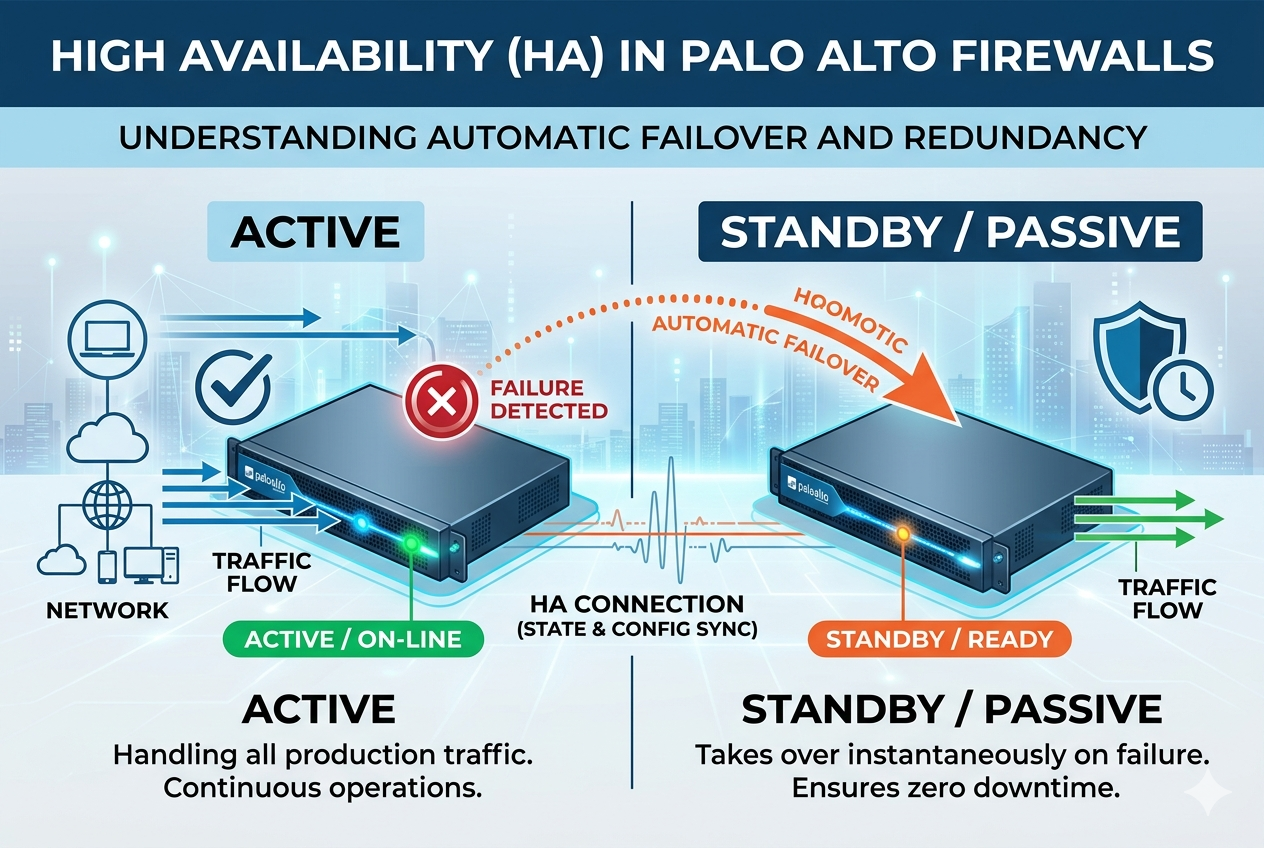
High Availability in Palo Alto Firewalls is not just a simple backup mechanism but a carefully engineered architecture that ensures continuous security enforcement across complex enterprise networks. At its core, HA relies on tight coordination between two firewall devices that function as a unified system. This architecture is built around constant state synchronization, real-time health monitoring, and automated role management.
Each firewall in the HA pair is configured with identical software versions, licensing, and security policies. This uniformity is essential because the standby device must be able to instantly replicate the behavior of the active device without any configuration mismatch. The architecture also depends heavily on dedicated HA communication channels that carry heartbeat signals and synchronization data. These channels ensure that both devices remain aware of each other’s status at all times.
