The traceroute command in Linux is a powerful network diagnostic utility that helps users understand how data travels across networks from one system to another. It maps the complete route that packets follow when moving toward a destination, revealing every intermediate device involved in the communication. This makes it an essential tool for analyzing network performance, identifying delays, and troubleshooting connectivity problems.
Understanding the Basic Idea Behind Traceroute
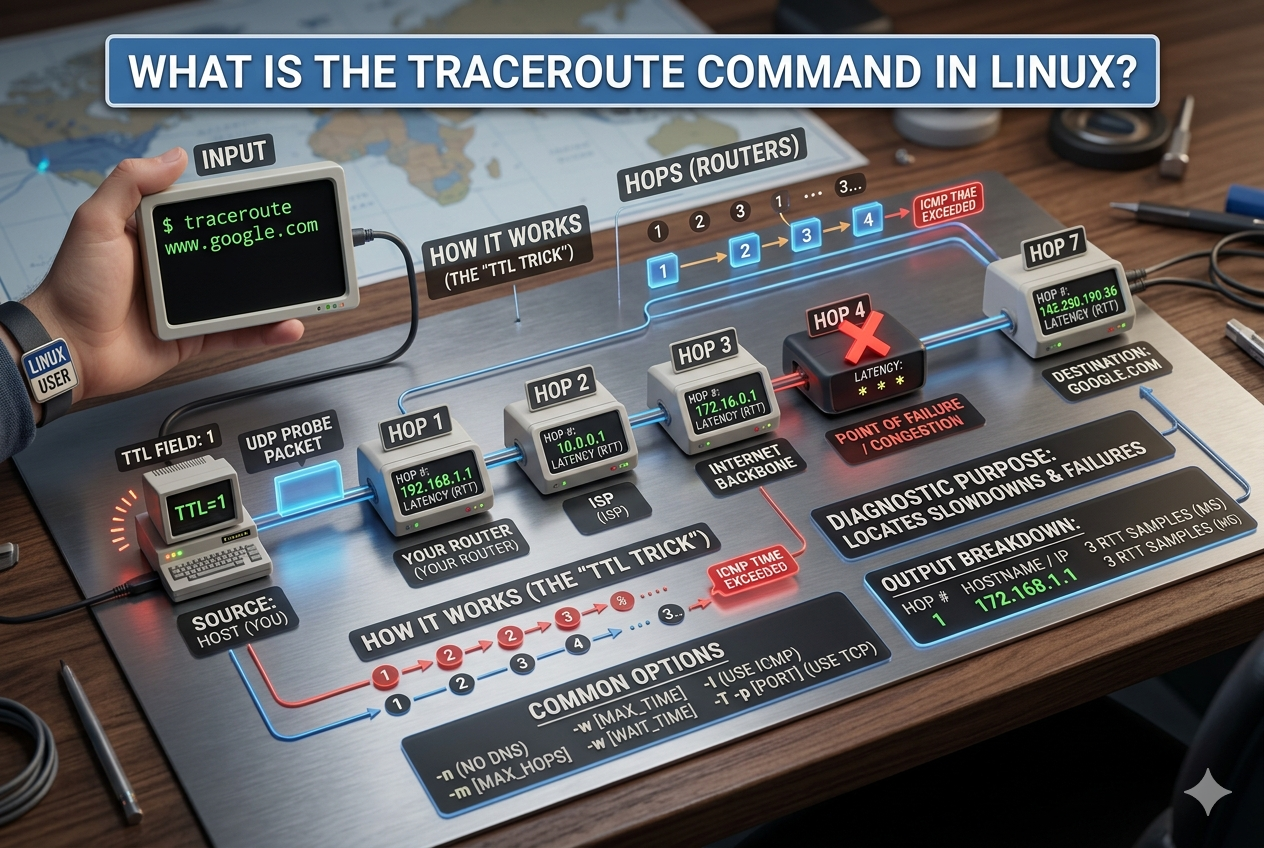
At its core, traceroute is built on a simple but effective principle: every data packet sent over a network has a limited lifespan. This lifespan is controlled by a value known as Time To Live. Instead of allowing packets to travel indefinitely, this value ensures they are discarded after passing through a certain number of network devices. Each time a packet passes through a router, the value decreases by one. When it reaches zero, the packet is dropped, and the router sends a message back to the sender. This mechanism allows traceroute to discover each step along the path.
