Virtualization has become one of the most important technologies in modern IT infrastructure. It allows organizations to maximize hardware utilization by running multiple virtual machines on a single physical server. Instead of dedicating one server to one operating system or workload, virtualization makes it possible to divide a physical machine into multiple isolated environments, each functioning as if it were an independent server.
This flexibility improves efficiency, reduces hardware costs, lowers power consumption, simplifies management, and enables faster deployment of workloads. Businesses of all sizes rely on virtualization to support applications, databases, development environments, testing labs, and cloud infrastructure.
One of the key resources that virtualization manages is memory. Every virtual machine requires memory to operate. The guest operating system uses memory to load applications, process tasks, maintain caches, and handle active workloads. Without sufficient memory, virtual machines slow down or fail to perform efficiently.
Physical servers have limited RAM installed. If a host contains 128 GB of physical memory, it cannot physically provide more than that amount at any one time. However, virtualization platforms often allow administrators to allocate more memory to virtual machines than physically exists on the server. This is called memory overcommitment.
Memory overcommitment works because most virtual machines rarely use all their assigned memory at the same time. A machine configured with 16 GB may only actively use 6 GB for much of the day. Another machine assigned 8 GB may only need 3 GB. The hypervisor uses this behavior to allocate memory dynamically, assuming not every machine will demand its full allocation simultaneously.
This strategy significantly improves hardware utilization and enables higher consolidation ratios. Organizations can host more workloads on fewer physical servers, reducing infrastructure costs while maintaining flexibility.
However, memory overcommitment introduces challenges.
When several virtual machines suddenly demand more memory at the same time, the physical host may not have enough RAM available. If unmanaged, this could result in severe performance degradation or resource contention.
To solve this problem, virtualization platforms use intelligent memory management systems.
These systems monitor host memory usage continuously and apply various reclamation techniques when memory pressure occurs. Their purpose is to recover unused memory from virtual machines and redistribute it to workloads that need it more urgently.
Memory ballooning is one of the most important and widely used of these memory reclamation techniques.
It provides a mostly non-disruptive way for the hypervisor to reclaim unused memory from guest operating systems while maintaining workload performance.
To fully understand ballooning, it is important to first understand how memory management works inside a virtualized environment.
A hypervisor acts as the layer between physical hardware and virtual machines. It manages CPU scheduling, storage access, networking, and memory allocation for all workloads running on the host.
The hypervisor creates the illusion that each virtual machine has dedicated hardware resources, even though those resources are shared among many workloads.
Memory management is particularly complex because each guest operating system believes it owns the full amount of RAM assigned to it.
A virtual machine configured with 16 GB behaves as though it physically has 16 GB available. It manages memory internally, allocates it to applications, stores cached data, and tracks usage independently.
The hypervisor must coordinate these independent memory environments while ensuring fair and efficient distribution of physical RAM.
When physical memory becomes constrained, the hypervisor cannot simply remove memory from a guest arbitrarily. Doing so would risk corruption or system instability.
Instead, it relies on carefully designed memory reclamation technologies.
These mechanisms work in stages, starting with the least disruptive methods and escalating only when necessary.
This tiered approach minimizes performance impact while maintaining host stability.
The first and least disruptive method is transparent page sharing.
Transparent page sharing identifies identical memory pages and consolidates them.
Many virtual machines running the same operating system contain duplicate memory structures. System libraries, kernel components, and common processes often produce identical memory patterns.
Instead of storing separate copies of these pages for every virtual machine, the hypervisor stores one copy and maps multiple machines to it.
This reduces total physical memory consumption without affecting workload performance.
Transparent page sharing works silently in the background and generally has no noticeable impact on virtual machines.
It is highly efficient in environments where many machines run similar operating systems or applications.
Modern security practices have limited some forms of inter-virtual-machine sharing, but the technology remains valuable for reclaiming duplicate memory within workloads.
When page sharing cannot free enough memory, the hypervisor activates memory ballooning.
Ballooning works differently because it involves cooperation between the hypervisor and guest operating systems.
This process requires virtualization tools to be installed inside each virtual machine.
These tools include a balloon driver, which acts as a communication channel between the hypervisor and the guest.
