requirements, such as financial accuracy, user experience expectations, and system responsiveness.
Advanced API Gateway Strategies
In large-scale systems, API gateways become more than simple routing layers. They act as traffic managers, security enforcers, and performance optimizers. Advanced API gateways support request transformation, response aggregation, and intelligent routing based on user context. They also integrate with authentication systems and rate-limiting mechanisms to ensure fair usage and system protection under heavy load.
Zero-Downtime Deployment Techniques
Enterprise serverless systems require continuous availability, even during updates. Zero-downtime deployment strategies ensure that new versions of functions are released without interrupting active users. This is achieved through versioning, traffic shifting, and gradual rollouts. Canary deployments allow new versions to be tested with a small percentage of traffic before full release, reducing the risk of system-wide failures.
Multi-Region Architecture for Global Applications
Global applications require deployment across multiple geographic regions to ensure low latency and high availability. Multi-region serverless architecture replicates functions and services across different cloud regions. User requests are automatically routed to the nearest region, improving performance. In case of regional failure, traffic is redirected to healthy regions, ensuring continuous service availability.
Advanced Monitoring and Distributed Tracing Systems
At enterprise scale, monitoring becomes a critical operational requirement. Distributed tracing systems track requests as they move through multiple functions and services. This allows teams to identify performance bottlenecks and failures across complex workflows. Metrics, logs, and traces are combined into unified observability platforms that provide real-time insights into system health.
AI-Driven Optimization in Serverless Systems
Artificial intelligence is increasingly used to optimize serverless performance. Machine learning models analyze usage patterns, predict traffic spikes, and adjust resource allocation dynamically. AI systems can also detect anomalies, optimize cost distribution, and recommend architectural improvements. This shift toward intelligent infrastructure reduces manual intervention and improves system efficiency over time.
Serverless for Real-Time Applications
Real-time applications such as chat systems, live dashboards, and collaborative tools benefit greatly from serverless architecture. Event-driven execution ensures immediate response to user actions. Combined with WebSocket integrations and streaming services, serverless systems can support highly interactive experiences with minimal infrastructure management.
Edge-Native Serverless Computing
Edge-native computing extends serverless execution to devices and edge nodes closer to end users. This reduces latency dramatically and improves responsiveness for time-sensitive applications. Edge functions operate in lightweight environments and are triggered by local events, enabling distributed computation without relying on centralized cloud regions.
Serverless in IoT Ecosystems
Internet of Things systems generate massive amounts of event data from connected devices. Serverless architecture is ideal for processing this data because it can scale dynamically based on input volume. Functions process sensor data, trigger alerts, and store insights in real time. This makes serverless a foundational technology for modern IoT ecosystems.
Cost Governance in Large-Scale Serverless Systems
At enterprise scale, cost management becomes a strategic priority. Organizations must track function usage, data transfer, and third-party service consumption across multiple teams. Cost governance frameworks enforce budget limits, optimize resource allocation, and prevent uncontrolled spending. Automated monitoring systems alert teams when usage exceeds predefined thresholds.
Security Architecture at Enterprise Level
Security in large serverless systems involves multiple layers of protection. Identity management systems control access to functions, APIs, and data. Network security policies restrict communication between services. Encryption ensures data protection at rest and in transit. Regular security audits and compliance checks are essential for maintaining trust and regulatory alignment.
Hybrid Cloud and Multi-Cloud Serverless Strategies
Many enterprises adopt hybrid or multi-cloud strategies to avoid vendor lock-in and increase resilience. Serverless functions may run across multiple cloud providers or combine private infrastructure with public cloud services. This distributed approach increases flexibility but also introduces complexity in coordination, monitoring, and deployment consistency.
Long-Running Workflows in Serverless Systems
Although serverless functions are typically short-lived, complex workflows may require extended execution periods. This is achieved through chaining functions together, using state machines, or breaking processes into smaller asynchronous steps. These patterns allow long-running business processes without violating serverless execution constraints.
Developer Productivity at Scale
As systems grow, developer productivity becomes a key concern. Standardized templates, reusable components, and shared libraries help teams build consistent applications faster. Automated tooling reduces repetitive tasks, while infrastructure-as-code ensures repeatable deployments. These practices allow large teams to maintain speed without sacrificing quality.
Resilience Engineering in Distributed Architectures
Resilience engineering focuses on designing systems that can recover from failures automatically. Serverless systems achieve this through redundancy, retries, and graceful degradation. Even if individual components fail, the overall system continues to function. This approach ensures high availability even under unexpected conditions.
Future of Autonomous Serverless Systems
The next evolution of serverless computing is autonomous infrastructure. Systems will automatically adjust architecture, optimize performance, and resolve failures without human intervention. This includes self-healing functions, predictive scaling, and intelligent workload distribution. Such systems will significantly reduce operational overhead and redefine cloud computing.
The Role of Serverless in Modern Computing
Serverless architecture represents one of the most significant transformations in modern software development. It removes traditional infrastructure barriers and enables developers to focus entirely on business logic and user experience. Across all parts of this discussion, serverless computing has shown its strengths in scalability, flexibility, cost efficiency, and rapid development.
At a small scale, it simplifies backend development by eliminating server management. At enterprise scale, it evolves into a powerful distributed system capable of handling massive workloads across global regions. Its event-driven nature enables real-time processing, while its modular design supports continuous innovation.
Despite these challenges, the direction of cloud computing is clearly moving toward serverless-first and serverless-hybrid systems. With advancements in edge computing, automation, and artificial intelligence, serverless platforms are becoming more powerful, intelligent, and capable of handling increasingly complex workloads. They are evolving into complete ecosystems that support everything from small mobile backends to large-scale enterprise platforms.
Conclusion
Serverless app development represents a major shift in how modern software systems are designed, built, and operated. Instead of managing servers, infrastructure, and scaling manually, developers focus entirely on writing application logic while cloud platforms handle execution, availability, and resource management automatically. This fundamental change reduces operational complexity and allows teams to build and deploy applications much faster than traditional backend approaches.
Across all aspects of serverless architecture, one clear advantage stands out: efficiency. Applications scale automatically based on demand, ensuring that resources are used only when needed. This leads to better cost control, improved performance during traffic spikes, and reduced waste of computing power. The event-driven nature of serverless systems also enables highly responsive applications that react instantly to user actions and system events.
Another key strength is flexibility. Serverless systems support modular development, where applications are broken into independent functions that can be updated, deployed, and scaled separately. This structure makes it easier to maintain large systems and encourages continuous improvement without disrupting the entire application. It also aligns well with modern development practices like microservices and agile workflows.
However, serverless computing is not without challenges. Issues such as cold starts, debugging complexity, vendor dependency, and distributed system coordination require careful architectural planning. Developers must design with statelessness, scalability, and observability in mind to fully benefit from the model. Poorly structured serverless applications can become difficult to manage if best practices are not followed.