By gradually increasing this limit, traceroute is able to uncover every hop between the source and destination. It starts by sending a packet with a very small limit so that it expires at the first router. Then it increases the limit step by step, revealing the next router each time. This continues until the destination is reached, creating a full map of the route.
How Traceroute Reveals Network Paths
When a traceroute command is executed, it sends multiple packets toward the target system. Each packet is intentionally set to expire at a different stage in the journey. When a router drops a packet due to expiration, it responds with a notification message. This response includes information about the router itself and how long it took for the packet to reach it.
By collecting these responses, traceroute builds a sequential list of all routers involved in the connection. Each entry represents a single hop in the network path. This sequence provides a visual representation of how data travels across the internet or internal networks.
The process continues until the final destination responds, confirming that the path is complete. If the destination does not respond, traceroute will still display all the intermediate hops, which can help identify where the failure occurs.
Why Traceroute is Important in Linux Systems
In Linux environments, traceroute plays a critical role in network troubleshooting and performance monitoring. System administrators rely on it to diagnose issues such as slow connections, packet loss, or unreachable servers. By showing each hop along the path, it becomes easier to pinpoint where delays or interruptions are happening.
For example, if a connection to a remote server is slow, traceroute can reveal whether the delay is occurring within the local network, at an internet service provider level, or somewhere closer to the destination. This level of visibility is essential for resolving complex network problems.
Traceroute is also useful for verifying routing behavior. Sometimes data does not take the most direct path to its destination due to network policies or congestion. Traceroute helps reveal these indirect routes, allowing administrators to understand and optimize traffic flow.
The Role of Time To Live in Traceroute
Time To Live is the fundamental mechanism that makes traceroute possible. It is a numerical value assigned to each packet that determines how many hops it can pass through before being discarded. Without this system, packets could circulate indefinitely in the network, causing congestion.
In traceroute, this value is deliberately manipulated. The command starts by setting the value to one, meaning the packet will expire at the first router. After receiving a response, traceroute increases the value to two, then three, and so on. Each increment reveals the next hop in the chain.
This controlled expiration process allows traceroute to systematically explore the entire route to the destination without needing direct cooperation from every router.
Different Types of Traceroute Implementations in Linux
Linux systems often provide multiple variations of traceroute depending on the configuration and installed utilities. Some versions use different types of packets to perform the tracing process. The most common approach uses internet control messages, while others may use user datagram packets or transmission control packets.
Each method has slightly different behavior depending on how network devices handle incoming traffic. Some routers may respond more reliably to certain types of packets, which can affect the completeness of the results. Because of this, different traceroute modes can be useful in different environments.
Despite these variations, the core principle remains the same: gradually increasing packet lifespan to discover each hop in the route.
Interpreting Traceroute Results in Detail
When traceroute displays its results, each line represents a single hop in the network path. These lines typically include the hop number, the address of the router, and the response time measured in milliseconds. Multiple response times may be shown for each hop because traceroute often sends more than one packet to ensure accuracy.
Lower response times generally indicate faster communication between devices, while higher values suggest delays. If a particular hop shows unusually high response times compared to others, it may indicate congestion or processing delays at that point in the network.
Sometimes, asterisks appear in the output instead of response times. This usually means that a router did not respond within the expected time. This can happen due to firewall settings, network filtering, or high traffic loads. While a missing response does not always indicate a problem, repeated failures at the same hop may suggest an issue.
Practical Use Cases of Traceroute in Linux
Traceroute is widely used in real world networking scenarios. One of its most common uses is diagnosing internet connectivity problems. When a website fails to load or responds slowly, traceroute helps determine whether the issue is local or external.