When host memory becomes constrained, the hypervisor signals the balloon driver to inflate.
The driver responds by requesting memory from the guest operating system.
From the guest’s perspective, this appears as though a process inside the virtual machine suddenly needs large amounts of RAM.
The operating system allocates memory to satisfy this request.
To do so, it releases unused caches, discards inactive pages, or reorganizes memory internally.
The hypervisor then reclaims the physical memory associated with those released pages.
This reclaimed memory becomes available for redistribution to other virtual machines that need it more urgently.
The brilliance of ballooning lies in the fact that the guest operating system decides which memory to release.
Because the guest has direct knowledge of which pages are least important, it can free memory intelligently.
This greatly reduces the likelihood of reclaiming actively used data.
As a result, ballooning is usually non-disruptive or only minimally disruptive.
Applications often continue running normally without users noticing any impact.
This makes ballooning one of the safest and most effective memory reclamation strategies available.
It allows virtualization platforms to overcommit memory aggressively while maintaining stability.
However, ballooning is not intended as a permanent operating condition.
Frequent ballooning indicates memory pressure on the host.
Occasional ballooning during temporary workload spikes is normal.
Constant ballooning suggests the environment is under-provisioned.
This may indicate too many virtual machines are running on the host or that memory allocations are oversized.
Administrators should investigate recurring balloon activity and consider adjustments.
These may include increasing host RAM, migrating workloads, rightsizing virtual machines, or balancing workloads across clusters.
Ballooning is a warning sign that memory resources are becoming constrained.
It provides administrators with an opportunity to act before more disruptive memory reclamation methods are required.
If ballooning cannot recover enough memory, the hypervisor escalates to memory compression.
Compression reduces the size of memory pages so more data can fit into physical RAM.
Compressed pages remain in memory rather than being written to disk.
This makes access faster than swapping, though slower than normal memory access.
Compression introduces CPU overhead because pages must be compressed and decompressed.
While generally less harmful than swapping, compression can still affect performance under sustained pressure.
If memory pressure continues to increase, the hypervisor eventually uses swapping.
Swapping writes memory pages to disk-based swap files.
This frees physical RAM but significantly reduces performance.
Disk access is far slower than memory access.
Applications depending on swapped pages may experience severe latency or stalls.
Databases and transaction-heavy systems are especially vulnerable.
Swapping is considered a last resort and usually indicates serious overcommitment.
Persistent swapping often requires immediate infrastructure changes.
Understanding this progression helps explain why ballooning is so valuable.
It acts as the critical middle layer between passive optimization and disruptive intervention.
By reclaiming unused memory intelligently, ballooning often prevents environments from reaching compression or swapping stages.
This improves workload performance while preserving host stability.
Ballooning also enables better resource efficiency.
Organizations can safely run more virtual machines per host, improving return on hardware investment.
Without ballooning, administrators would need to provision physical memory more conservatively, increasing infrastructure costs.
This flexibility is one of virtualization’s greatest advantages.
It allows infrastructure to adapt dynamically to changing workload demands.
Applications receive memory when needed, while idle resources are reclaimed for other tasks.
This dynamic allocation improves responsiveness and maximizes utilization.
For administrators, understanding ballooning is essential.
It provides insight into host health, workload behavior, and infrastructure efficiency.
Monitoring balloon activity helps identify capacity issues early.
Performance charts and system tools allow administrators to track reclaimed memory levels and detect trends.
When ballooning appears regularly, it signals the need for review.
Proper memory planning reduces unnecessary reclamation activity and improves workload consistency.
Right-sizing virtual machines is especially important.
Many environments over-allocate memory because administrators assume more RAM always improves performance.
Unused allocations waste host capacity.
Ballooning helps recover some of this waste, but proper sizing remains the best solution.
Virtual machines should receive enough memory for normal workload operation without excessive surplus.
This improves consolidation efficiency and reduces memory pressure.
Memory reservations can also influence ballooning behavior.
Reserved memory guarantees physical allocation for specific workloads.
Virtual machines with full memory reservations are protected from ballooning.
This is useful for performance-sensitive systems such as large databases or critical application servers.
However, excessive reservations reduce host flexibility and limit consolidation benefits.
