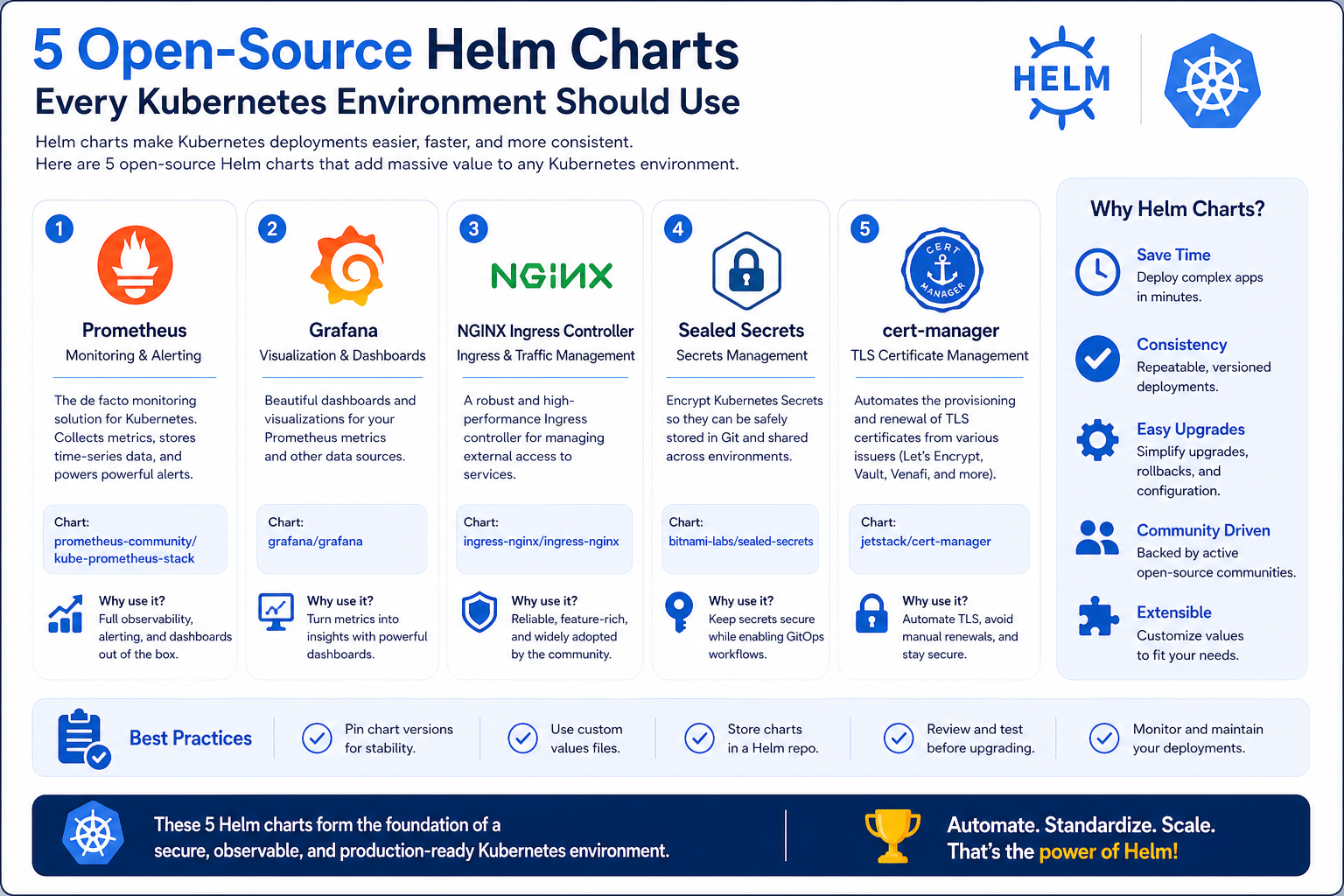
The Ingress NGINX Controller is one of the most essential building blocks in a Kubernetes environment because it manages how external traffic reaches internal services. It works as a smart entry point that routes requests based on rules such as hostnames, paths, and headers. This makes it possible to expose multiple applications through a single controlled gateway instead of opening separate access points for each service.