It is also used for performance optimization. Network engineers analyze traceroute results to identify inefficient routing paths. By understanding how data travels, they can make decisions to improve speed and reliability.
Another important use is in server monitoring. Organizations that manage multiple servers across different regions use traceroute to ensure that data is being routed efficiently between locations.
Traceroute is also valuable in security analysis. Unusual routing paths or unexpected hops can sometimes indicate misconfigurations or unauthorized network changes.
Limitations and Challenges of Traceroute
Although traceroute is a powerful tool, it does have limitations. One of the main challenges is that not all routers respond to traceroute requests. Some devices are configured to ignore these packets for security or performance reasons. This can lead to incomplete or misleading results.
Another limitation is that network paths are not always stable. The route taken by data can change dynamically based on traffic conditions, load balancing, or network policies. This means that repeated traceroute tests may produce different results even for the same destination.
Traceroute also measures the time taken for packets to reach each hop, but these values can be affected by temporary congestion or processing delays. As a result, response times should be interpreted carefully and not as absolute performance indicators.
Security Considerations Related to Traceroute
Because traceroute reveals information about network structure, some systems restrict or block its usage. Exposing internal routing paths can provide insights into network design, which may be useful to attackers. For this reason, firewalls and security policies sometimes limit traceroute responses.
Despite this, traceroute remains widely used because its benefits in troubleshooting and diagnostics outweigh potential risks. In secure environments, administrators often balance visibility and protection by controlling which devices respond to traceroute requests.
Importance of Traceroute in Network Troubleshooting
Traceroute is one of the most valuable tools for diagnosing network issues because it provides step by step visibility into data movement. Instead of guessing where a problem occurs, administrators can observe exactly where delays or failures happen.
It eliminates much of the uncertainty involved in network troubleshooting. Whether dealing with slow applications, unreachable services, or inconsistent performance, traceroute offers a structured way to analyze the problem.
By combining traceroute with other diagnostic tools, a complete picture of network health can be developed, allowing for more effective problem solving and optimization.
Traceroute Behavior in Different Network Conditions
The behavior of traceroute can change significantly depending on the condition of the network it is analyzing. In a stable and well-optimized network, the results usually appear smooth, with consistent response times and clearly defined hops. Each router responds quickly, and the path remains predictable. However, in real-world networks, conditions are rarely perfect, and traceroute often reveals variations that help explain performance issues.
When a network is under heavy load, response times at certain hops may increase noticeably. This happens because routers prioritize handling actual data traffic over responding to diagnostic requests. As a result, traceroute packets may experience slight delays, which appear in the output as higher latency values. These variations are not always problems themselves but can indicate congestion points that deserve further analysis.
In unstable network environments, traceroute may show inconsistent results across repeated runs. A packet might take one route during one test and a slightly different route during another. This is common in large-scale networks where load balancing systems distribute traffic dynamically. Traceroute captures these changes, helping users understand that routing is not always fixed.
How Packet Loss Appears in Traceroute
Packet loss is one of the most important issues traceroute can help identify. When a router fails to respond to traceroute packets, it may indicate that packets are being dropped or that responses are being blocked. In the output, this often appears as missing response times or symbols indicating no reply.
However, it is important to understand that packet loss shown in traceroute does not always mean actual data loss is occurring. Some routers are configured not to respond to diagnostic requests while still forwarding traffic normally. This means that while traceroute shows gaps, the network may still be functioning correctly for real applications.
To accurately interpret packet loss, it is necessary to observe patterns across multiple hops. If only one intermediate router shows missing responses but later hops respond normally, it is usually not a serious issue. However, if packet loss continues across multiple consecutive hops, it may indicate a deeper network problem.
Traceroute and Network Latency Analysis
Latency is the time it takes for a packet to travel from one point to another in a network. Traceroute is widely used to measure and analyze latency at each stage of the route. By displaying response times for every hop, it helps identify where delays are introduced.