Reservations should be used carefully and strategically.
Ultimately, memory ballooning represents a sophisticated balance between efficiency and performance.
It allows hypervisors to optimize physical memory usage intelligently while minimizing disruption to workloads.
Its cooperative design makes it one of the most elegant solutions in virtualization technology.
Understanding how it works provides administrators with the knowledge needed to design healthier environments, improve resource utilization, and maintain stable performance across modern virtual infrastructure.
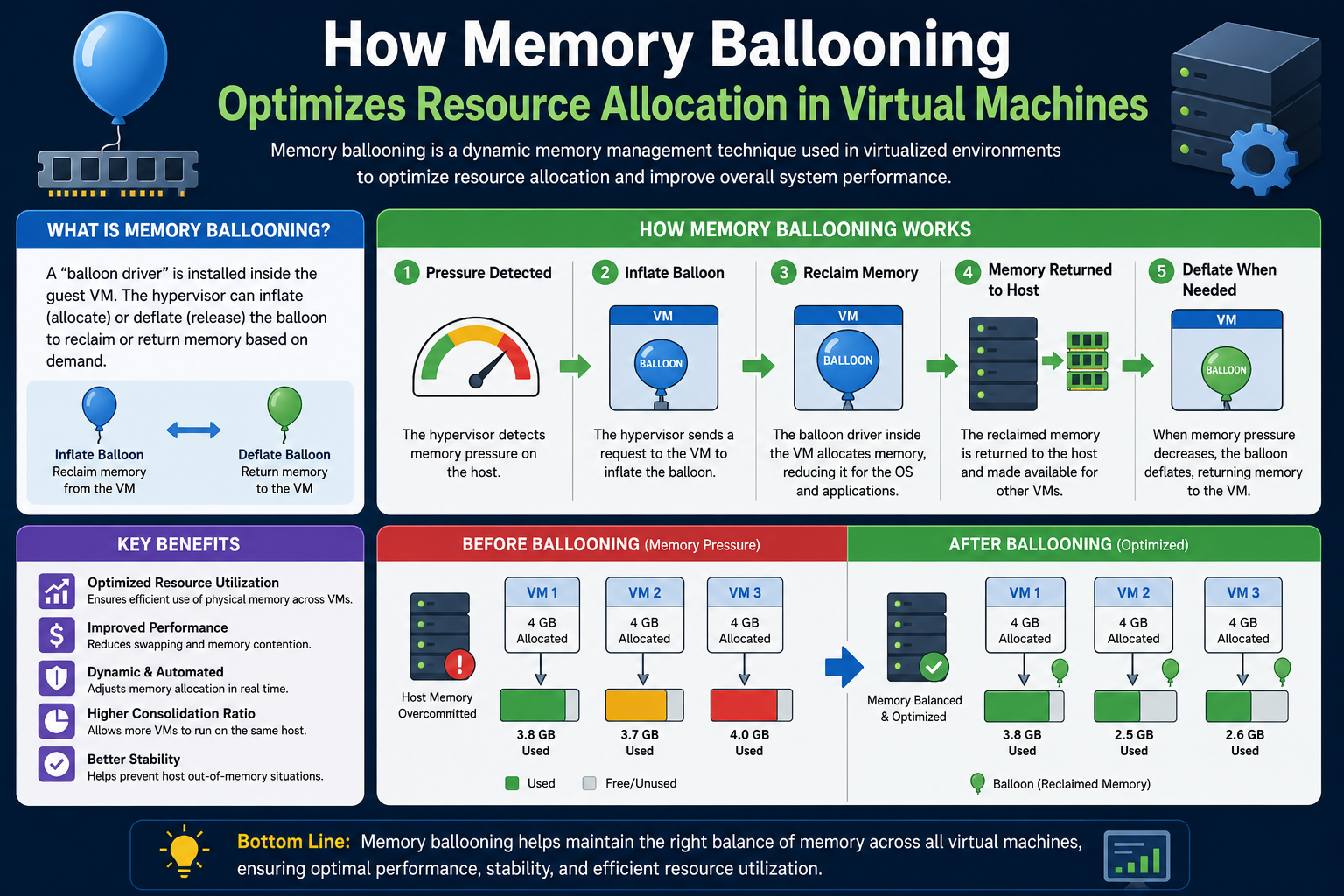
The Mechanics Behind Memory Ballooning
Memory ballooning is one of the most important memory reclamation technologies used in virtualized environments. It is designed to help the hypervisor recover unused memory from virtual machines when the physical host begins to experience memory pressure. This process allows memory to be redistributed efficiently to workloads that require it without immediately forcing the system to use more disruptive methods such as compression or swapping.