The HA system is designed with resilience in mind. It does not rely on a single detection method but instead combines multiple layers of verification before making a failover decision. This reduces the chances of unnecessary failovers caused by temporary network fluctuations or interface glitches.
State Synchronization and Session Continuity Mechanism
One of the most technically critical aspects of Palo Alto High Availability is state synchronization. Firewalls do not simply forward packets; they maintain detailed session tables that define how traffic flows between sources and destinations. These session tables include information such as IP addresses, port numbers, application identification, NAT translations, and security policy decisions.
In an HA setup, this session information is continuously replicated from the active firewall to the passive firewall. This ensures that the standby device has a near real-time copy of all active sessions. When a failover occurs, the new active firewall can immediately continue processing existing sessions without requiring users to reconnect.
This synchronization process is highly optimized to reduce overhead while maintaining accuracy. Instead of transferring the entire session database repeatedly, only incremental changes are sent. This improves performance and reduces bandwidth consumption over HA links.
However, session synchronization is not always perfect for every type of traffic. Certain applications with highly dynamic or encrypted sessions may experience minor interruptions during failover. Despite this, the system is designed to minimize disruption as much as possible.
HA Timers and Failure Detection Logic
The decision-making process in High Availability is governed by a set of timers and thresholds that define how quickly a firewall should respond to potential failures. These timers control heartbeat intervals, failure detection time, and promotion delays.
Heartbeat intervals define how often the two firewalls exchange health signals. If a firewall stops receiving these signals within a defined threshold, it begins evaluating whether a failover is necessary. This prevents immediate reactions to short-lived network instability.
Another important component is the failure detection threshold. This determines how many missed heartbeats or failed checks are required before declaring the active firewall as down. This layered approach ensures that failover only occurs when a real issue exists.
Promotion delay timers also play a role in preventing rapid role switching. When a failed firewall comes back online, it does not immediately reclaim its previous role. Instead, it undergoes a stabilization period to ensure that it is fully synchronized and stable before rejoining the HA cluster.
Split-Brain Prevention and Network Stability
One of the most critical risks in any HA system is the split-brain scenario. This occurs when both firewalls mistakenly believe they are the active device. If not properly handled, this can lead to duplicate traffic processing, routing conflicts, and serious network instability.
Palo Alto Firewalls prevent split-brain conditions using multiple safeguards. The most important mechanism is the use of dedicated HA links that allow continuous communication between devices. If these links fail, additional monitoring methods such as interface and path monitoring help determine the actual state of each firewall.
In some configurations, preconfigured priority settings are used to decide which firewall should assume control in ambiguous situations. This ensures that even if communication is partially disrupted, only one device will take the active role.
Split-brain prevention is essential for maintaining data integrity and ensuring that network traffic is processed consistently without duplication or loss.
Virtual MAC Address and Traffic Redirection Process
When a failover occurs, the transition must be seamless to avoid disrupting network communication. One of the key mechanisms that enables this smooth transition is the use of a virtual MAC address.
Instead of relying on the physical MAC address of each firewall interface, the HA pair shares a virtual MAC address. This allows upstream switches and routers to continue forwarding traffic to the same logical endpoint even after a failover event.
When the standby firewall becomes active, it assumes control of the virtual MAC address and begins responding to network requests as if nothing has changed. This eliminates the need for network devices to relearn MAC address tables or update routing paths, significantly reducing convergence time.
This mechanism is especially important in high-traffic environments where even small delays can impact application performance.
Routing Behavior in High Availability Environments
Routing plays a crucial role in HA deployments because firewalls often act as default gateways or policy enforcement points. In an HA setup, routing tables are synchronized between devices to ensure consistency.
Dynamic routing protocols such as OSPF or BGP can also be integrated with HA configurations. When a failover occurs, routing adjacencies may briefly reset, but the system is designed to restore them quickly. The goal is to minimize route recalculation and maintain stable network paths.
In Active/Active configurations, routing becomes more complex because both firewalls may advertise routes simultaneously. This requires careful design to avoid asymmetric routing, where traffic flows through different paths in each direction. Proper configuration ensures that return traffic follows the same firewall that processed the initial request.