In a well-performing network, latency increases gradually as packets move further from the source. Sudden spikes in latency at a specific hop can indicate congestion, routing inefficiencies, or hardware limitations. These spikes are especially important for diagnosing performance issues in applications that require real-time communication, such as video calls or online gaming.
Traceroute does not measure exact application performance but provides a strong indication of where delays might be occurring. This makes it a valuable tool for performance tuning and network optimization.
Differences Between Traceroute and Other Network Tools
Traceroute is often compared with other network diagnostic tools, but it has a unique role. While tools like ping only check connectivity and overall response time to a single destination, traceroute breaks down the entire path into individual segments. This gives a more detailed view of how data moves through the network.
Unlike simple connectivity tests, traceroute reveals the structure of the network path itself. It shows every intermediate device involved in the communication process, which is something basic tools cannot provide. This makes it more suitable for advanced troubleshooting.
However, traceroute is not designed for real-time monitoring or continuous performance measurement. Instead, it is best used as a snapshot tool that provides insight at a specific moment in time. For ongoing monitoring, other specialized tools are typically used alongside it.
Role of Routing in Traceroute Results
Routing plays a major role in determining the results displayed by traceroute. Every network packet must pass through multiple routers before reaching its destination, and each router makes decisions based on routing tables. These decisions influence the exact path that traceroute reveals.
In some cases, routing policies may cause data to take longer or indirect paths. This is often due to traffic balancing or network optimization strategies used by internet service providers. Traceroute makes these hidden paths visible, helping users understand why data does not always travel in a straight line.
Routing changes can also occur dynamically. If a router becomes unavailable or overloaded, traffic may be redirected through alternative paths. Traceroute captures these changes, which is why repeated tests may show different routes.
Understanding Time Variations Across Hops
One of the most noticeable aspects of traceroute output is the variation in response times between hops. These differences are influenced by many factors, including physical distance, network congestion, and processing speed of routers.
Early hops in a traceroute are usually located closer to the source and tend to have lower response times. As packets move further away, latency may gradually increase due to longer distances and additional network processing. However, sudden or irregular jumps in time can indicate potential issues.
It is also common to see fluctuations between multiple responses from the same hop. Since traceroute often sends more than one packet per hop, each response may vary slightly depending on network conditions at that moment. These variations are normal and should be interpreted as part of natural network behavior.
Traceroute in Local and Wide Area Networks
Traceroute behaves differently depending on whether it is used within a local network or across the internet. In a local network, the number of hops is usually small, and response times are extremely low. This makes troubleshooting within internal systems relatively straightforward.
In wide area networks, however, the path can include many routers spread across different regions and service providers. This increases complexity and makes traceroute especially useful. It allows users to see exactly how far data travels and which external networks are involved.
When used across global networks, traceroute can reveal international routing paths, showing how data may travel through multiple countries before reaching its destination. This level of visibility is important for understanding global internet performance.
Impact of Firewalls and Security Filters on Traceroute
Modern networks often use firewalls and security filters to control traffic. These systems can affect how traceroute behaves. Some firewalls are configured to block traceroute packets completely, while others allow them but do not send responses.
When this happens, traceroute may show incomplete paths or missing hops. However, this does not necessarily indicate a failure in the network. It may simply be a security measure designed to protect internal infrastructure.
In some cases, only specific types of traceroute packets are blocked. This means switching to a different mode of traceroute may produce better results. Understanding how security systems interact with traceroute is important for accurate interpretation.
Real World Importance of Traceroute in Troubleshooting
Traceroute is widely used in real-world network troubleshooting because it simplifies complex problems. Instead of analyzing the entire network manually, administrators can quickly identify where communication is slowing down or failing.
For example, if a website hosted on a remote server becomes slow, traceroute can show whether the delay is happening near the user’s network, within an internet provider’s infrastructure, or close to the server itself. This helps narrow down the source of the problem efficiently.
It is also useful for verifying network changes. After updating network configurations or changing service providers, traceroute helps confirm whether the new routing paths are working as expected.