The concept of ballooning is built around cooperation between the hypervisor and the guest operating system. Unlike direct memory reclamation techniques where the hypervisor forcibly removes pages, ballooning works through a controlled mechanism that allows the guest operating system to participate in deciding which memory pages can be released.
This cooperation is possible through the installation of virtualization tools inside the guest operating system. These tools include a specialized balloon driver. The driver appears to the guest operating system as a legitimate process capable of requesting memory allocation.
When the hypervisor detects low physical memory availability on the host, it sends a signal to the balloon driver inside selected virtual machines. The balloon driver then begins to allocate guest memory.
From the guest operating system’s perspective, it appears that a process has requested additional memory resources. In response, the operating system must satisfy this allocation request by freeing memory wherever possible.
It does this by reclaiming cached pages, releasing idle memory, and reorganizing internal memory structures.
The balloon driver effectively consumes memory inside the guest operating system, making that memory unavailable for normal guest operations.
Once allocated by the balloon driver, the corresponding physical memory pages can be reclaimed by the hypervisor and reassigned to other virtual machines experiencing higher demand.
This process allows the host to recover memory intelligently while minimizing performance disruption.
The operating system itself determines which pages are least valuable and safest to release.
This is one of the main reasons ballooning is considered a smarter and less disruptive memory reclamation technique compared to hypervisor-level swapping.
The guest operating system has direct visibility into memory usage patterns.
It knows which pages are actively in use, which contain cache data, and which are safe to discard.
The hypervisor lacks this level of context.
If the hypervisor reclaimed memory blindly, it could remove pages critical to application performance.
Ballooning avoids this problem by allowing the guest to make informed memory management decisions.
This design significantly improves efficiency and stability during periods of memory contention.
It also allows virtualization platforms to safely overcommit memory without introducing severe risk.
Overcommitment relies on the assumption that not all virtual machines will fully consume their allocated memory simultaneously.
Ballooning helps enforce this assumption by reclaiming idle memory when required.
Without ballooning, memory overcommitment would be far more dangerous and difficult to manage.
Virtualized infrastructure would require much larger physical memory reserves, reducing consolidation efficiency and increasing hardware costs.
Ballooning makes dynamic memory redistribution practical and sustainable.
It supports the flexible resource allocation model that modern virtualization depends on.
When ballooning activates occasionally, it usually causes little to no noticeable impact on applications.
Most guest operating systems maintain memory caches that can be safely released when needed.
Cached file data, inactive application pages, and other reclaimable structures are common targets.
These pages can be discarded without affecting active processes.
If needed again later, the operating system simply reloads or reconstructs them.
Because of this behavior, moderate ballooning often occurs transparently.
Users may never notice it happening.
This is why ballooning is often considered mostly non-disruptive.
However, ballooning is not entirely free of overhead.
Allocating memory through the balloon driver consumes CPU cycles inside both the guest and host.
The guest operating system must identify reclaimable pages and update internal memory maps.
The hypervisor must track reclaimed pages and redistribute resources.
These operations introduce processing overhead.
In healthy environments, this overhead is minimal.
But if ballooning occurs constantly across many virtual machines, CPU utilization can increase noticeably.
This can reduce available compute resources for application workloads.
Sustained ballooning therefore indicates a resource imbalance that should be addressed.
Administrators should monitor ballooning carefully.
A small amount of occasional ballooning is generally acceptable.
Persistent or heavy ballooning suggests memory overcommitment is too aggressive.
When this happens, host capacity planning should be reviewed.
Several conditions can trigger excessive ballooning.
One common cause is over-allocation of virtual machine memory.
Administrators often assign more memory than workloads actually require.
This is usually done as a precaution.
