Cloud computing has transformed the way businesses store and manage data. Traditional on-premises storage systems often required expensive hardware investments, ongoing maintenance, and careful planning to handle future growth. Cloud-based storage services remove much of this complexity by offering scalable, flexible, and highly available solutions that organizations can access whenever needed.
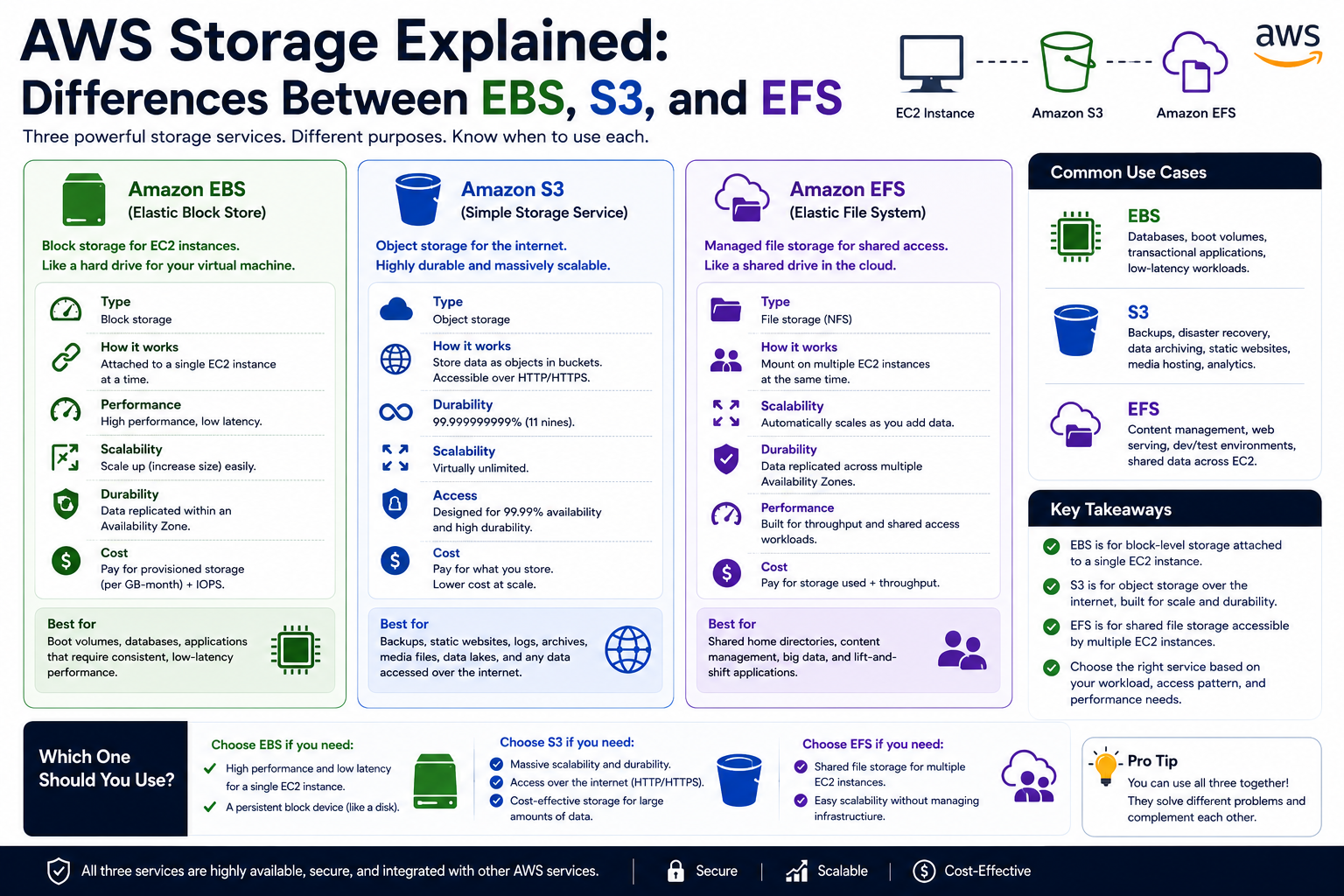
One of the most essential storage services in modern cloud infrastructure is Elastic Block Store, commonly referred to as EBS. It is often among the first storage solutions professionals encounter when beginning their journey into cloud technologies because it integrates directly with compute resources and provides persistent storage that supports operating systems, applications, and databases.
Elastic Block Store is designed around block-level storage architecture. In this approach, data is divided into fixed-size blocks, with each block stored separately but managed as part of a complete volume. This design allows applications to access and update only the specific blocks they need rather than processing entire files. As a result, performance is faster and more efficient, especially for applications that require frequent read and write operations.