Limitations in Real-Time Interpretation
While traceroute provides valuable insights, it is important to understand that it represents network behavior at a specific moment in time. Network conditions can change quickly, so results may not always reflect ongoing performance.
Another limitation is that traceroute does not measure application-level performance. It only shows network-level routing and latency. Applications may still perform differently depending on factors such as server load or internal processing delays.
Because of these limitations, traceroute is most effective when used alongside other diagnostic tools. Together, they provide a more complete understanding of network behavior and performance patterns.
Advanced Interpretation of Traceroute Output
Understanding traceroute at a deeper level requires more than just reading hop numbers and response times. Each line in the output represents not only a network device but also a small snapshot of how that device interacts with diagnostic traffic at a specific moment. In advanced analysis, the focus shifts from simply identifying the route to interpreting patterns, inconsistencies, and subtle indicators of network health.
One important aspect is recognizing the difference between consistent latency and fluctuating latency. Consistent latency across hops usually indicates a stable network path. Even if the delay is slightly higher in some regions, stability suggests that routing is predictable and there are no major bottlenecks. On the other hand, irregular fluctuations can indicate dynamic routing behavior, congestion, or overloaded infrastructure.
Another advanced interpretation technique involves identifying latency accumulation patterns. If each hop gradually increases in response time in a smooth and predictable way, the network is likely operating normally. However, if a single hop introduces a sudden spike that persists in all subsequent hops, it often suggests that the issue originates at or before that router.
Understanding Hidden or Silent Hops
In many traceroute outputs, some hops may not display any response. These are often referred to as silent or hidden hops. A silent hop does not necessarily mean the device is inactive or failing. Instead, it usually means that the router is configured not to respond to diagnostic packets.
This behavior is common in enterprise networks and secure infrastructure environments where administrators limit visibility for security reasons. Even though these hops do not respond, they still forward packets correctly. As a result, the overall network path remains intact even if part of it is not visible in traceroute output.
Interpreting silent hops requires context. If a silent hop appears in the middle of an otherwise functioning path, it is typically not a concern. However, if silence is followed by a complete failure to reach the destination, it may indicate a routing or connectivity issue beyond that point.
Dynamic Routing and Its Effect on Traceroute Results
Modern networks rely heavily on dynamic routing systems that automatically adjust paths based on traffic conditions, link availability, and network policies. These systems constantly evaluate the best possible route for data transmission.
Because of this dynamic behavior, traceroute results are not always identical between runs. A packet may take one route during one test and a different route during another. This is not an error but a reflection of how adaptive routing systems operate.
In large-scale networks, this behavior is especially common. Internet service providers often use load balancing techniques to distribute traffic across multiple paths. Traceroute captures these variations, which can sometimes make the output appear inconsistent even when the network is functioning normally.
Understanding dynamic routing is essential when interpreting traceroute results because it helps distinguish between actual network problems and expected routing behavior.
Identifying Network Bottlenecks Through Traceroute
One of the most valuable uses of traceroute is identifying bottlenecks within a network. A bottleneck occurs when a particular router or link becomes overloaded, causing delays for all traffic passing through it.
In traceroute output, bottlenecks often appear as sudden increases in response time at a specific hop. If this delay continues for all subsequent hops, it suggests that the congestion is occurring early in the route and affecting the entire path.
However, if the delay is isolated to a single hop and subsequent hops return to normal timing, it may indicate that the router is simply deprioritizing diagnostic traffic rather than experiencing actual congestion. This distinction is important for accurate diagnosis.
By analyzing these patterns, network administrators can pinpoint weak points in infrastructure and take corrective actions such as rerouting traffic or upgrading hardware.
Traceroute in Complex Multi Network Environments
In complex environments involving multiple interconnected networks, traceroute becomes even more useful. Data traveling across the internet often passes through several independent networks, each managed by different organizations.
Traceroute helps visualize how these networks connect and interact. It reveals the boundaries between local networks, regional providers, and global backbone systems. This visibility is crucial for understanding performance differences across different segments of the internet.