While harmless on lightly loaded hosts, widespread over-allocation can create artificial memory pressure when many virtual machines run simultaneously.
Ballooning compensates for this by reclaiming unused allocations.
However, constant reclamation wastes system resources.
Right-sizing virtual machines is a more efficient solution.
Workloads should receive enough memory to perform well under expected load, but not excessive surplus.
Accurate monitoring and historical usage analysis help determine appropriate allocation levels.
Another cause of frequent ballooning is workload consolidation beyond practical limits.
Adding too many virtual machines to a host increases the likelihood of simultaneous memory demand spikes.
Even if average utilization appears manageable, peak usage periods can overwhelm physical memory capacity.
Ballooning helps temporarily absorb these spikes, but sustained contention eventually impacts performance.
Workload distribution across multiple hosts reduces this risk.
Cluster balancing technologies can automate migration of virtual machines to maintain healthy resource utilization.
This ensures no single host becomes overloaded.
Ballooning behavior is also influenced by memory reservations.
A reservation guarantees that a portion of physical memory is dedicated to a specific virtual machine.
Reserved memory cannot be reclaimed through ballooning.
This protects critical workloads from host memory contention.
Applications requiring consistent low-latency performance often benefit from reservations.
Database servers, financial systems, and real-time processing workloads are common examples.
However, reservations reduce memory flexibility.
Excessive use limits the hypervisor’s ability to redistribute resources efficiently.
This can increase pressure on unreserved virtual machines and trigger more ballooning elsewhere.
Reservations should therefore be applied selectively.
They are best reserved for workloads with strict performance requirements.
Understanding how ballooning interacts with application behavior is also important.
Not all workloads respond equally well to memory reclamation.
Some applications use large memory caches aggressively.
Database engines are a prime example.
They often consume available memory to cache frequently accessed data.
From the operating system’s perspective, this memory appears actively used.
Ballooning may force the database to shrink cache usage, increasing disk reads and reducing performance.
Other applications may allocate memory dynamically based on available resources.
When ballooning reduces available memory, these applications may scale back internal buffers or thread counts.
This can affect responsiveness and throughput.
Administrators should monitor sensitive workloads carefully when ballooning occurs.
If performance degradation is observed, memory reservations or host capacity adjustments may be necessary.
Ballooning should support workload efficiency, not compromise service quality.
Monitoring tools provide valuable insight into balloon activity.
Performance dashboards display reclaimed memory levels, balloon inflation size, and historical trends.
System-level diagnostic tools offer even deeper visibility.
These metrics help identify whether ballooning is occasional and harmless or frequent and problematic.
A zero ballooning baseline is ideal but not always realistic in dynamic environments.
Temporary balloon activity during workload bursts is normal.
The key concern is sustained reclamation that persists over time.
Long-duration ballooning indicates that host memory resources are consistently insufficient.
This requires corrective action.
Administrators should investigate host memory utilization, workload density, reservation settings, and allocation patterns.
Corrective actions may include adding physical RAM, migrating workloads, resizing virtual machines, or reconfiguring cluster balancing policies.
Ignoring chronic ballooning can lead to escalation into compression or swapping.
This introduces far greater performance impact.
Compression occurs when ballooning cannot recover enough memory.
The hypervisor compresses memory pages to free physical space.
While faster than disk swapping, compression adds CPU overhead and increases memory access latency.
If pressure continues rising, swapping begins.
Swapping writes memory pages to disk.
This dramatically slows application performance.
Preventing escalation is one of ballooning’s greatest strengths.
It provides an early intervention layer that often resolves shortages before compression or swapping become necessary.
This makes ballooning essential to stable memory overcommitment.
Despite its advantages, some administrators attempt to disable ballooning entirely.
This is usually done by reserving all guest memory or removing the balloon driver.
While this prevents guest memory reclamation, it also removes one of the hypervisor’s most intelligent optimization tools.
Without ballooning, memory pressure escalates more quickly to swapping.
This often causes worse performance than ballooning itself.
Disabling ballooning should only be considered for workloads proven to be highly sensitive to memory reclamation.
Even then, careful planning is required.
For most environments, ballooning should remain enabled.
Its design reflects decades of virtualization engineering refinement.