Block storage has long been used in enterprise storage area networks because it delivers predictable performance and low latency. By bringing this capability into the cloud, Elastic Block Store provides organizations with familiar enterprise-grade storage while benefiting from cloud scalability and operational flexibility.
Understanding Elastic Block Store is critical because it serves as the storage backbone for many workloads, from simple development environments to enterprise production systems. It is the foundation for countless applications that require durable, reliable, and high-performance storage resources.
What Makes Elastic Block Store Important
Elastic Block Store is tightly integrated with virtual compute instances. Every time a compute resource is launched, it often requires attached storage to host the operating system and application files. Elastic Block Store fulfills this need by acting as the persistent disk attached to the instance.
Unlike temporary local storage that disappears when an instance is terminated, Elastic Block Store preserves data independently of compute resources. This persistence means data remains available even if the associated instance is stopped, restarted, or replaced.
This feature is crucial for maintaining continuity in production environments. If a server experiences failure, administrators can launch a replacement instance and attach the existing storage volume. Applications can resume operation without needing complete restoration from backup.
Persistence also supports maintenance workflows. Organizations can detach volumes for migration, perform updates on compute resources, and reattach storage afterward with minimal disruption.
This separation of storage from compute provides architectural flexibility that traditional local disk systems cannot match. Businesses can scale compute and storage independently, optimizing performance and cost according to workload requirements.
Elastic Block Store also supports rapid provisioning. Administrators can create new storage volumes in minutes, attach them to running instances, and expand storage capacity without lengthy procurement or installation processes.
These capabilities make Elastic Block Store an essential service for organizations building reliable cloud environments.
How Elastic Block Store Works
Elastic Block Store functions like a virtual hard drive. Once attached to a compute instance, the operating system recognizes it as a local storage device. Users can partition, format, and mount the volume using standard system tools.
Applications interact with the storage exactly as they would with a physical disk installed inside a traditional server. This familiar behavior makes adoption straightforward for administrators transitioning from on-premises systems.
Storage volumes can be created with different sizes and performance characteristics depending on workload requirements. Once provisioned, they are attached to compute resources through the cloud management platform.
The storage remains independent of the instance lifecycle. If the compute instance is terminated, administrators can choose whether the volume is deleted or preserved for later use.
This flexibility supports a wide range of operational workflows.
For example, a software development team may preserve volumes containing testing environments while replacing compute instances frequently. Production systems may retain storage volumes for compliance and recovery requirements.
Elastic Block Store also supports resizing. As applications grow, administrators can expand volume capacity without rebuilding systems from scratch.
This dynamic scaling allows infrastructure to evolve alongside business needs while minimizing downtime.
Performance and Volume Types
Elastic Block Store offers multiple storage configurations designed for different performance profiles.
General-purpose solid-state volumes balance cost and performance for everyday workloads. These are ideal for web servers, application hosting, and moderate database use.
Provisioned performance solid-state volumes deliver guaranteed input and output operations for demanding enterprise applications. Databases processing thousands of transactions per second often rely on these configurations for consistent responsiveness.
Throughput-optimized hard disk volumes focus on large sequential workloads rather than low latency. They are well suited for data warehousing, streaming systems, and analytics processing.
Cold hard disk options provide lower-cost storage for infrequently accessed data.
Selecting the right volume type requires understanding workload characteristics.
Applications with frequent random access patterns benefit from solid-state performance.
Workloads processing large continuous data streams often achieve better value from throughput-focused storage.
Performance tuning is another major advantage.
Administrators can adjust storage parameters based on changing demand, ensuring resources remain aligned with operational requirements.
Monitoring tools provide visibility into latency, throughput, and utilization metrics, helping teams optimize performance over time.
This adaptability allows Elastic Block Store to support both small development environments and large-scale enterprise deployments.
Data Durability and Reliability
Reliability is one of the most important features of Elastic Block Store.
Data is automatically replicated within a single availability zone to protect against hardware failure. If one physical storage component experiences issues, replicated copies maintain accessibility and integrity.
This redundancy provides extremely high durability.
Applications relying on Elastic Block Store can operate with confidence that hardware failures are unlikely to result in data loss.
The service is engineered to maintain consistent performance even during underlying infrastructure maintenance.
Snapshots further enhance durability.
A snapshot captures the exact state of a storage volume at a specific point in time. These backups can be used for recovery, cloning environments, or migration.
Snapshots are stored separately from the active volume, adding another layer of protection.
Organizations often automate snapshot creation as part of disaster recovery planning.
This ensures recoverable copies are always available in case of accidental deletion, corruption, or operational failure.
Combined with replication, snapshots create a comprehensive resilience strategy suitable for mission-critical workloads.
Security and Access Control
Security is deeply integrated into Elastic Block Store.
