Cloud computing has fundamentally changed how modern systems are designed, deployed, and maintained. Instead of relying on physical infrastructure owned and operated by organizations, cloud platforms such as AWS provide scalable, distributed, and highly resilient environments where applications can run with minimal downtime. In this environment, reliability is not treated as a secondary feature but as a core architectural requirement.
Two of the most important concepts used to achieve reliability in AWS architecture are high availability and fault tolerance. While both aim to ensure that systems remain operational under adverse conditions, they differ significantly in design philosophy, cost structure, and level of resilience.
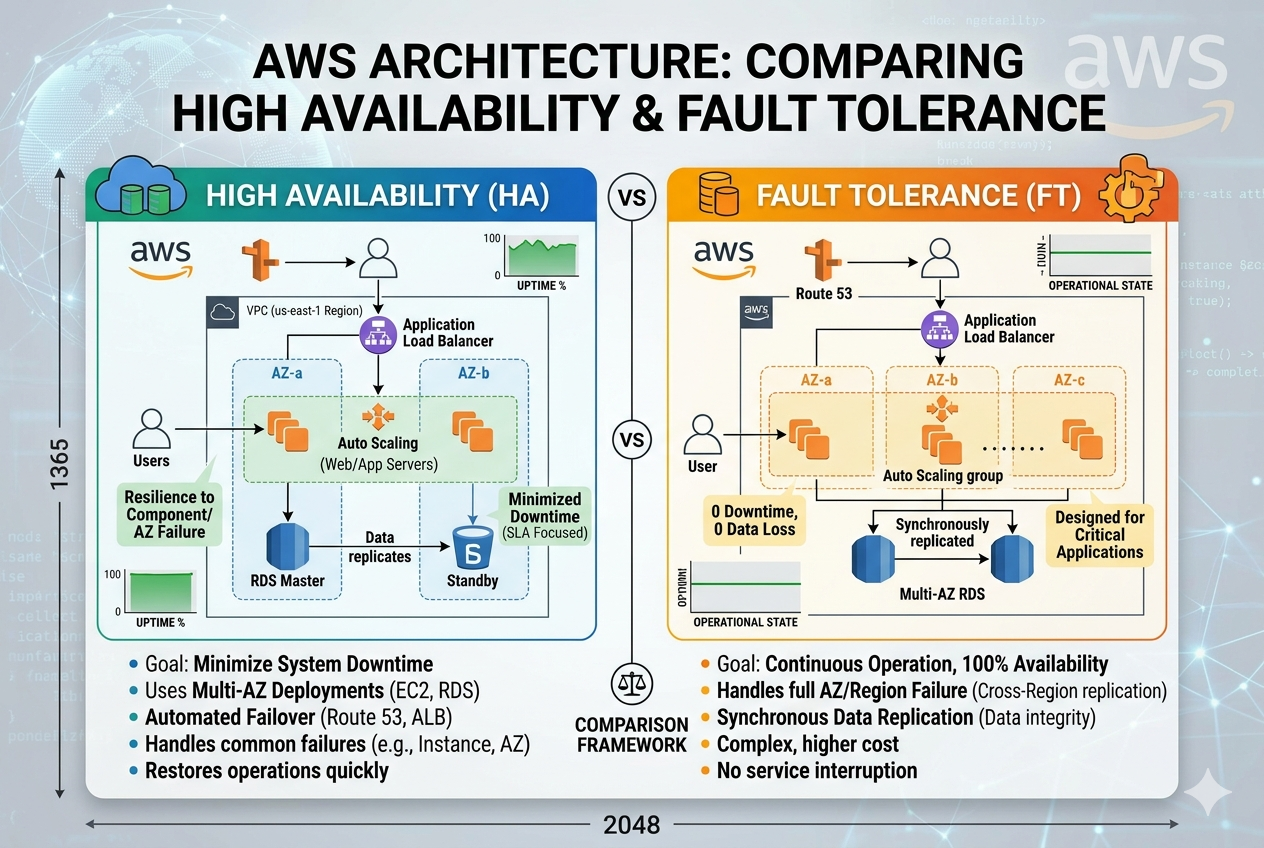
High availability focuses on reducing downtime and ensuring systems recover quickly from failures. Fault tolerance goes further by ensuring that systems continue functioning correctly even when failures occur. Understanding the distinction between these two approaches is essential for building robust cloud-native applications that meet business expectations and user demands.
AWS provides a wide range of services and architectural patterns that support both approaches. However, selecting the right model depends on workload criticality, budget constraints, and acceptable risk levels. In many real-world systems, a combination of both strategies is used to achieve a balanced architecture.