It offers a practical balance between resource efficiency and workload stability.
The ability to reclaim unused memory safely is one of the reasons virtualization can achieve such high hardware utilization rates.
Organizations save substantial infrastructure costs because ballooning supports flexible memory sharing.
This allows more workloads to coexist on fewer physical servers.
At the same time, intelligent guest cooperation preserves application performance.
This balance is difficult to achieve through simpler memory management approaches.
Ballooning remains one of the defining technologies that make enterprise virtualization practical at scale.
For administrators, mastering ballooning concepts is essential.
Understanding how it works enables better troubleshooting, smarter capacity planning, and healthier virtual environments.
It helps identify inefficiencies, prevent performance bottlenecks, and optimize workload placement.
As virtual infrastructure continues evolving, memory ballooning remains a foundational component of efficient resource management.
Its importance extends beyond basic memory reclamation.
It represents the intelligent cooperation between software layers that defines modern virtualization architecture.
By allowing hosts and guests to work together, ballooning delivers stability, flexibility, and efficiency that would otherwise be difficult to achieve in large-scale virtual environments.
Monitoring Ballooning Activity in Virtual Infrastructure
Effective management of memory ballooning requires continuous monitoring. While ballooning is a valuable technology for reclaiming unused memory, excessive or sustained balloon activity often indicates deeper resource allocation problems. Administrators must understand how to detect ballooning, interpret what it means, and take appropriate action before performance degradation becomes severe.
Virtualization platforms provide several ways to monitor ballooning activity.
Performance charts within management consoles provide the most accessible method. These charts display memory statistics across hosts and virtual machines, including ballooned memory, consumed memory, active memory, shared memory, compressed memory, and swapped memory.
By reviewing historical trends, administrators can identify whether ballooning is occasional or persistent.
Occasional ballooning during workload spikes is normal. Virtual environments are dynamic by nature, and short-term memory contention is expected when workloads fluctuate.
Sustained ballooning, however, indicates that host memory pressure is occurring frequently enough to require repeated reclamation.
This suggests memory overcommitment has exceeded healthy operational thresholds.
Monitoring should focus on both host-level and guest-level activity.
Host-level monitoring reveals overall memory pressure across physical resources.
Guest-level monitoring shows which virtual machines are being ballooned and how aggressively memory is being reclaimed.
This distinction is critical because ballooning may affect only specific workloads while others remain unaffected.
Some virtual machines are more likely to be ballooned because they contain reclaimable memory.
Others may resist reclamation due to active memory use or full reservations.
Understanding which workloads are ballooning helps administrators identify oversized allocations or inefficient application behavior.
Command-line diagnostic tools provide even deeper visibility.
Detailed memory counters reveal whether balloon drivers are installed and operational.
Metrics show current balloon inflation size, maximum reclaimable memory, and historical balloon activity.
These diagnostics are especially useful for troubleshooting abnormal behavior.
If ballooning is expected but not occurring, missing guest tools or configuration issues may be preventing the balloon driver from functioning.
Without ballooning, the hypervisor loses one of its most effective memory reclamation mechanisms.
This forces faster escalation to compression or swapping.
Regular verification of balloon driver status is therefore essential.
Guest operating systems also provide clues about ballooning.
When balloon inflation occurs, available memory inside the guest decreases.
The operating system may respond by shrinking caches, releasing buffers, or reducing standby memory.
Application performance counters may show increased paging or reduced cache efficiency.
These indirect indicators help confirm balloon-related behavior from inside the guest.
Monitoring should include workload-specific metrics whenever possible.
Applications respond differently to reduced available memory.
A database server may show declining cache hit rates.
A file server may increase storage reads.
A web server may experience reduced response throughput.
Correlating balloon activity with application performance helps determine whether reclamation is affecting service quality.
This visibility supports informed decision-making.
Administrators can determine whether ballooning is harmless optimization or a genuine performance risk.
This distinction is essential for effective troubleshooting.
Common Causes of Ballooning Problems
Not all ballooning activity is problematic, but persistent or aggressive ballooning usually points to one or more underlying issues.
One of the most common causes is excessive memory overcommitment.
Overcommitment itself is not inherently bad.