Storage volumes can be encrypted to protect data at rest. Encryption ensures unauthorized users cannot access stored information even if physical infrastructure is compromised.
Encryption keys are managed centrally, allowing organizations to enforce consistent security policies.
Data moving between storage and compute resources can also be protected during transmission.
Access permissions control which users and systems can create, modify, attach, or delete volumes.
These controls are managed through identity-based access policies that align with organizational governance requirements.
Detailed audit logs record storage-related actions.
This visibility supports compliance initiatives and helps security teams investigate suspicious activity.
Organizations handling regulated or sensitive information often depend on these capabilities to meet legal and operational requirements.
The combination of encryption, identity management, and auditability makes Elastic Block Store suitable for secure enterprise deployments.
Practical Business Use Cases
Elastic Block Store supports a wide range of real-world workloads.
Database systems are among the most common use cases because they require low-latency transactional storage.
Relational database platforms depend on fast, predictable disk performance to process queries efficiently.
Application hosting environments use Elastic Block Store for persistent configuration files, software packages, and runtime storage.
Development and testing teams use snapshots to create repeatable environments quickly.
Disaster recovery systems rely on snapshots and detachable volumes for fast restoration during outages.
Analytics platforms processing structured transactional data benefit from provisioned performance configurations.
Enterprise software systems often require storage that behaves like traditional local disks while providing cloud flexibility.
Elastic Block Store delivers this balance effectively.
Its versatility makes it valuable across industries ranging from finance and healthcare to software development and manufacturing.
Challenges and Limitations
Despite its strengths, Elastic Block Store is not ideal for every scenario.
Volumes are generally tied to a single availability zone, which requires planning for cross-zone resilience.
Capacity limits exist per volume, so very large workloads may require multiple volumes combined through operating system tools.
Multi-instance attachment is limited to specific configurations, restricting shared-access use cases.
Management overhead is another consideration.
Administrators must choose volume sizes, monitor utilization, plan backups, and optimize performance settings.
Improper provisioning can increase costs unnecessarily.
High-performance configurations are more expensive, and unused capacity still incurs charges.
Understanding workload requirements is essential to balancing performance and budget.
Elastic Block Store works best when organizations carefully align storage design with operational needs.
Why Elastic Block Store Matters
Elastic Block Store represents a critical foundation for cloud infrastructure.
It provides the persistent storage layer required for stable, reliable compute operations.
Its enterprise-grade performance, durability, and flexibility make it ideal for production workloads that cannot tolerate interruption or inconsistency.
For organizations modernizing infrastructure, Elastic Block Store offers familiar disk-based storage behavior while introducing cloud scalability and automation.
It bridges traditional storage concepts with modern cloud-native architecture.
Mastering Elastic Block Store is often the first step toward understanding broader cloud storage strategies.
Its capabilities enable everything from simple development systems to large-scale enterprise applications.
As cloud environments continue evolving, Elastic Block Store remains one of the most essential storage technologies for building dependable and scalable infrastructure.
Introduction to Object Storage
As cloud computing has evolved, the need for scalable and cost-effective storage solutions has become more important than ever. Organizations now handle enormous amounts of unstructured data every day, including images, videos, backups, website assets, machine learning datasets, documents, and application logs. Traditional storage methods often struggle to handle this kind of large-scale growth efficiently.
Object storage was developed to solve this challenge. Unlike block storage, which divides data into blocks, object storage treats every file as a complete object. Each object contains the file itself, metadata describing the file, and a unique identifier that allows retrieval from anywhere within the storage environment.
This structure makes object storage highly scalable and ideal for modern distributed systems. It allows organizations to store and retrieve virtually unlimited amounts of data without the limitations commonly associated with traditional storage architectures.
Amazon Simple Storage Service, often known as S3, is one of the most widely used object storage services in cloud computing. It provides highly durable, scalable, secure, and flexible storage for businesses of every size.
Amazon S3 is considered a foundational service because it supports a wide range of workloads, from static website hosting to enterprise backup solutions and large-scale analytics pipelines.
Understanding how Amazon S3 works is essential for anyone learning cloud architecture because it plays a central role in modern infrastructure design.
What Makes Amazon S3 Different
Amazon S3 differs significantly from block-based storage systems.
Instead of attaching storage directly to virtual machines, S3 stores data independently inside containers called buckets.
A bucket acts as a logical storage container where users place objects. Each object can contain nearly any type of file, including images, videos, compressed archives, application data, software packages, and documents.
Because S3 stores data independently from compute resources, it can be accessed from virtually anywhere using network-based requests.
Applications retrieve files through secure application programming interfaces rather than mounting storage as a local disk.
This design makes S3 highly flexible.
Multiple applications, users, and systems can access the same stored data simultaneously.
It also supports massive scalability because objects are distributed automatically across underlying infrastructure without requiring manual management.