Deployment Planning and Design Considerations
Designing a High Availability setup requires careful planning to ensure optimal performance and reliability. One of the first considerations is hardware compatibility. Both firewalls must be identical or fully compatible models to ensure proper synchronization.
Network segmentation is another important factor. HA links should be isolated from production traffic to prevent congestion or interference. Dedicated interfaces are typically used for control and data synchronization.
Physical placement of firewalls also matters. In some environments, devices are placed in separate racks or even different data centers to provide geographic redundancy. This ensures that a localized failure does not impact both devices simultaneously.
Power redundancy and environmental controls are also part of the design process. Since HA relies on two devices, both must be protected against power outages and cooling failures to maintain overall system reliability.
Common Issues in HA Deployments and Their Causes
Despite its robustness, High Availability in Palo Alto Firewalls can encounter issues if not properly configured or maintained. One common issue is HA link instability, which can lead to unnecessary failovers. This often occurs due to faulty cables, misconfigured interfaces, or network congestion on dedicated HA links.
Another frequent issue is configuration mismatch between devices. If one firewall is updated or modified without proper synchronization, inconsistencies can arise, potentially causing failover failures or policy enforcement issues.
Session synchronization delays can also occur in high-load environments. When traffic volumes are extremely high, HA links may become saturated, leading to partial session loss during failover.
Incorrect monitoring configuration is another source of problems. If monitoring thresholds are too sensitive, temporary network fluctuations may trigger unnecessary failovers, disrupting network stability.
Troubleshooting High Availability Problems
Troubleshooting HA issues requires a systematic approach. The first step is to verify the status of HA synchronization between devices. If synchronization is not working correctly, configuration differences or interface problems are often the root cause.
Next, administrators typically check HA link health to ensure that heartbeat signals are being exchanged properly. Any packet loss or delay in these links can lead to instability.
System logs provide valuable insights into failover events and can help identify whether a transition was triggered by hardware failure, interface loss, or path monitoring alerts.
Another important troubleshooting step is verifying session consistency after failover. If many sessions are dropped, it may indicate a problem with state synchronization or link congestion.
Performance Optimization in HA Environments
To achieve optimal performance in High Availability deployments, proper tuning of synchronization settings is essential. This includes balancing session update frequency with network capacity to avoid overloading HA links.
Load distribution in Active/Active configurations must also be carefully managed to ensure that both firewalls share traffic evenly. Uneven load distribution can lead to performance bottlenecks on one device while the other remains underutilized.
Regular firmware updates and patch management are also important for maintaining stability and performance. Since both devices must remain synchronized, updates should always be applied in a controlled sequence.
Security Considerations in High Availability Design
High Availability does not reduce the importance of security; in fact, it increases the need for consistent enforcement. Both firewalls must enforce identical security policies to prevent gaps during failover.
If configuration drift occurs between devices, it can create vulnerabilities where one firewall enforces stricter rules than the other. This inconsistency can be exploited during failover transitions.
HA communication channels themselves must also be secured to prevent unauthorized access or tampering. Since these links carry sensitive session and configuration data, they should be isolated and protected from external access.
Real-World Importance of High Availability in Enterprises
In modern enterprises, downtime is often unacceptable. Critical systems such as financial applications, healthcare platforms, cloud services, and industrial control systems rely heavily on continuous network availability. High Availability in Palo Alto Firewalls ensures that these systems remain protected and accessible even during unexpected failures.
By eliminating single points of failure, HA architectures significantly improve business continuity and operational resilience. Organizations can perform maintenance, upgrades, or troubleshooting without disrupting end users or compromising security.
The ability to maintain seamless connectivity during failures makes HA an essential component of enterprise-grade network security infrastructure.
Conclusion
High Availability in Palo Alto Firewalls represents a sophisticated and essential approach to maintaining continuous network security and uptime. It combines redundancy, real-time synchronization, intelligent failover mechanisms, and robust monitoring systems to ensure that security services remain uninterrupted even in the face of hardware or software failures.
Through Active/Passive and Active/Active architectures, organizations can choose the level of redundancy and performance that best fits their operational needs. Features such as session synchronization, virtual MAC addressing, split-brain prevention, and routing integration work together to create a highly resilient system.
When properly designed, configured, and maintained, High Availability transforms firewalls from single points of failure into reliable, self-healing systems that support modern digital infrastructure.