It is one of virtualization’s greatest efficiency advantages.
The problem arises when allocated memory far exceeds realistic physical capacity during peak demand periods.
Administrators often assign generous memory allocations to avoid potential performance complaints.
While well-intentioned, this practice can create artificial scarcity.
Many virtual machines end up with idle reserved memory while the host struggles to satisfy active workloads elsewhere.
Ballooning attempts to correct this imbalance, but constant reclamation introduces unnecessary overhead.
Proper right-sizing solves this issue more effectively.
When virtual machines are allocated excessive memory they rarely use, physical resources become fragmented across the environment. This reduces flexibility for workloads that genuinely need immediate access to additional memory during processing spikes. As demand rises, the hypervisor must repeatedly reclaim idle pages through ballooning to compensate for poor allocation planning.
This repeated reclamation consumes processing cycles and increases resource management overhead on both the host and guest operating systems. Over time, sustained ballooning can create noticeable inefficiencies, particularly in environments running high-density virtual workloads.
Historical usage analysis is essential for solving this issue. By reviewing memory trends over weeks or months, administrators can identify virtual machines that consistently operate far below their assigned capacity. Reducing these allocations frees valuable host memory for more demanding workloads.
Regular workload assessments also ensure resource assignments evolve alongside changing application requirements. As workloads grow or decline, memory configurations should be adjusted accordingly. This keeps memory utilization balanced, minimizes unnecessary reclamation, and supports long-term infrastructure stability while maintaining strong virtual machine performance.
Historical memory utilization data should guide allocation decisions.
Virtual machines should receive enough memory for sustained performance under normal and peak workloads without excessive unused surplus.
Another frequent cause is poor workload distribution.
A cluster may contain sufficient total memory, but if workloads are concentrated unevenly across hosts, localized memory pressure occurs.
One host may balloon heavily while others remain underutilized.
Automated balancing solutions can address this problem.
Dynamic migration technologies redistribute workloads based on resource utilization.
These systems reduce memory hotspots and maintain healthier cluster-wide balance.
If balancing is unavailable or misconfigured, manual workload redistribution may be necessary.
Application behavior can also contribute to ballooning challenges.
Some workloads aggressively consume all available memory by design.
Databases commonly expand cache usage to maximize performance.
Operating systems may treat cached memory as reclaimable, but applications often rely on it heavily.
Ballooning these systems can reduce efficiency and increase disk access.
Similarly, memory-intensive analytics workloads may allocate large working sets dynamically.
Ballooning can force repeated memory restructuring, reducing throughput.
These workloads may benefit from reservations or dedicated hosts.
Configuration mistakes are another common source of ballooning issues.
Missing guest tools prevent balloon driver operation.
Incorrect reservation settings can create unfair memory distribution.
Outdated hypervisor versions may contain memory management inefficiencies.
Routine maintenance and validation reduce these risks.
Keeping tools updated ensures balloon drivers function correctly and benefit from performance improvements.
Host hardware limitations can also trigger chronic ballooning.
If workloads consistently exceed realistic physical memory capacity, no amount of tuning will eliminate pressure.
In these cases, adding RAM or expanding cluster capacity becomes necessary.
Memory upgrades are often cost-effective compared to performance degradation caused by chronic reclamation.
Infrastructure planning should anticipate growth trends.
Waiting until ballooning becomes severe usually means capacity expansion is already overdue.
Proactive planning avoids disruption.
Best Practices for Optimizing Ballooning Performance
Successful ballooning management depends on proactive optimization rather than reactive troubleshooting.
The first best practice is maintaining accurate workload visibility.
Administrators should continuously monitor memory consumption trends, active memory usage, and historical demand patterns.
Allocation decisions should reflect real usage data rather than assumptions.
Memory right-sizing is the most effective optimization strategy.
Reducing oversized allocations improves consolidation efficiency and reduces unnecessary reclamation.
Virtual machines frequently receive far more memory than they actively use.
Regular performance reviews allow administrators to identify virtual machines that consistently operate below their assigned memory capacity. By analyzing these trends over time, unnecessary allocations can be reduced without negatively impacting application performance. This reclaimed memory can then be redistributed to workloads that require additional resources or reserved for future scaling needs.