There is no need to provision capacity in advance.
Storage grows automatically as new data is added and shrinks when data is deleted.
This elasticity removes the complexity of forecasting storage requirements and ensures businesses only pay for what they use.
These characteristics make Amazon S3 an ideal solution for organizations needing scalable and globally accessible storage.
How Amazon S3 Works
Amazon S3 operates using buckets and objects.
A bucket is created first and serves as the top-level storage container.
Inside the bucket, users upload objects.
Each object includes the file data itself along with metadata that describes properties such as content type, permissions, encryption settings, and modification timestamps.
Every object is assigned a unique key that identifies it within the bucket.
Applications retrieve objects by referencing the bucket name and object key.
Because retrieval occurs through secure network requests, applications can access data from virtually any location with proper authorization.
Buckets can also be configured with policies that define who can upload, download, or delete objects.
This access control supports secure collaboration across applications and teams.
The flat structure of S3 differs from traditional file systems.
Although folder-like organization can be simulated using naming conventions, objects are stored without hierarchical directory dependencies.
This design improves scalability and simplifies distributed storage management.
It allows S3 to manage enormous datasets efficiently while maintaining fast retrieval performance.
Storage Scalability and Capacity
One of the greatest strengths of Amazon S3 is virtually unlimited scalability.
Traditional storage systems often require hardware expansion planning.
Organizations must estimate future growth and purchase additional storage before capacity runs out.
Amazon S3 removes this challenge completely.
Storage expands automatically as data grows.
There are no practical capacity limits for most workloads.
Businesses can begin with small datasets and scale into petabytes without changing architecture.
This elasticity supports innovation by allowing teams to experiment without infrastructure constraints.
Startups can launch services without expensive storage planning.
Large enterprises can scale globally without redesigning applications.
S3 also supports parallel access across distributed systems.
Thousands of applications and users can retrieve objects simultaneously without performance bottlenecks common in traditional file servers.
This makes it ideal for cloud-native applications serving large audiences.
The ability to scale instantly and globally is one reason S3 has become a standard for cloud storage.
Durability and Data Protection
Durability is one of Amazon S3’s most valuable features.
Stored objects are automatically replicated across multiple devices within a region.
This redundancy protects data from hardware failures and ensures long-term preservation.
The durability design is engineered to minimize the likelihood of data loss.
This makes S3 suitable for mission-critical business data, backups, and archives.
Versioning adds another layer of protection.
When enabled, every modification creates a new object version rather than replacing the previous one.
If data is accidentally overwritten or deleted, earlier versions can be restored easily.
Cross-region replication provides additional resilience.
Objects can be copied automatically to geographically separate regions.
This protects against regional outages and supports disaster recovery planning.
Lifecycle policies automate long-term protection.
Older objects can move automatically to lower-cost archival storage classes based on predefined rules.
This ensures important data remains protected while optimizing cost efficiency.
Together, these durability mechanisms make Amazon S3 one of the most reliable cloud storage services available.
Storage Classes and Cost Optimization
Amazon S3 offers multiple storage classes to balance performance and cost.
Frequently accessed data benefits from standard storage classes optimized for low-latency retrieval.
Data with unpredictable access patterns works well with intelligent tiering.
This option automatically moves objects between performance tiers based on usage behavior.
Infrequently accessed data can be stored at lower cost while remaining quickly retrievable.
Archival storage classes provide even lower pricing for long-term retention.
These classes are ideal for compliance records, historical backups, and data that rarely requires immediate access.
Deep archival options offer the lowest storage cost but may require hours for retrieval.
Lifecycle management policies automate movement between classes.
Organizations define rules based on object age or access frequency.
This automation reduces administrative effort and ensures cost efficiency.
Choosing the correct storage class is critical for optimizing cloud spending.
Businesses storing large volumes of inactive data often achieve substantial savings through lifecycle automation.
These flexible pricing options make S3 practical for nearly every storage scenario.
Security Features
Security is deeply integrated into Amazon S3.
Access control policies determine who can view, modify, or delete stored objects.
Permissions can be assigned to individual users, applications, or entire services.
Encryption protects data both at rest and during transfer.
Organizations can use provider-managed encryption or control their own encryption keys for stricter governance.
Bucket policies provide centralized access enforcement.
These policies define precise conditions for object access.
Public access can also be blocked entirely to prevent accidental exposure.
Logging and monitoring capabilities track storage activity in detail.
Security teams can review access attempts, identify unusual behavior, and investigate incidents quickly.
Object locking supports compliance requirements.
Data can be made immutable for a specified retention period, preventing deletion or modification.
This is valuable for regulated industries requiring strict preservation controls.
These layered security controls allow organizations to store sensitive information confidently.
Real-World Use Cases
Amazon S3 supports an enormous variety of workloads.