One of its biggest strengths is flexibility. It supports load balancing, SSL termination, and advanced routing configurations that allow teams to design traffic flow in a structured way. Instead of manually configuring networking rules for every application, the Helm chart provides a standardized deployment method that ensures consistency across environments.
In production systems, reliability is critical, and this controller is designed with high availability in mind. It can run across multiple replicas, ensuring that traffic continues to flow even if one instance fails. It also integrates with monitoring tools, giving visibility into request patterns, latency, and error rates.
This chart is often the first layer deployed in Kubernetes clusters because nearly every application requires controlled external access. It becomes the foundation for exposing APIs, web applications, and internal tools in a secure and manageable way.
cert-manager Helm Chart
Security is a core requirement in any modern infrastructure, and managing TLS certificates manually can quickly become complex and error-prone. The cert-manager Helm chart solves this by automating the entire lifecycle of certificates, including issuance, renewal, and expiration handling.
It works by integrating with certificate authorities and Kubernetes resources to automatically issue certificates whenever they are needed. This removes the need for manual configuration and significantly reduces the risk of downtime caused by expired certificates.
One of its key advantages is automation. Once configured, it continuously monitors certificate status and renews them before they expire. This ensures uninterrupted secure communication between services without human intervention.
It also supports multiple issuance methods, making it suitable for both internal cluster communication and external-facing applications. Developers can define certificate requirements declaratively, and cert-manager handles the rest.
In large-scale environments where hundreds of services communicate with each other, this automation becomes essential for maintaining a strong security posture and operational stability.
kube-prometheus-stack Helm Chart
Observability is critical in distributed systems because issues can occur anywhere across the infrastructure. The kube-prometheus-stack Helm chart provides a complete monitoring solution by combining Prometheus, Grafana, and Alertmanager into a single deployment package.
Prometheus is responsible for collecting and storing metrics from Kubernetes components, nodes, and applications. It continuously scrapes data such as CPU usage, memory consumption, and request latency, giving real-time visibility into system performance.
Grafana complements this by offering visualization capabilities. It transforms raw metrics into dashboards that make it easier to understand system behavior and identify trends over time. This helps teams quickly detect performance bottlenecks or abnormal patterns.
Alertmanager adds another layer by enabling automated alerts based on predefined thresholds. When something goes wrong, notifications are sent immediately, allowing teams to respond before issues escalate.
This stack is widely adopted because it provides full observability coverage in a single setup. It allows teams not only to monitor infrastructure health but also to understand application-level behavior in production environments.
metrics-server Helm Chart
The metrics-server is a lightweight but essential component in Kubernetes that collects resource usage data from nodes and pods. It provides real-time CPU and memory metrics that are used by core Kubernetes features such as autoscaling.
Without this component, Kubernetes would not be able to automatically adjust workloads based on demand. It feeds data into the control plane so that scaling decisions can be made dynamically.
Unlike full monitoring systems, the metrics-server focuses only on short-term resource usage. It does not store historical data but instead provides current state information, making it efficient and fast.
It is commonly used by the horizontal pod autoscaler, which increases or decreases the number of running pods based on workload demands. This ensures that applications remain responsive even during traffic spikes.
Its simplicity makes it one of the first components deployed in any Kubernetes cluster because many other features depend on it for basic functionality.
external-dns Helm Chart
Managing DNS records manually in dynamic environments can become difficult, especially when services are frequently created, updated, or removed. The external-dns Helm chart automates this process by synchronizing Kubernetes resources with DNS providers.
It continuously monitors ingress and service objects inside the cluster and automatically updates DNS records to match the current state. This ensures that domain names always point to the correct services without manual intervention.
This automation reduces operational complexity and eliminates human error in DNS configuration. It also supports multiple DNS providers, making it adaptable to different cloud or hybrid environments.
In fast-moving deployment pipelines, external-dns ensures that new services are immediately accessible through consistent domain names. This is especially useful in environments where applications are frequently scaled or redeployed.
By keeping DNS records in sync with cluster state, it improves reliability and reduces the chances of broken or outdated routing configurations.