Understanding Reliability in AWS Architecture
Reliability in AWS is not achieved by preventing failures entirely but by designing systems that anticipate and handle failures gracefully. AWS operates on the principle that failures will happen at some level—whether due to hardware issues, software bugs, network disruptions, or even entire data center outages.
Because of this, AWS architecture emphasizes distributed systems where workloads are spread across multiple independent components. These components may exist within a single region or across multiple regions, depending on the level of resilience required.
Reliability is generally achieved through redundancy, automation, monitoring, and self-healing mechanisms. These principles form the foundation of both high availability and fault tolerance strategies, but they are applied differently depending on the desired outcome.
High Availability in AWS Architecture
High availability is designed to ensure that applications remain accessible for the vast majority of time, even when individual components fail. It focuses on minimizing downtime rather than eliminating it completely.
In AWS, high availability is typically achieved by distributing resources across multiple Availability Zones within a region. Each Availability Zone is physically isolated and has independent power, cooling, and networking infrastructure. This isolation ensures that a failure in one zone does not directly affect others.
When an application is designed for high availability, it is structured so that workloads can shift automatically to healthy resources in the event of failure. For example, if a server becomes unresponsive, traffic is redirected to another instance without significant disruption.
Elastic Load Balancing plays a crucial role in this model by distributing incoming traffic across multiple instances. If one instance fails health checks, it is automatically removed from the pool. Auto Scaling groups further enhance availability by replacing unhealthy instances and adjusting capacity based on demand.
Databases also contribute to high availability through replication. Services such as Amazon RDS support Multi-AZ deployments, where data is synchronously replicated to a standby instance. If the primary database fails, the standby takes over automatically.
The goal of high availability is typically expressed in uptime percentages such as 99.9% or 99.99%. While these numbers may appear close, even small differences translate into significant variations in allowable downtime over a year.
High availability is widely used in web applications, enterprise systems, and most commercial workloads where brief interruptions are acceptable but prolonged downtime is not.
Fault Tolerance in AWS Architecture
Fault tolerance represents a more advanced level of system resilience. Instead of simply recovering from failures quickly, fault-tolerant systems are designed to continue operating correctly even when failures occur.
In AWS architecture, fault tolerance is achieved by building systems that can withstand multiple simultaneous failures without impacting user experience. This often involves deploying resources across multiple Availability Zones and multiple regions.
A fault-tolerant system does not rely on failover in the traditional sense. Instead, it is designed so that failure of one component has no meaningful effect on system performance or availability.
For example, in a multi-region active-active architecture, traffic is distributed across multiple regions at the same time. If one region fails completely, the others continue serving traffic without interruption.
Fault tolerance is particularly important for mission-critical applications such as financial systems, healthcare platforms, and large-scale distributed services where downtime can result in significant operational or financial consequences.
AWS services like Amazon S3 demonstrate fault tolerance by automatically replicating data across multiple facilities. Even if multiple components fail simultaneously, data remains accessible and durable.
Similarly, distributed databases and global services are designed to maintain consistency and availability even under extreme failure conditions.
Core Differences Between High Availability and Fault Tolerance
Although both concepts aim to improve system reliability, they differ in scope and implementation.
High availability focuses on minimizing downtime through redundancy and fast recovery mechanisms. Fault tolerance focuses on eliminating downtime entirely by ensuring continuous operation during failures.
High availability systems typically experience brief interruptions during failover events. Fault-tolerant systems are designed so that users do not experience any disruption at all.
From a cost perspective, high availability is more economical and easier to implement. Fault tolerance requires significantly more resources, including duplicate infrastructure across multiple regions and complex synchronization mechanisms.
In terms of complexity, fault-tolerant systems are far more challenging to design, deploy, and maintain. They require careful planning to ensure data consistency, synchronization, and system coordination across distributed environments.
Performance impact is another differentiator. High availability systems may experience temporary performance degradation during recovery, while fault-tolerant systems are designed to maintain consistent performance under all conditions.
Architectural Foundations of High Availability
High availability in AWS is built on several fundamental architectural principles.
Redundancy is the most important principle. No single component should represent a point of failure. This includes compute resources, storage systems, and networking components.
Decoupling is another key principle. By separating system components using queues, APIs, or event-driven mechanisms, failures in one part of the system do not cascade to others.
Stateless application design also enhances high availability. When applications do not rely on local state, any instance can handle incoming requests, making failover seamless.