Backup and disaster recovery are among the most common.
Organizations store system backups securely and retrieve them when needed.
Static website hosting is another major use case.
Websites containing HTML, images, scripts, and media files can be served directly from storage buckets.
Application asset storage is widespread.
Software platforms store uploaded files such as user photos, videos, and documents inside S3.
Big data analytics platforms use S3 as a data lake.
Massive datasets are stored centrally for processing by analytics engines.
Machine learning workflows rely heavily on S3 for training data storage and model output preservation.
Media streaming services store and distribute audio and video content globally.
Log aggregation systems collect operational data for analysis and troubleshooting.
These use cases demonstrate Amazon S3’s extraordinary flexibility.
Its ability to support diverse workloads makes it one of the most widely adopted cloud services.
Limitations and Considerations
Despite its advantages, Amazon S3 has limitations.
It is not designed as a traditional file system.
Applications requiring direct file locking or low-latency random disk access may not perform well.
Object retrieval involves network requests rather than local disk operations.
This introduces latency unsuitable for transactional databases.
Large archival retrievals may take time depending on storage class.
Immediate access is not guaranteed for deep archive tiers.
The flat namespace can complicate organization if naming conventions are inconsistent.
Careful planning is necessary for large-scale bucket management.
Access policies can become complex in enterprise environments.
Improper configuration may create security risks.
Understanding these limitations ensures organizations apply S3 appropriately.
It works best for scalable object-based workloads rather than disk-intensive applications.
Why Amazon S3 Matters
Amazon S3 transformed cloud storage by proving that highly scalable object storage could be reliable, secure, and affordable.
Its flexibility supports everything from startup applications to enterprise-scale analytics systems.
It eliminates infrastructure constraints and enables organizations to focus on innovation instead of storage management.
By combining scalability, durability, cost optimization, and security, Amazon S3 has become a cornerstone of modern cloud architecture.
Learning how it works is essential for anyone building cloud-native systems.
Its principles influence storage design across the industry and continue shaping the future of data management.
For businesses seeking scalable and resilient storage for modern workloads, Amazon S3 remains one of the most powerful solutions available.
Introduction to Shared File Storage in the Cloud
Modern organizations depend heavily on storage systems that allow multiple users, servers, and applications to access shared data efficiently. In traditional business environments, this need has often been addressed through network-attached storage systems that provide centralized file access across local infrastructure. As businesses move to the cloud, they require file storage solutions that deliver the same convenience while adding scalability, resilience, and operational simplicity.
Amazon Elastic File System, commonly known as EFS, is designed to fulfill this requirement. It is a fully managed cloud file storage service that provides scalable shared access for compute resources. Unlike block storage, which is attached to individual compute instances, Elastic File System can be mounted simultaneously by many instances across distributed environments.
This makes it ideal for workloads that require collaboration, shared access, and consistent data availability across multiple servers.
Elastic File System is based on a familiar file system structure. Users interact with directories, subdirectories, and files much like they would on traditional Linux-based systems. This familiarity simplifies adoption for administrators and developers transitioning from on-premises infrastructure.
Because the service is fully managed, organizations do not need to provision storage hardware, configure replication, patch software, or manage file server infrastructure. The platform automatically handles scaling, availability, and maintenance.
Elastic File System combines traditional shared file system behavior with the flexibility and elasticity of modern cloud infrastructure, making it an essential option for organizations requiring scalable collaborative storage.
What Makes Elastic File System Unique
Elastic File System stands apart from other cloud storage services because it provides a shared hierarchical file system that multiple compute resources can access simultaneously.
Unlike block storage, which generally supports one attached instance at a time, Elastic File System allows concurrent access across many compute resources.
Unlike object storage, which stores data as independent objects retrieved through application programming interfaces, Elastic File System behaves like a standard mounted file system.
Applications can read, write, modify, and organize files using traditional file operations.
This makes Elastic File System especially valuable for workloads that depend on shared file access patterns.
Applications designed for local file systems can often migrate to Elastic File System with minimal modification.
Its support for standard file system semantics simplifies software compatibility.
Elastic File System also scales automatically.
As files are added, capacity grows seamlessly.
As files are removed, capacity shrinks automatically.
Organizations do not need to predict future storage requirements or manually provision additional capacity.
This elasticity reduces operational complexity and ensures businesses pay only for the storage they actively use.
These characteristics make Elastic File System ideal for collaborative applications, distributed processing systems, and environments requiring persistent shared access.
How Elastic File System Works
Elastic File System is mounted over a network connection onto compute resources.
Once mounted, it appears to applications as part of the local file system.
Users interact with directories and files exactly as they would with standard Linux storage.
Behind the scenes, Elastic File System manages distribution, redundancy, scaling, and availability automatically.
It spans multiple availability zones to ensure resilience.