Building a Strong Kubernetes Foundation with Helm Charts
When combined, these Helm charts create a complete operational foundation for Kubernetes environments. Each one addresses a specific area such as networking, security, monitoring, scaling, and service discovery.
Instead of manually configuring each system component, Helm provides a standardized and repeatable deployment method. This ensures that environments remain consistent across development, testing, and production.
This consistency reduces configuration drift and makes troubleshooting easier because systems behave predictably across all stages.
Automation as the Core of Cloud-Native Systems
Automation is one of the biggest advantages of using these Helm charts. Tasks such as certificate renewal, DNS management, scaling, and traffic routing are handled automatically without manual intervention.
This reduces operational workload and minimizes the risk of human error, which is often a major cause of outages in complex systems.
Automation also allows systems to respond quickly to changes in demand. Whether traffic increases or decreases, Kubernetes can adjust resources dynamically while maintaining stability.
Scalability and Production Readiness
These Helm charts are designed for real-world production environments where systems must handle unpredictable workloads. Features like autoscaling, load balancing, and automated recovery ensure that applications remain available under pressure.
They are widely used because they have been tested in large-scale deployments and proven to handle enterprise-level workloads reliably.
For growing organizations, they provide a stable foundation that can scale alongside business needs without requiring major architectural changes.
A Complete Cloud-Native Ecosystem
Together, these tools form a complete ecosystem that supports modern cloud-native applications. Kubernetes provides orchestration, while these Helm charts add operational intelligence on top.
They enable secure communication, efficient traffic management, real-time monitoring, automatic scaling, and seamless service discovery.
This combination allows teams to focus more on application development rather than infrastructure management, making systems more efficient, reliable, and scalable.
External Secrets Operator Helm Chart
Managing secrets directly inside Kubernetes can quickly become difficult as applications scale. The External Secrets Operator Helm chart solves this by allowing Kubernetes to fetch and synchronize secrets from external secret management systems automatically.
Instead of storing sensitive data like API keys, passwords, or tokens directly in Kubernetes manifests, this chart enables integration with secure external providers. These secrets are then dynamically injected into Kubernetes workloads when needed, reducing the risk of exposure.
One of its major benefits is centralization. Organizations often use dedicated secret stores for better security control, auditing, and rotation policies. This Helm chart bridges Kubernetes with those systems, ensuring that secrets remain consistent and up to date across environments.
It also improves operational security by reducing manual handling of sensitive data. Since secrets are not hardcoded or duplicated across configurations, the risk of accidental leaks is significantly reduced.
In large environments with multiple clusters, this approach ensures uniform secret management, making it easier to enforce security policies across the entire infrastructure.
Argo CD Helm Chart
Continuous delivery is a key part of modern cloud-native systems, and Argo CD brings a powerful GitOps approach to Kubernetes deployments. This Helm chart allows clusters to automatically synchronize their state with version-controlled configuration repositories.
Instead of manually applying updates or running deployment commands, Argo CD continuously monitors the desired state defined in Git and ensures that the cluster matches it. This creates a clear separation between application code and infrastructure state.
One of its biggest strengths is visibility. It provides a clear dashboard showing deployment status, differences between desired and actual states, and history of changes. This makes it easier to track updates and roll back when necessary.
It also improves reliability by enforcing consistency. If someone makes an unintended manual change inside the cluster, Argo CD can automatically correct it, ensuring that the system always aligns with the defined configuration.
This Helm chart is widely used in production environments because it simplifies deployment workflows while increasing control and transparency.
Kubernetes Dashboard Helm Chart
Managing Kubernetes through command-line tools is powerful but can be complex for day-to-day operations. The Kubernetes Dashboard Helm chart provides a graphical interface that simplifies cluster management and monitoring.
It allows users to view workloads, inspect pods, check logs, and monitor resource usage from a centralized interface. This makes it easier for teams to understand what is happening inside the cluster without relying solely on terminal commands.
One of its advantages is accessibility. New team members or non-specialist users can quickly gain visibility into the system without deep Kubernetes expertise. This improves collaboration between development and operations teams.
It also supports role-based access control, ensuring that users only see information relevant to their permissions. This helps maintain security while still providing useful visibility.