In such environments, delays may not always be caused by a single network. Instead, they can result from interactions between multiple systems. Traceroute helps isolate which segment contributes most to latency, allowing for more targeted troubleshooting.
The Role of Reverse Path Behavior in Traceroute
Traceroute relies on responses from routers to map the path, but it does not always guarantee that the return path follows the same route. The path taken by response messages may differ from the path taken by outgoing packets.
This difference can sometimes lead to confusion when interpreting results. For example, a packet may travel through one set of routers to reach its destination, but the response may return through a completely different set of routers. Traceroute still records the outgoing path based on responses received, but it does not fully represent bidirectional traffic flow.
Understanding this limitation is important when analyzing performance issues, especially in networks where routing is asymmetrical.
Traceroute and Time Sensitivity in Measurements
Time measurements in traceroute are highly sensitive to network conditions at the moment of testing. Even small changes in traffic load can affect response times. Because of this, traceroute results should be viewed as temporary snapshots rather than fixed values.
When performing multiple traceroute tests over time, patterns become more meaningful than individual results. Repeated observations can reveal whether delays are consistent, improving, or worsening.
This time sensitivity also means that traceroute is best used in combination with long-term monitoring tools when precise performance tracking is required.
Understanding Protocol Behavior in Traceroute
Traceroute can operate using different communication protocols, and each protocol interacts differently with network devices. Some protocols may be prioritized by routers, while others may be treated as low priority or filtered entirely.
This variation can affect the completeness of traceroute results. In some cases, switching the underlying protocol can produce more accurate or more detailed paths. This flexibility allows traceroute to adapt to different network environments.
However, regardless of protocol differences, the fundamental principle remains unchanged: gradually increasing packet lifetime to map each hop.
Security Implications of Traceroute Visibility
While traceroute is extremely useful for diagnostics, it also exposes information about network structure. This includes the number of intermediate devices, their relative positions, and sometimes even their addresses.
Because of this, some organizations restrict traceroute responses to reduce exposure of internal infrastructure. Limiting visibility helps reduce the risk of network mapping by unauthorized users.
Despite these restrictions, traceroute remains widely accessible because its diagnostic value is essential for maintaining network health. Administrators often strike a balance between visibility and security by selectively controlling which systems respond.
Practical Scenarios Where Traceroute Provides Critical Insight
Traceroute is especially valuable in scenarios where network performance issues are difficult to diagnose using basic tools. For example, when a web application loads slowly for users in one region but not another, traceroute can reveal whether the delay is caused by regional routing differences.
It is also useful when services become intermittently unreachable. By analyzing multiple traceroute outputs over time, administrators can detect unstable routes or fluctuating network paths.
Another practical scenario involves verifying service provider performance. Organizations often use traceroute to ensure that their internet providers are delivering consistent and efficient routing.
Limitations in Highly Encrypted or Filtered Networks
In modern networks that use extensive encryption or filtering, traceroute may have reduced visibility. Some security systems are designed to obscure internal routing details completely, which limits the amount of information traceroute can gather.
In such cases, traceroute may show partial paths or only the initial segments of the route. While this can reduce diagnostic accuracy, it is often a deliberate design choice to improve security.
Even with these limitations, traceroute still provides valuable insight into the visible portions of the network and can help narrow down the location of issues.
Overall Significance of Traceroute in Network Analysis
Traceroute remains one of the most important tools in network diagnostics due to its ability to reveal the structure and behavior of data transmission paths. It transforms invisible network activity into a visible sequence of steps that can be analyzed and understood.
By providing insight into routing paths, latency, and potential points of failure, traceroute helps users and administrators make informed decisions about network optimization and troubleshooting. Its simplicity in concept combined with depth of information makes it a foundational tool in Linux networking environments.
Traceroute in Modern Linux Systems and Evolving Networks
In modern Linux systems, traceroute continues to remain an essential diagnostic tool, even as networking technologies become more advanced and complex. With the rise of cloud computing, virtual networks, and software-defined networking, the way data travels has become more dynamic than ever before. Despite these changes, traceroute still provides a reliable way to observe and understand network behavior at a practical level.