If one infrastructure component experiences failure, the service remains accessible through replicated resources.
This multi-zone architecture supports high availability without requiring customer-managed replication.
Applications continue operating even during infrastructure maintenance or hardware disruptions.
Elastic File System uses network-based access protocols compatible with widely used operating systems.
This allows easy integration with cloud-native applications and enterprise workloads.
Mount targets enable compute resources to connect securely from different network segments.
Access permissions can be controlled using security policies and identity-based authorization.
This flexibility supports both tightly controlled enterprise environments and dynamic cloud-native architectures.
The fully managed design removes traditional file server administration burdens.
Organizations focus on application development rather than storage infrastructure maintenance.
Performance Characteristics
Elastic File System is designed to deliver scalable performance that grows alongside storage usage.
As file system size increases, throughput capacity often increases automatically.
This relationship allows larger workloads to achieve higher aggregate performance without manual tuning.
Bursting capabilities support temporary performance spikes for workloads requiring short periods of elevated throughput.
Provisioned performance options allow organizations to specify guaranteed throughput independent of storage size.
This is useful for workloads demanding consistent responsiveness regardless of capacity utilization.
Elastic File System is optimized for high levels of parallel access.
Many compute resources can read and write simultaneously without the contention commonly seen in traditional file servers.
This supports distributed application architectures.
Latency is generally higher than direct-attached block storage because access occurs over network protocols.
As a result, Elastic File System is less suitable for workloads requiring extremely low-latency disk operations.
However, for collaborative and shared-access workloads, its scalability and concurrency advantages outweigh this limitation.
Performance modes allow optimization for specific access patterns.
Organizations can select configurations that prioritize low latency or maximum throughput depending on workload requirements.
This flexibility ensures Elastic File System can support diverse enterprise use cases.
Automatic Scalability and Storage Management
One of the most attractive features of Elastic File System is automatic scaling.
Traditional file storage often requires careful capacity planning.
Administrators must estimate growth, purchase storage hardware, and provision capacity before it is needed.
Elastic File System eliminates this challenge.
Storage expands automatically as data is written.
Unused capacity is released when files are deleted.
This dynamic adjustment ensures efficient resource utilization.
Organizations avoid overprovisioning while maintaining confidence that storage will never run out unexpectedly.
Automatic scaling is especially valuable for unpredictable workloads.
Applications experiencing rapid growth can continue operating without interruption.
Seasonal usage spikes are accommodated seamlessly.
Development teams can deploy applications without complex storage forecasting.
Operational overhead is significantly reduced.
Administrators no longer spend time resizing volumes or migrating file systems to larger hardware.
This simplicity allows teams to focus on delivering business value rather than managing storage infrastructure.
Elastic File System provides true cloud-native elasticity for shared file storage.
Storage Classes and Lifecycle Management
Elastic File System supports multiple storage classes to balance cost and accessibility.
Frequently accessed files remain in primary storage for immediate retrieval.
Infrequently accessed files can transition automatically to lower-cost storage classes.
Lifecycle policies control this movement based on file inactivity periods.
Older files move to lower-cost storage without manual intervention.
If accessed again, they can return automatically to higher-performance storage.
This automation optimizes cost efficiency while preserving seamless application access.
Organizations with mixed usage patterns benefit significantly.
Active project files remain instantly available.
Historical records consume less expensive storage until needed.
Lifecycle automation reduces administrative effort and supports long-term retention strategies.
This flexibility makes Elastic File System practical for workloads ranging from active collaboration to archival content management.
Security and Access Control
Security is deeply integrated into Elastic File System.
Network-level access restrictions control which compute resources can mount the file system.
Identity-based permissions determine who can create, modify, or delete file systems.
Encryption protects stored data automatically.
Encryption in transit secures network communication between compute resources and storage endpoints.
Access points provide fine-grained file system entry controls.
Applications can mount restricted views with specific directory permissions.
This improves multi-tenant security and simplifies application isolation.
Audit logging tracks file system activity for compliance and troubleshooting.
These controls support enterprise governance requirements.
Organizations handling regulated data can enforce strict protection policies confidently.
Combined with network segmentation and centralized identity management, Elastic File System provides strong security for shared workloads.
Practical Use Cases
Elastic File System supports many collaborative and distributed workloads.
Content management systems often depend on shared file storage for media assets and templates.
Web server clusters use Elastic File System to share application files consistently across instances.
Software development environments store shared code repositories and build artifacts.
Container orchestration platforms use Elastic File System for persistent shared storage across distributed containers.
Machine learning pipelines store training datasets accessible by multiple compute nodes.
Analytics systems process shared datasets collaboratively.
Home directory hosting is another common use case.
Users can access consistent personal storage across multiple sessions and systems.
Media production workflows benefit from centralized access to large project files.