Although not a replacement for CLI tools, it serves as a helpful companion for monitoring and troubleshooting in real time.
Node Problem Detector Helm Chart
In large Kubernetes clusters, node-level issues can sometimes go unnoticed until they impact workloads. The Node Problem Detector Helm chart helps address this by continuously monitoring nodes for hardware, kernel, and runtime issues.
It runs as an agent on each node and reports abnormal conditions such as disk failures, network problems, or system instability. These issues are then surfaced to the Kubernetes control plane so they can be acted upon quickly.
One of its key benefits is early detection. Instead of waiting for applications to fail, it identifies underlying infrastructure problems before they escalate into outages.
It also integrates with Kubernetes event systems, making it easier to trigger alerts or automated responses when issues are detected. This improves system resilience and reduces downtime.
For production environments, this chart adds an important layer of infrastructure health monitoring that complements application-level observability tools.
Velero Helm Chart
Backup and disaster recovery are essential components of any production-grade Kubernetes environment. The Velero Helm chart provides a reliable solution for backing up cluster resources and restoring them when needed.
It allows teams to take scheduled backups of entire namespaces, persistent volumes, and application configurations. These backups can be stored in external object storage systems for long-term retention.
One of its most important features is recovery flexibility. In the event of a cluster failure or accidental deletion, workloads can be restored quickly with minimal downtime. This ensures business continuity even in critical failure scenarios.
Velero also supports migration between clusters, making it useful for upgrading infrastructure or moving workloads between environments. This reduces complexity during large-scale system changes.
By providing both backup and disaster recovery capabilities, this Helm chart plays a crucial role in ensuring system resilience and operational safety.
Strengthening Kubernetes Operations with These Helm Charts
When combined, these additional Helm charts significantly enhance the operational maturity of a Kubernetes environment. They extend beyond basic infrastructure management and focus on security, deployment automation, visibility, and resilience.
Each chart addresses a different operational challenge, ensuring that clusters are not only functional but also secure, observable, and recoverable in case of failure.
Security, Automation, and Reliability as Core Principles
Modern Kubernetes environments rely heavily on automation and strong security practices. Tools like External Secrets Operator and cert-manager reduce manual handling of sensitive data, while Argo CD ensures consistent deployments.
At the same time, monitoring tools like Node Problem Detector and kube-prometheus-stack ensure that both infrastructure and applications remain healthy and observable.
This layered approach ensures that no single point of failure goes unnoticed or unmanaged.
Operational Maturity Through Standardized Tooling
Using standardized Helm charts across environments improves consistency and reduces operational complexity. Teams can deploy, scale, and manage clusters with predictable behavior, which is essential for long-term stability.
It also simplifies collaboration across teams because everyone works with the same set of tools and patterns, reducing confusion and configuration drift.
Building a Resilient Cloud-Native Ecosystem
Together with foundational charts like ingress controllers and monitoring stacks, these additional tools complete a full cloud-native ecosystem. They ensure that Kubernetes environments are not only scalable but also secure, observable, and resilient.
This combination allows organizations to confidently run critical workloads in production while maintaining flexibility for future growth and innovation.
Kubernetes Event Exporter Helm Chart
In a Kubernetes environment, events are one of the most important sources of real-time system insight, yet they are often overlooked because they are short-lived and not stored by default. The Kubernetes Event Exporter Helm chart addresses this limitation by capturing cluster events and forwarding them to external logging or monitoring systems.
This chart continuously watches for important events such as pod failures, scheduling issues, scaling activities, and resource warnings. Instead of disappearing after a short time, these events are preserved and made available for analysis. This helps teams understand what happened inside the cluster during specific incidents.
One of its biggest advantages is improved observability. While metrics show system performance, events explain the reasons behind changes or failures. This combination gives a much clearer picture when troubleshooting complex issues.
It also supports multiple output destinations, allowing events to be sent to logging platforms, alerting systems, or storage backends. This flexibility makes it suitable for different monitoring architectures.
In production environments, it becomes a valuable diagnostic tool because it captures the “story” of what is happening inside the cluster in real time.
Longhorn Helm Chart
Storage is a critical part of any Kubernetes system, especially for stateful applications that require persistent data. The Longhorn Helm chart provides a distributed block storage system designed specifically for Kubernetes environments.