Modern networks often involve virtualized routing layers where physical infrastructure is abstracted behind software systems. In such environments, traceroute may show hops that represent virtual routers rather than physical devices. This makes interpretation slightly more complex, but the underlying principle of mapping each step in the data path remains unchanged.
Even in containerized environments and cloud-based infrastructures, traceroute is widely used to debug connectivity issues between services. It helps developers and administrators verify whether network policies, virtual firewalls, or routing configurations are affecting communication between systems.
Traceroute in Cloud and Virtualized Environments
In cloud environments, network paths are not always tied to physical geography in the traditional sense. Instead, data may pass through virtual networks that are dynamically managed by cloud platforms. Traceroute in these environments may show hops that represent internal routing systems rather than traditional hardware routers.
This can sometimes make the output appear less intuitive. For example, multiple hops may appear within a single provider’s infrastructure without clearly indicating physical separation. However, these hops are still meaningful because they represent logical transitions in the network.
In virtualized systems, traceroute is often used to confirm that services deployed in different virtual networks can communicate properly. It helps ensure that routing rules, security groups, and virtual network configurations are correctly set up.
Impact of Load Balancing on Traceroute Accuracy
Load balancing is a common technique used in modern networks to distribute traffic across multiple paths or servers. While this improves performance and reliability, it can affect traceroute results in noticeable ways.
Because load balancing may send packets through different routes, repeated traceroute tests may show varying paths to the same destination. This is expected behavior in modern infrastructure. Each run of traceroute might reveal a slightly different sequence of hops depending on how traffic is distributed at that moment.
This variation does not indicate instability. Instead, it reflects the flexibility and redundancy built into modern networks. Understanding this behavior is important when analyzing traceroute results in environments that use advanced traffic management systems.
Traceroute and Internet Backbone Networks
Internet backbone networks form the core infrastructure that connects different regions and service providers across the world. Traceroute often passes through these backbone systems when tracing routes over long distances.
In such cases, traceroute can reveal how data travels between major network hubs. These hops typically represent high-capacity routers designed to handle large volumes of traffic. Because these systems prioritize performance and efficiency, they may not always respond to traceroute requests consistently.
Even when responses are limited, traceroute still provides useful information about the overall structure of the route. It helps illustrate how data moves between regional networks and global infrastructure layers.
Understanding Asymmetric Routing in Traceroute Results
Asymmetric routing occurs when data takes one path to reach a destination and returns through a different path. This is a common behavior in large and complex networks where multiple routing options exist.
Traceroute primarily shows the outbound path, meaning the route taken from the source to the destination. It does not always reflect the return path. Because of this, users may notice differences when comparing traceroute results with other network observations.
Asymmetric routing can sometimes lead to confusion during troubleshooting. For example, a slow response might appear to originate from one segment of the network, even though the actual issue is on the return path. Understanding this concept is essential for accurate interpretation of traceroute data.
Traceroute and DNS Resolution Effects
In many traceroute outputs, domain names may appear alongside IP addresses. These names are resolved using DNS systems. While this can make results easier to understand, it also introduces an additional layer of complexity.
DNS resolution can sometimes slow down traceroute output or introduce temporary inconsistencies if name servers are slow to respond. In some cases, traceroute may skip name resolution entirely and display only numeric addresses for faster execution.
The presence or absence of DNS resolution does not affect the accuracy of the routing path itself. It only influences how the information is presented to the user.
Latency Spikes and Their Real Meaning in Traceroute
Latency spikes in traceroute are often misinterpreted as serious network problems, but their meaning depends on context. A single spike at one hop does not always indicate a fault. It may simply reflect how that router handles diagnostic traffic.
Some network devices deprioritize traceroute packets to focus on forwarding real user traffic. As a result, they may respond slowly even though actual data flows through them efficiently. This is why it is important to observe whether the delay continues in subsequent hops.
If latency returns to normal after a spike, the issue is usually not critical. However, if the delay persists across multiple hops, it is more likely to represent a genuine network bottleneck.