Accurate memory planning also improves host stability. When memory resources are assigned efficiently, the hypervisor can manage workloads with less pressure, reducing the likelihood of aggressive ballooning, memory compression, or disk swapping. This creates a healthier environment where applications perform more consistently.
Automated monitoring tools can further improve optimization efforts by generating alerts when memory utilization exceeds expected thresholds. These alerts help administrators respond quickly to unusual demand spikes before they become serious performance issues.
Testing workloads under different memory configurations is another effective strategy. Controlled adjustments reveal how applications respond to reduced or increased allocations, allowing administrators to find the ideal balance between performance and efficiency.
Organizations that prioritize continuous memory optimization often achieve better consolidation ratios, lower infrastructure costs, and more predictable virtual machine performance across their entire environment.
Periodic audits identify these inefficiencies.
Reclaiming unused allocations increases host flexibility without affecting application performance.
Another best practice is selective use of reservations.
Critical workloads requiring guaranteed performance may justify reserved memory.
However, excessive reservations reduce resource sharing flexibility.
Reservations should be limited to workloads with demonstrated sensitivity to reclamation.
Testing helps determine whether reservations are truly necessary.
Balancing workloads intelligently across hosts is equally important.
Avoid clustering memory-intensive workloads together unless sufficient physical capacity exists.
Distribute peak-demand applications across available resources.
Automated balancing policies should be reviewed regularly to ensure effective operation.
Thresholds should align with workload behavior.
Aggressive balancing may cause unnecessary migrations.
Weak balancing may allow prolonged contention.
Finding the right balance improves efficiency.
Maintaining healthy host memory headroom is another key practice.
Operating close to full physical utilization leaves little room for demand spikes.
Moderate reserve capacity allows ballooning to absorb temporary fluctuations without escalation.
Capacity planning should include growth forecasting and peak-demand modeling.
Planning for average usage alone often leads to surprises.
Peak conditions define real infrastructure resilience.
Guest tool maintenance should not be overlooked.
Balloon drivers depend on current virtualization tools.
Outdated versions may perform poorly or fail to integrate with newer hypervisor improvements.
Regular updates improve reliability and compatibility.
Application-aware optimization further improves outcomes.
Understand how key workloads use memory.
A lightly used file server behaves differently from a high-performance transactional database.
Tailor memory policies accordingly.
Monitoring application performance during balloon events helps refine configurations.
Testing is invaluable.
Controlled stress testing reveals how workloads respond to reclamation.
This identifies sensitive systems before production issues arise.
Testing also validates reservation strategies and host capacity assumptions.
Finally, educate operational teams.
Many administrators misunderstand ballooning and treat any balloon activity as failure.
In reality, ballooning is often a healthy optimization.
Understanding its purpose prevents unnecessary alarm while ensuring real problems receive attention.
Knowledge improves decision-making and reduces misconfiguration risk.
Conclusion
Memory ballooning remains one of the most intelligent and effective technologies in virtualized infrastructure. It allows hypervisors to reclaim unused memory safely, redistribute resources dynamically, and maintain efficient hardware utilization without immediately sacrificing workload performance.
Its cooperative design makes it fundamentally different from disruptive reclamation methods like swapping. By allowing guest operating systems to determine which memory pages can be released, ballooning minimizes unnecessary performance impact and preserves application stability.
When functioning properly, ballooning enables organizations to overcommit memory confidently. This improves consolidation ratios, reduces hardware costs, and increases infrastructure flexibility.
At the same time, ballooning serves as an early warning system.
Frequent or sustained balloon activity signals resource pressure that administrators should investigate before performance degradation escalates.
Proper monitoring, accurate right-sizing, balanced workload placement, selective reservations, and proactive capacity planning all contribute to healthy ballooning behavior.
These practices ensure memory reclamation remains a tool for optimization rather than a symptom of chronic resource shortage.
Understanding memory ballooning is essential for anyone managing virtual environments.
It is more than just a technical mechanism.
It represents the intelligent resource coordination that makes large-scale virtualization practical, efficient, and reliable.
When properly managed, memory ballooning helps organizations achieve the full benefits of virtualization while maintaining strong workload performance and long-term infrastructure stability.