It allows teams to create persistent volumes that are replicated across multiple nodes, ensuring data availability even if one node fails. This built-in redundancy improves resilience and reduces the risk of data loss.
One of its key strengths is simplicity. It provides a user-friendly interface for managing storage volumes, backups, and snapshots directly within the Kubernetes ecosystem. This removes the need for external storage systems in many cases.
Longhorn also supports incremental backups and disaster recovery capabilities. This makes it easier to restore applications in case of failures or migrations without complex manual processes.
Because it integrates deeply with Kubernetes, it becomes a natural choice for running databases, stateful services, and any workload that requires persistent storage.
Fluent Bit Helm Chart
Logging is essential for understanding application behavior, and Fluent Bit is a lightweight and efficient log processor widely used in Kubernetes environments. The Fluent Bit Helm chart simplifies its deployment across clusters.
It collects logs from containers, processes them, and forwards them to external storage or analysis systems. This ensures that logs from all pods and nodes are centralized in one place for easier debugging and monitoring.
One of its main advantages is performance efficiency. Fluent Bit is designed to use minimal CPU and memory, making it suitable even for large-scale clusters with high log volumes.
It also supports filtering and transformation of logs before they are shipped. This allows teams to structure log data, remove unnecessary noise, and enrich logs with metadata.
In production systems, centralized logging is critical for troubleshooting, auditing, and security analysis, and this Helm chart provides a scalable way to achieve that.
Chaos Mesh Helm Chart
Modern distributed systems are complex, and failures are inevitable. The Chaos Mesh Helm chart introduces chaos engineering capabilities directly into Kubernetes environments, allowing teams to test system resilience under controlled failure conditions.
It enables simulation of real-world issues such as pod failures, network delays, CPU stress, and node outages. By intentionally introducing failures, teams can observe how systems behave and identify weaknesses before they occur in production.
One of its most important benefits is improved reliability. Instead of assuming systems will handle failures correctly, Chaos Mesh allows teams to validate that assumption through testing.
It also integrates with Kubernetes workloads in a declarative way, making it easy to define and schedule chaos experiments without disrupting normal operations.
This proactive approach helps organizations build more resilient systems that can withstand unexpected failures in real-world conditions.
Harbor Helm Chart
Container image management is a core part of Kubernetes workflows, and Harbor provides a secure and enterprise-grade registry for storing and managing container images. The Harbor Helm chart simplifies its deployment within Kubernetes clusters.
It offers features such as image vulnerability scanning, role-based access control, and artifact signing. These capabilities help ensure that only trusted and secure images are deployed into production environments.
One of its key strengths is security enforcement. It integrates scanning tools that detect vulnerabilities in container images before they are used in deployments. This helps reduce the risk of running insecure or outdated software.
Harbor also supports replication across multiple registries, making it suitable for multi-cluster or multi-region setups. This improves availability and consistency of container images across environments.
By centralizing image management, it becomes easier to maintain control over what runs inside Kubernetes clusters.
Enhancing Observability and Resilience in Kubernetes Systems
When combined, these Helm charts significantly improve observability, resilience, and operational control in Kubernetes environments. They extend beyond basic infrastructure management and focus on deeper system reliability and data protection.
From event tracking and logging to chaos testing and storage management, each chart plays a specific role in strengthening the overall system.
Operational Insight Through Events, Logs, and Metrics
A complete understanding of a Kubernetes system requires multiple layers of visibility. Metrics show performance, logs show detailed behavior, and events explain system actions.
Tools like Kubernetes Event Exporter and Fluent Bit ensure that no important information is lost. This layered observability approach helps teams diagnose issues faster and more accurately.
Resilience Through Testing and Storage Reliability
Resilience is not achieved by assumption but by testing and design. Chaos Mesh allows teams to simulate failures and validate system behavior under stress, while Longhorn ensures that data remains safe and accessible even during infrastructure issues.
Together, they strengthen both application and infrastructure reliability.
Security and Control Across the Supply Chain
Container security is a critical concern in modern systems. Harbor ensures that only verified and secure images are deployed, reducing the risk of vulnerabilities entering production environments.