Automation plays a critical role. AWS continuously monitors system health and automatically replaces or reroutes traffic away from unhealthy resources.
Geographic distribution strengthens high availability by ensuring systems remain operational even if an entire Availability Zone experiences issues.
Architectural Foundations of Fault Tolerance
Fault tolerance builds on high availability principles but extends them significantly.
One of the primary foundations is full system redundancy across multiple regions. This ensures that entire geographic failures do not impact system availability.
Data replication is more advanced in fault-tolerant systems. Instead of simple backup or asynchronous replication, data is often synchronized in near real time across multiple locations.
Active-active architectures are commonly used, where multiple regions serve traffic simultaneously. This eliminates dependency on a single primary region.
Consistency management becomes critical in fault-tolerant systems. Distributed consensus mechanisms ensure that all nodes agree on system state even in the presence of failures.
Idempotent operations are also important. They ensure that repeated operations do not produce unintended effects, which is essential in distributed environments.
AWS Services Supporting High Availability and Fault Tolerance
AWS provides a wide range of services that support both reliability models.
Elastic Load Balancing ensures traffic is distributed efficiently across healthy resources. Auto Scaling automatically adjusts capacity to maintain performance and availability.
Amazon RDS and Amazon Aurora provide built-in replication and failover capabilities for relational databases, supporting high availability.
Amazon DynamoDB offers global replication and built-in fault tolerance for NoSQL workloads, making it suitable for distributed applications.
Amazon S3 is designed for extreme durability and fault tolerance, automatically storing data across multiple facilities.
Amazon Route 53 supports DNS-based routing and failover, allowing traffic to be directed to healthy regions or endpoints.
AWS Lambda abstracts infrastructure management entirely, enabling highly scalable and resilient serverless applications.
Common Deployment Patterns
Several deployment patterns are widely used in AWS architecture to implement high availability and fault tolerance.
Multi-AZ deployment is the most common high availability pattern. It ensures resources are distributed across multiple Availability Zones within a region.
Multi-region active-passive architecture is often used for disaster recovery. One region serves traffic while another remains on standby.
Multi-region active-active architecture is a fault-tolerant model where multiple regions actively serve traffic simultaneously.
Microservices architecture enhances both models by isolating system components and reducing dependencies.
Event-driven architectures further improve resilience by decoupling communication between services.
Trade-offs in Real-World Design
Designing for high availability or fault tolerance involves several trade-offs.
Cost is one of the most significant factors. Fault-tolerant systems require duplicate infrastructure across regions, making them more expensive.
Complexity increases significantly with fault-tolerant designs. They require advanced synchronization, monitoring, and operational management.
Latency considerations also play a role. Multi-region systems may introduce additional latency due to geographic distribution.
High availability systems offer a more balanced approach for most applications, providing strong reliability without excessive cost.
Fault tolerance is typically reserved for systems where downtime is unacceptable under any circumstances.
Operational Considerations
Operational excellence is critical in both high availability and fault-tolerant systems.
Monitoring and observability ensure that failures are detected early and resolved quickly. Metrics, logs, and tracing systems provide visibility into system behavior.
Automated recovery mechanisms reduce manual intervention and improve response times during failures.
Regular testing, including failure simulations, ensures that systems behave as expected under stress conditions.
Security also plays a role, as distributed systems increase the attack surface and require consistent policy enforcement.
Best Practices for AWS Reliability Design
One of the most important best practices is designing systems with failure in mind from the beginning.
Avoiding single points of failure ensures that systems remain resilient under stress.
Using managed AWS services reduces operational overhead and improves reliability.
Implementing automation for scaling and recovery improves system responsiveness.
Testing failure scenarios regularly ensures preparedness for real-world incidents.
Balancing cost and resilience ensures that systems remain economically viable while meeting reliability requirements.
Conclusion
High availability and fault tolerance are foundational principles in AWS architecture that define how systems respond to failures and maintain operational continuity.
High availability focuses on minimizing downtime through redundancy, automation, and rapid recovery. It is suitable for most applications where brief interruptions are acceptable.
Fault tolerance goes further by ensuring continuous operation even in the presence of failures, making it essential for mission-critical systems where downtime is unacceptable.
AWS provides a comprehensive set of tools and architectural patterns that support both approaches. The choice between them depends on business requirements, risk tolerance, and cost considerations.
In practice, many real-world systems combine both strategies to achieve a balanced architecture that is resilient, scalable, and cost-effective. By understanding and applying these principles correctly, architects can design cloud systems that meet modern reliability expectations while remaining efficient and adaptable in a constantly evolving digital environment.