These use cases demonstrate Elastic File System’s versatility for modern cloud-native collaboration.
Limitations and Considerations
Elastic File System is not ideal for every workload.
Latency is generally higher than block storage.
Applications requiring direct disk-level performance may perform better elsewhere.
Costs can exceed block storage for certain high-capacity workloads.
Because pricing depends on usage and performance patterns, organizations should monitor expenses carefully.
Workloads requiring object-based scalability may achieve better efficiency with object storage.
Performance scaling tied to file system size may require provisioned throughput for smaller but intensive workloads.
Application compatibility should also be verified.
Although Linux-native workloads integrate easily, some software designed for alternative file systems may require adaptation.
Understanding these considerations ensures appropriate architecture decisions.
Introduction to Amazon Elastic File System
As cloud environments continue to evolve, organizations need storage solutions that can support multiple applications and users simultaneously while remaining scalable, secure, and simple to manage. While some workloads require direct-attached block storage and others depend on object-based repositories, many applications need a shared file system that behaves much like traditional network storage used in physical data centers.
Amazon Elastic File System, commonly called EFS, is designed specifically for this purpose. It is a fully managed, cloud-native file storage service that enables multiple compute resources to access the same files at the same time. It provides a familiar hierarchical file structure, allowing users to organize data using directories and subdirectories in a way that resembles standard Linux-based file systems.
This service eliminates many of the complexities associated with maintaining traditional file servers. There is no need to purchase hardware, configure RAID arrays, plan capacity growth, or perform manual replication. The system automatically handles these tasks behind the scenes, allowing organizations to focus on their applications rather than storage infrastructure.
Elastic File System is especially valuable for workloads that require collaboration across distributed systems. Applications running across multiple compute resources can access shared files consistently, ensuring data synchronization without requiring complex custom solutions.
As businesses increasingly move toward distributed cloud-native architectures, understanding Elastic File System becomes essential for designing efficient and resilient systems.
Understanding Shared File Storage
To understand Elastic File System, it helps to understand the concept of shared file storage.
Traditional local storage is attached directly to a single server. While this provides fast access, it limits collaboration because only that server can use the storage directly.
Shared file storage solves this problem by allowing multiple systems to connect to a centralized file repository. This allows files to be accessed, modified, and stored collaboratively.
For example, a web application running on several servers may need access to shared configuration files, templates, uploaded media, or cached data. If each server had isolated local storage, keeping files synchronized would be difficult.
Shared file systems eliminate this challenge by ensuring every server interacts with the same data source.
Elastic File System provides this capability as a managed cloud service.
Applications mount the file system across network connections, allowing all connected systems to access files as if they were stored locally.
This creates a familiar and seamless experience for developers while delivering the scalability and resilience benefits of cloud infrastructure.
Because it supports standard file system operations, many legacy applications can migrate with little modification.
This compatibility simplifies cloud adoption for businesses modernizing older systems.
How Amazon Elastic File System Works
Elastic File System operates as a network-accessible file system that can be mounted by compute resources.
Once mounted, the file system appears within the operating system as a standard directory structure.
Applications can read files, write new data, modify directories, and perform file operations exactly as they would with local disk storage.
Behind the scenes, Elastic File System distributes data automatically across multiple storage resources.
This distribution improves durability and availability while allowing seamless scalability.
Unlike manually managed file servers, administrators do not need to configure replication or monitor hardware utilization.
The service automatically adjusts as files are added or removed.
Storage expands when applications write more data and contracts when files are deleted.
This elasticity ensures organizations never need to provision fixed storage capacity in advance.
Multiple compute resources can mount the same file system simultaneously.
This allows horizontally scaled applications to share common data without synchronization overhead.
This capability is essential for distributed applications, containerized workloads, and collaborative processing systems.
Because Elastic File System is fully managed, maintenance tasks such as patching, updates, and fault recovery are handled automatically.
This significantly reduces operational complexity.
Automatic Scaling Benefits
One of Elastic File System’s most powerful advantages is its ability to scale automatically.
Traditional storage systems often require capacity planning months or years in advance.
Administrators must estimate future growth and allocate resources accordingly.
If storage needs exceed predictions, costly upgrades and migrations may be required.
Elastic File System removes this burden entirely.
Storage capacity grows dynamically as needed.
There is no fixed volume size and no manual resizing process.
Applications simply write data, and the system expands automatically.
This flexibility supports unpredictable workloads.
For example, a content management platform experiencing rapid growth can continue accepting uploads without requiring storage redesign.
A development environment supporting multiple teams can scale seamlessly as projects expand.
When unused files are deleted, consumed storage decreases accordingly.
This ensures organizations pay only for actual usage.
Automatic scaling reduces waste while maintaining unlimited growth potential.