This creates a controlled software supply chain where every component is tracked, scanned, and validated before use.
A Mature Kubernetes Ecosystem with Helm Charts
When all these Helm charts are considered together across all parts, they form a complete Kubernetes ecosystem that covers networking, security, observability, storage, deployment automation, logging, and resilience testing.
This layered structure allows organizations to operate Kubernetes at scale with confidence. Instead of manually managing complex systems, teams rely on standardized, automated, and well-integrated components.
The result is a cloud-native environment that is stable, secure, and ready for continuous growth.
Prometheus Adapter Helm Chart
In Kubernetes environments, custom metrics are often required for advanced autoscaling and monitoring scenarios. The Prometheus Adapter Helm chart enables Kubernetes to use Prometheus metrics as a source for the Horizontal Pod Autoscaler and other custom scaling mechanisms.
By default, Kubernetes relies on basic CPU and memory metrics, which are not always sufficient for modern applications. With this adapter, teams can define scaling rules based on application-specific metrics such as request rate, queue length, or response time.
This makes autoscaling much more intelligent because scaling decisions are aligned with real application behavior rather than just system resource usage. It allows workloads to respond more accurately to traffic patterns and performance demands.
Another important benefit is flexibility. Since Prometheus already collects a wide range of metrics, the adapter simply exposes them to Kubernetes in a usable format. This reduces the need for additional monitoring tools or custom scaling logic.
In production systems, this results in more efficient resource usage and improved application responsiveness under varying loads.
NGINX Subchart for Advanced Traffic Control
While basic ingress controllers handle standard routing, advanced environments often require more granular traffic control. The NGINX subchart provides extended configuration options for fine-tuning how traffic is handled within Kubernetes clusters.
It allows teams to implement features such as rate limiting, request buffering, connection throttling, and advanced load balancing strategies. These capabilities are especially useful in high-traffic systems where performance optimization is critical.
One of its key advantages is customization. Instead of relying on default routing behavior, teams can define detailed policies that control how requests are processed and distributed across services.
It also improves stability by protecting backend services from sudden traffic spikes. By applying limits and filters at the ingress level, it helps prevent system overloads and cascading failures.
In complex architectures, this level of traffic control is essential for maintaining consistent performance and reliability.
Descheduler Helm Chart
Kubernetes schedules pods based on resource availability, but over time, clusters can become unbalanced. The Descheduler Helm chart helps resolve this issue by intelligently evicting and redistributing pods to improve overall cluster efficiency.
It analyzes node utilization and identifies imbalances such as overloaded nodes or underutilized resources. Once detected, it triggers pod rescheduling to achieve better distribution across the cluster.
This improves performance by ensuring that no single node becomes a bottleneck while others remain underused. It also enhances resource efficiency, allowing clusters to operate closer to optimal capacity.
Another benefit is long-term stability. As workloads change over time, manual intervention to rebalance clusters becomes unnecessary. The descheduler automates this process, keeping the system healthy without constant human management.
In large-scale environments, this helps maintain consistent performance and reduces infrastructure waste.
Cert-Manager ACME Solver Helm Chart
While cert-manager handles certificate management, the ACME solver component specifically focuses on automating domain validation for certificate issuance. The Helm chart simplifies this process by integrating with ACME-based certificate authorities.
It enables automatic validation through HTTP or DNS challenges, ensuring that certificates are issued without manual verification steps. This is especially useful for dynamic environments where services are frequently created and destroyed.
One of its strengths is full automation of domain ownership verification. Once configured, it continuously handles certificate requests and renewals without requiring human interaction.
It also supports wildcard certificates, making it easier to secure multiple subdomains under a single configuration.
In production systems, this reduces operational complexity and ensures that all services maintain secure communication channels without delays or manual setup.
Karpenter Helm Chart
Efficient resource provisioning is essential in scalable Kubernetes environments, and Karpenter provides a modern solution for dynamic node provisioning. The Helm chart enables automatic scaling of cluster infrastructure based on workload demand.
Unlike traditional autoscalers that rely on predefined node groups, Karpenter directly provisions nodes based on real-time workload requirements. This allows clusters to scale more efficiently and reduce resource waste.