Using Traceroute for Performance Benchmarking
Traceroute is not only a troubleshooting tool but also a useful method for performance benchmarking. By running traceroute at different times of the day, administrators can observe how network performance changes under different traffic conditions.
These observations can help identify peak usage periods, congestion trends, and long-term performance issues. When combined with historical data, traceroute results can provide insights into network stability over time.
Benchmarking with traceroute is particularly useful for services that depend on consistent latency, such as online applications, gaming platforms, and real-time communication systems.
Troubleshooting Complex Connectivity Issues with Traceroute
In complex networking scenarios, connectivity issues are rarely caused by a single point of failure. Instead, they often result from multiple interacting factors. Traceroute helps break down this complexity by showing each step in the communication chain.
When a destination is unreachable, traceroute can reveal where the connection stops. This allows administrators to determine whether the issue lies within the local network, an intermediate provider, or the destination network itself.
By narrowing down the failure point, troubleshooting becomes more efficient and targeted. Instead of examining the entire network, attention can be focused on the specific segment where the problem occurs.
The Role of ICMP Filtering in Traceroute Behavior
Many traceroute implementations rely on a specific type of network message to receive responses from routers. However, some networks filter these messages for security or performance reasons. This practice is known as ICMP filtering.
When ICMP filtering is in place, traceroute may show incomplete or missing responses. This does not necessarily mean that the network path is broken. It simply means that certain diagnostic messages are being blocked or ignored.
In such cases, traceroute may still successfully reach the destination, but intermediate hops may not be visible. Understanding this limitation is important when interpreting partial traceroute results.
Traceroute as a Learning Tool for Networking Concepts
Beyond its practical use, traceroute is also an excellent educational tool for understanding how networks operate. It visually demonstrates concepts such as routing, packet transmission, latency, and network topology.
By observing traceroute outputs, learners can gain a clearer understanding of how data moves across complex systems. It transforms abstract networking concepts into visible, step-by-step processes.
This makes traceroute particularly valuable in academic and training environments where understanding real-world network behavior is important.
Long Term Value of Traceroute in Network Management
Despite advancements in networking technology, traceroute continues to hold long-term value in system administration and network engineering. Its simplicity, combined with its ability to reveal detailed routing paths, makes it a timeless diagnostic tool.
As networks continue to evolve, traceroute adapts by remaining relevant in both traditional and modern infrastructures. Whether used in local systems, global internet environments, or cloud-based architectures, it consistently provides meaningful insight into how data travels.
Its role in identifying delays, mapping routes, and supporting troubleshooting ensures that it remains a foundational component of Linux networking tools.
Conclusion
Traceroute in Linux is a fundamental network diagnostic tool that helps uncover the complete path data follows from a source system to a destination. By revealing each intermediate hop, it provides clear visibility into how networks are structured and how data is routed across them. This makes it especially useful for understanding connectivity behavior in both simple and highly complex network environments.
Throughout its operation, traceroute relies on controlled packet expiration to map each step in the communication path. This simple yet powerful mechanism allows users to detect delays, identify routing inefficiencies, and locate potential points of failure. It transforms an invisible process into a structured and understandable sequence of network transitions.
In practical use, traceroute plays a major role in troubleshooting performance issues, diagnosing connectivity problems, and analyzing network latency. It helps distinguish between local network issues and external routing problems, making it easier to pinpoint the true source of disruptions. Even when networks become more advanced with virtualization, load balancing, and dynamic routing, traceroute continues to provide meaningful insights.
Although it has limitations such as incomplete responses, variable results, and dependency on network configurations, its value remains strong. It is most effective when interpreted carefully and used alongside other diagnostic tools. Rather than providing absolute answers, traceroute offers a detailed view of network behavior at a specific moment in time.
Overall, traceroute remains one of the most important and widely used tools in Linux networking. Its ability to simplify complex routing information into a readable format makes it essential for administrators, engineers, and learners who want to understand how data moves across networks and how performance issues can be identified and resolved.