This elasticity is one of the defining characteristics that make cloud-native storage superior to traditional infrastructure.
Performance Architecture
Elastic File System is designed to provide scalable performance for distributed access patterns.
Performance scales with storage size.
Larger file systems generally support greater throughput automatically.
This relationship allows growing applications to benefit from increased performance as data volume expands.
Burst capabilities allow workloads to exceed baseline throughput temporarily during activity spikes.
This supports applications with unpredictable demand patterns.
Provisioned throughput options allow organizations to specify consistent performance levels regardless of storage size.
This is useful for workloads requiring predictable responsiveness.
Elastic File System is optimized for concurrent access across many clients.
Multiple compute resources can perform file operations simultaneously without major performance degradation.
This makes it ideal for clustered applications and parallel processing environments.
Latency is typically higher than directly attached block storage because file operations occur across network protocols.
For applications requiring ultra-low latency transactional performance, block storage may be more appropriate.
However, for collaborative and shared workloads, Elastic File System provides excellent balance between accessibility and performance.
Its scalability ensures reliable service even as workloads grow significantly.
Storage Classes and Lifecycle Management
Elastic File System offers multiple storage classes to optimize costs.
Frequently accessed files remain in high-performance storage.
Files that are rarely accessed can move automatically to lower-cost storage classes.
Lifecycle management policies control this process.
Organizations define inactivity thresholds that determine when files transition to more economical storage.
This happens automatically without manual intervention.
If an archived file becomes active again, it can return to higher-performance storage transparently.
Applications continue accessing files normally regardless of storage class transitions.
This automation simplifies long-term cost management.
Businesses with large inactive datasets benefit significantly.
Historical records, completed projects, and archived content can remain available at lower cost while preserving accessibility.
Lifecycle policies ensure efficient resource usage while minimizing operational effort.
This makes Elastic File System practical for workloads with mixed access patterns.
Security and Compliance Features
Security is critical for shared file storage.
Elastic File System includes multiple layers of protection.
Encryption at rest protects stored files from unauthorized access.
Encryption in transit secures network communication between compute resources and storage endpoints.
Access permissions control which systems can mount the file system.
Identity-based authorization determines who can create, modify, or delete resources.
Access points provide fine-grained directory restrictions.
Applications can mount isolated sections of the file system with limited permissions.
This improves security in multi-application environments.
Audit logging captures administrative activity for compliance monitoring and forensic investigation.
These capabilities support regulatory requirements across industries such as healthcare, finance, and government.
By combining encryption, authorization controls, and visibility into system activity, Elastic File System provides enterprise-grade security for sensitive workloads.
Real-World Business Applications
Elastic File System supports many practical business workloads.
Content management systems use shared storage for templates, images, and uploaded files.
Web server clusters rely on shared access to maintain consistent application state.
Software development environments store source code repositories and build artifacts.
Container orchestration platforms use Elastic File System for persistent shared storage across distributed containers.
Machine learning workflows store training datasets accessible to multiple processing nodes.
Media production teams collaborate on shared project files.
Analytics systems process centralized datasets across parallel compute resources.
Home directory hosting is another common scenario.
Users can access personal files consistently across multiple sessions and devices.
These examples highlight Elastic File System’s flexibility for collaborative cloud-native workloads.
Its compatibility with standard file operations makes adoption straightforward across industries.
Limitations and Design Considerations
Elastic File System is not ideal for every use case.
Network-based access introduces latency higher than local block storage.
Applications requiring direct disk-level transactional performance may perform better with block storage.
Costs can increase for large, heavily accessed file systems.
Organizations should monitor usage carefully to ensure efficient spending.
Performance scaling tied to storage size may require provisioned throughput for smaller but performance-intensive workloads.
Compatibility is strongest with Linux-based environments.
Applications designed for different file system architectures may require adaptation.
Careful workload analysis is essential when selecting storage services.
Understanding strengths and limitations ensures the Elastic File System is deployed effectively.
Conclusion
Amazon Elastic File System provides a powerful shared storage solution for cloud environments that require collaboration, scalability, and operational simplicity.
Its familiar file system structure makes migration straightforward for traditional applications while delivering the elasticity and resilience of cloud-native infrastructure.
Automatic scaling removes capacity planning complexity.
Lifecycle management optimizes long-term costs.
Built-in security protects sensitive information effectively.
Its ability to support simultaneous multi-instance access makes it ideal for distributed applications, collaborative development environments, content platforms, analytics systems, and containerized workloads.
While it may not replace block storage for ultra-low-latency applications or object storage for large archival repositories, it fills a critical role wherever shared file access is required.
Understanding Elastic File System is essential for designing modern cloud architectures.
It bridges the gap between traditional network file systems and next-generation cloud infrastructure, enabling organizations to build scalable, resilient, and efficient applications for the future.