One of its key advantages is speed. It can quickly launch new nodes when demand increases, ensuring that workloads are scheduled without delay. This improves application responsiveness during traffic spikes.
It also optimizes cost by selecting the most efficient instance types based on workload needs. This helps organizations reduce infrastructure expenses while maintaining performance.
In dynamic cloud-native environments, this level of automation significantly improves scalability and operational efficiency.
Expanding Kubernetes Capabilities Through Specialized Helm Charts
These additional Helm charts extend Kubernetes beyond its core functionality and introduce advanced capabilities such as custom scaling, intelligent scheduling, and dynamic infrastructure provisioning.
Each chart addresses specific operational challenges that arise in large and complex systems.
Smarter Scaling and Resource Optimization
Traditional scaling mechanisms are often limited to CPU and memory usage, but modern applications require more intelligent approaches. Prometheus Adapter and Karpenter enable scaling based on real workload behavior and infrastructure demand.
This leads to better performance, reduced costs, and more efficient resource utilization across the cluster.
Improved Traffic Management and System Stability
Advanced traffic control using NGINX subcharts ensures that systems remain stable even under heavy load. By controlling request flow at a granular level, teams can prevent overload situations and maintain consistent performance.
This is especially important for high-traffic APIs and user-facing applications.
Automated Cluster Maintenance and Balance
The Descheduler plays a key role in maintaining long-term cluster health. By continuously balancing workloads, it ensures that infrastructure remains efficient and avoids resource fragmentation.
This reduces manual intervention and improves overall system stability.
Fully Automated Security and Certificate Management
Cert-manager and its ACME components ensure that security is fully automated. Certificates are issued, validated, and renewed without manual effort, reducing both risk and operational workload.
This guarantees that secure communication remains consistent across all services.
A Complete Advanced Kubernetes Ecosystem
When combined with previous Helm charts across all parts, these advanced tools complete a fully mature Kubernetes ecosystem. This ecosystem covers every aspect of cloud-native operations including networking, security, observability, scaling, storage, logging, and infrastructure automation.
The result is a highly efficient, self-healing, and scalable system that can adapt to changing workloads and operational demands with minimal manual intervention.
Trivy Operator Helm Chart
Security scanning is a critical requirement in modern Kubernetes environments, and the Trivy Operator Helm chart brings continuous vulnerability scanning directly into the cluster. Instead of scanning images only at build time, it continuously monitors running workloads, container images, and Kubernetes configurations for security issues.
This operator automatically detects vulnerabilities in dependencies, operating system packages, and container images. It also scans for misconfigurations that could expose the cluster to risk, such as overly permissive roles or insecure deployments.
One of its key strengths is continuous protection. As new vulnerabilities are discovered, they are flagged inside the cluster without requiring manual rescans. This ensures that security issues are identified quickly even after deployment.
It also integrates well with reporting and monitoring systems, allowing teams to track security posture over time. This makes it easier to enforce compliance requirements and maintain strong security hygiene across environments.
In production systems, this chart adds an essential layer of runtime security that complements CI/CD scanning tools.
Redis Helm Chart
Redis is one of the most widely used in-memory data stores for caching, messaging, and real-time data processing. The Redis Helm chart simplifies its deployment and management within Kubernetes clusters.
It supports multiple deployment modes including standalone, replication, and clustered setups, making it suitable for both small applications and large-scale distributed systems. This flexibility allows teams to scale Redis according to workload requirements.
One of its biggest advantages is performance optimization. Since Redis operates in memory, it provides extremely fast data access, which significantly improves application response times when used as a cache or session store.
The Helm chart also includes configuration options for persistence, high availability, and failover. This ensures that data remains available even in case of node failures or restarts.
In production environments, Redis is often a core dependency for improving system speed and reducing database load, making this chart highly valuable.
Elasticsearch Helm Chart
Log aggregation and search capabilities are essential in complex Kubernetes systems, and the Elasticsearch Helm chart provides a powerful solution for storing and analyzing large volumes of data.
It is commonly used for centralized logging, full-text search, and real-time analytics. When combined with logging agents, it can collect logs from across the entire cluster and make them searchable in a structured way.
One of its key strengths is scalability. Elasticsearch can be deployed as a distributed cluster, allowing it to handle massive amounts of data while maintaining performance and reliability.
It also supports advanced querying and analytics, making it useful for debugging, monitoring user behavior, and generating operational insights.
In production environments, it becomes a central part of observability pipelines, especially when paired with visualization tools and log collectors.
RabbitMQ Helm Chart
Message-driven architectures are common in modern distributed systems, and RabbitMQ plays a key role in enabling asynchronous communication between services. The Helm chart simplifies its deployment and management in Kubernetes.
It provides a reliable message broker that allows services to communicate without direct dependencies. This improves system decoupling and enhances scalability.
One of its main benefits is reliability in message delivery. Messages are queued and persisted until they are processed, ensuring that no data is lost even during temporary service outages.
It also supports clustering, which allows RabbitMQ to scale horizontally and handle higher message throughput. This makes it suitable for high-load systems such as event-driven applications and microservice architectures.
In production systems, it helps reduce service coupling and improves system resilience by enabling asynchronous workflows.
PostgreSQL Helm Chart
Databases are a core part of most applications, and PostgreSQL remains one of the most reliable open-source relational databases. The PostgreSQL Helm chart simplifies deployment, scaling, and management within Kubernetes.
It supports features such as replication, backups, and high availability configurations. This ensures that databases remain resilient and recoverable in case of failures.
One of its key strengths is stability. PostgreSQL is known for its strong consistency and advanced querying capabilities, making it suitable for a wide range of applications from transactional systems to analytics workloads.
The Helm chart also allows configuration of storage persistence, resource allocation, and replication strategies, giving teams full control over database behavior in the cluster.
In production environments, it serves as a dependable data layer for applications that require structured and consistent data storage.
Expanding Core Infrastructure Capabilities in Kubernetes
These Helm charts strengthen the foundational layers of Kubernetes by addressing data management, security, messaging, caching, and search capabilities. Each one plays a specific role in building a complete production-grade ecosystem.
Strengthening Security and Runtime Protection
Trivy Operator enhances security by continuously scanning workloads for vulnerabilities and misconfigurations. This ensures that security is not just a one-time step but an ongoing process throughout the application lifecycle.
It provides real-time visibility into risks, helping teams respond quickly to potential threats.
Improving Performance Through Caching and Messaging
Redis improves system performance by reducing database load and accelerating data access. RabbitMQ enhances system architecture by enabling asynchronous communication between services.
Together, they help build faster and more scalable applications.
Enabling Advanced Data Storage and Search
PostgreSQL and Elasticsearch handle structured and unstructured data at scale. PostgreSQL provides strong consistency for transactional workloads, while Elasticsearch enables fast searching and analytics over large datasets.
This combination supports both operational and analytical use cases within the same ecosystem.
Building a Fully Integrated Cloud-Native Stack
When combined with all previously discussed Helm charts, these components complete a fully integrated Kubernetes ecosystem. This ecosystem supports networking, security, observability, scaling, messaging, caching, storage, and analytics.
The result is a highly modular and scalable infrastructure that can support modern application demands with efficiency and reliability.
Conclusion
Across all these open-source Helm charts, a clear pattern emerges: modern Kubernetes environments are no longer just about running containers, but about building fully automated, secure, and self-sustaining systems. Each chart plays a specific role in strengthening a different layer of the infrastructure, from traffic management and security to observability, storage, scaling, and disaster recovery.
When these tools are used together, they eliminate much of the manual overhead that traditionally comes with cluster operations. Instead of reacting to problems, teams can rely on automation for certificate renewal, DNS updates, workload scaling, logging, and even infrastructure provisioning. This shifts the focus from maintenance to actual application development and performance improvement.
Security is strengthened as well through automated certificate management, secret synchronization, and container image scanning. These practices reduce human error and help maintain a strong security posture across the entire infrastructure.
Ultimately, these Helm charts form more than just a toolkit—they represent a complete operational philosophy for cloud-native systems. By combining automation, observability, scalability, and resilience, they enable organizations to build Kubernetes environments that are not only functional but also production-ready at scale.